伪装目标检测的算术不确定性建模
Modeling Aleatoric Uncertainty for Camouflaged Object Detection
伪装目标检测的算术不确定性建模
2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)
code:https://github.com/Carlisle-Liu/OCENet
背景
伪装对象检测,目标存在伪装性的分割
任意的不确定性捕获了观测中的噪声。对于伪装对象检测,由于伪装的前景和背景的外观相似,很难获得高精度的注释,尤其是对象边界周围的注释。我们认为,直接使用“嘈杂”的伪装图进行训练可能会导致模型的泛化能力较差。在本文中,我们引入了一种显式任意不确定性估计技术来表示由噪声标记引起的预测不确定性。具体而言,我们提出了一种置信度感知伪装目标检测(COD)框架,该框架使用动态监督来生成准确的伪装图和可靠的“任意不确定性”。与现有的根据点估计管道产生确定性预测的技术不同,我们的框架将任意不确定性形式化为模型输出和输入图像上的概率分布。我们声称,一旦经过训练,我们的置信度估计网络就可以在不依赖地面实况伪装图的情况下评估预测的像素精度。大量结果表明,该模型在解释伪装预测方面具有优越的性能。

贡献
- 1)提出了一种创新的在线置信度估计网络(OCENet)来对伪装物体检测的任意不确定性进行建模。它输出像素级的不确定性,揭示真阴性和假阳性预测,以防止网络变得过于自信;
- 2) 我们的OCENet提供了对预测的初步评估,而不依赖于地面实况;
- 3) 我们进一步提出了一种困难感知学习伪装目标检测框架,以有效地利用任意不确定性进行硬负挖掘。实验结果表明,我们的模型在解释模型预测方面具有优越的性能。
提出了一种创新的在线置信度估计网络(OCNet)来对伪装目标检测中的任意不确定性进行建模。我们动态地导出预测和地面实况之间的差异,作为OCENet中不确定性估计模块的监督。通过这种设置,我们的OCENet能够将错误分类的区域识别为不确定区域,并将低不确定性值分配给正确预测的区域。估计的置信度图能够将高不确定性分配给欠分割、过分割、伪前景预测远离目标对象的幻影分割,以及容易发生错误的对象边界。
实验
数据集:使用COD10K训练集[13]训练我们的模型,并在四个伪装物体检测测试集上进行测试,包括CAMO[28]、CHAELEON[45]、COD10K测试数据集[13]和NC4K数据集[33]。

只以初始预测作为输出来训练伪装对象检测网络,并将其表示为“M1”
将整体注意力模块添加到“M1”中,得到“M2”
置信度估计网络的监督:与[ 20、39 ]类似,置信度估计模块生成监督的另一个选项是对预测赋值为0,对跟随对抗学习管道的真值图赋值为1。我们执行了这个实验2,并在表2中显示其结果为’ M3 '。

方法
- 引入了一个相互监督的伪装目标检测学习框架来直接对任意不确定性进行建模。我们的框架中包括两个主要模块,即用于生成伪装图的伪装目标检测网络(CODNet)和用于显式估计当前预测中的任意不确定性的在线置信度估计网络(OCNet)
- 动态置信度监督是根据COD网络和地面实况伪装图的预测结果得出的。置信度估计网络的输出用于引导COD网络通过不确定性引导的结构损失来专注于学习具有低置信度的图像部分。
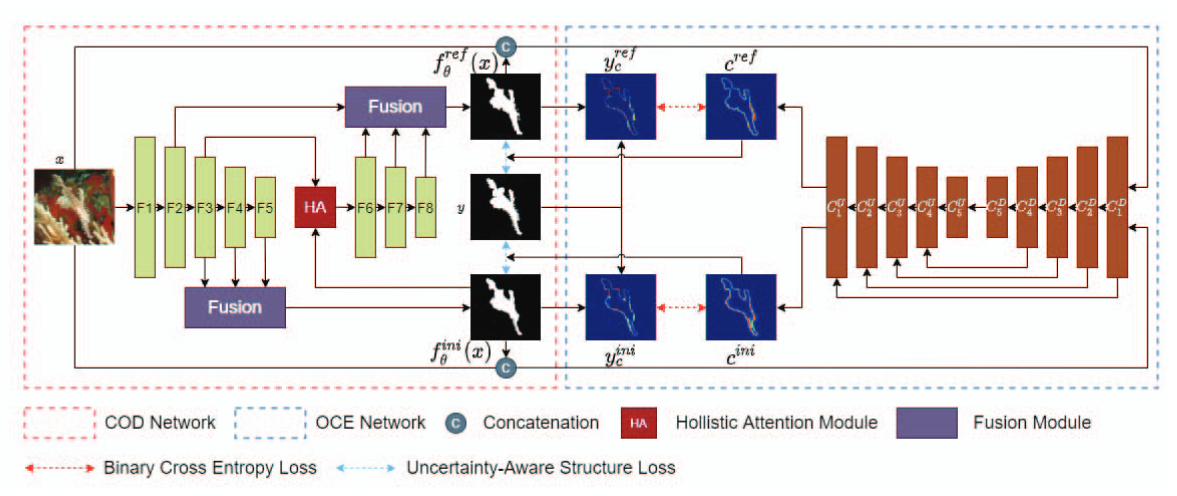
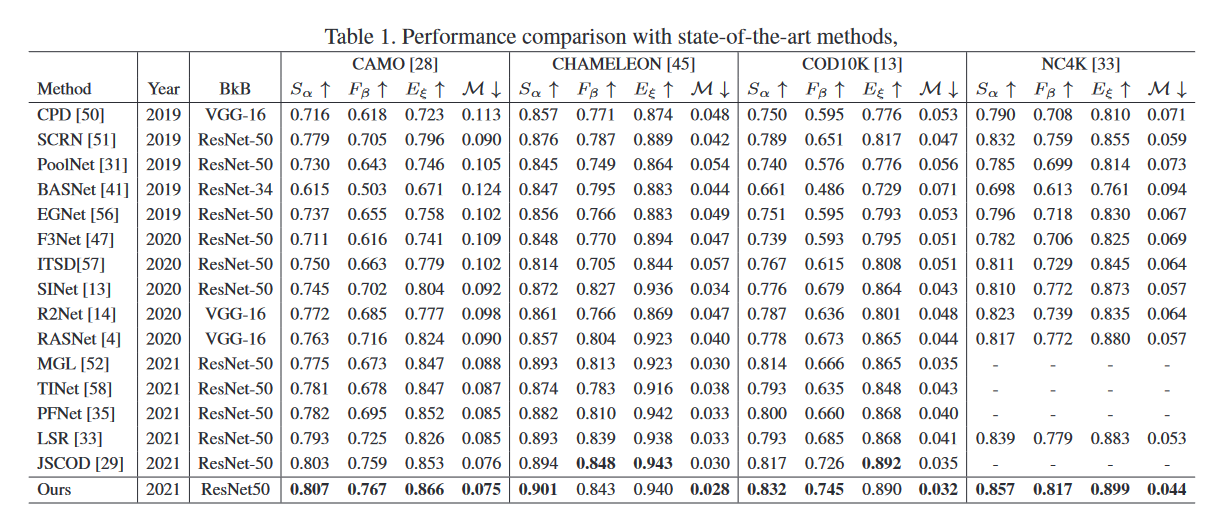
Camouflaged Object Detection Network(伪装目标检测框架)
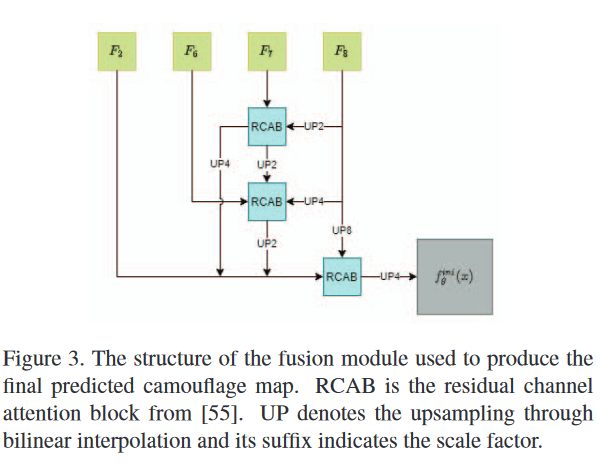
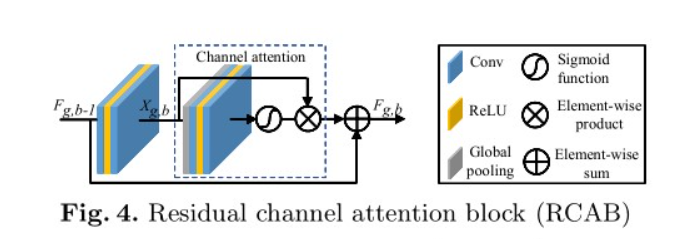
- 提出了一种融合模块(FM)来组合不同级别的特征图。逐渐将高级特征与低级特征融合。在每个融合操作中,都包括最高级别的特征以提供语义指导。RCAB来自*[mage super-resolution using very deep residual channel attention networks. In Eur. Conf. Comput. Vis., pages 286–301, 2018.]*
- 相对低级的特征图F2提供更多的空间信息,这对于分割任务恢复更清晰的结构是重要的。
Online Confidence Estimation Network(在线置信度估计网络)
CODNet将模型预测(Dir yini和Dir yref)和图像x的级联作为输入,以产生单通道置信度图,以及最终预测的cref,通过从伪装目标检测网络fθ(x)和地面实况伪装图y的预测导出的动态不确定性监督来监督估计的置信图。

Dynamic Uncertainty Supervision(动态不确定性监督)
使用预测和基本事实之间的差异作为明确的监督来对任意不确定性进行建模。在我们的工作中,它代表了以输入图像为条件的预测的不确定性。
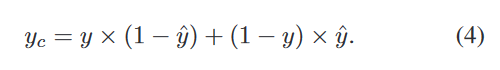
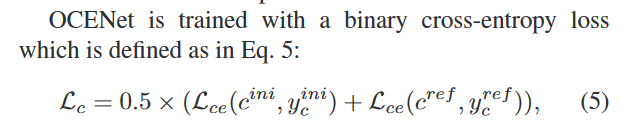
Uncertainty-Aware Learning(具有不确定性的学习)
伪装物体检测在整个图像中具有不同的学习困难。沿着物体边界的像素比远离伪装物体的背景像素更难区分。此外,伪装前景包含具有不同伪装水平的部分,其中一些部分易于识别,例如眼睛、嘴巴等,而另一些部分难以区分,例如身体区域具有与背景相似的外观。我们打算通过在我们的CODNet中建模不确定性意识,在整个图像中建模这种不同的学习难度。具体而言,受[47]的启发,我们提出训练具有不确定性感知结构损失的伪装对象检测网络:
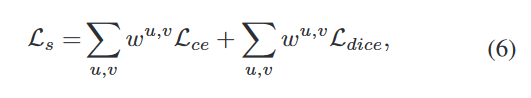
损失函数
Thinking
还没写完,先就这
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!