文章解读与仿真程序复现思路——电网技术EI\CSCD\北大核心《基于时空注意力卷积模型的超短期风电功率预测》
这个标题描述了一种用于超短期风电功率预测的模型,该模型基于时空注意力卷积模型。下面我会逐步解读这个标题的关键词和背景:
-
超短期风电功率预测:风电功率预测是指根据历史风速和其他相关数据,通过建立数学模型来预测未来特定时间段内的风电发电量。超短期预测通常指未来几分钟到几小时之间的预测,用于电网调度、能源市场交易和风电厂的运行优化等应用。
-
基于时空注意力卷积模型:时空注意力卷积模型是一种深度学习模型,它结合了时空信息的注意力机制和卷积操作,用于处理时序和空间数据。这种模型能够自动学习输入数据的时空依赖关系,并提取特征进行预测。
综合起来,标题中所描述的模型是基于时空注意力卷积模型的方法来进行超短期风电功率预测。这意味着该模型将结合风速、时间和空间信息以及注意力机制,通过卷积神经网络来学习风电功率的时空特征,并进行预测。这种模型可以提高风电功率预测的准确性和可靠性,为电力系统运行和风电厂运营提供重要的参考和决策支持。
摘要:随着风电利用率的不断提高,风电输出功率的准确预测对电力系统的调度和稳定运行具有重要意义。然而,风力发电的随机性和波动性容易影响功率预测结果的准确性。本文提出一种基于时空相关性的风电功率预测方法,由时空注意力模型和时空卷积模型组成。首先,利用空间注意力层和时间注意力层对不同风机之间的时空相关性进行聚合提取。其次,通过空间卷积层和时间卷积层有效捕捉风电数据之间的空间特征和时间演变规律。最后,采用中国两处实际风电场运行数据对预测方法进行实验验证。结果表明,相比于传统预测方法,时空注意力模型和时空卷积模型的融合使本文所提出的预测方法具有较高的预测精度和较好的稳定性。
这段摘要描述了一篇关于风电功率预测方法的研究论文。以下是对该摘要的解读:
-
背景:随着对风力发电的利用率不断提高,准确预测风电功率对电力系统的调度和运行具有重要意义。然而,风力发电的随机性和波动性会影响功率预测结果的准确性,因此需要提出一种更有效的预测方法。
-
方法:本文提出了一种基于时空相关性的风电功率预测方法,该方法由时空注意力模型和时空卷积模型组成。首先,使用空间注意力层和时间注意力层对不同风机之间的时空相关性进行聚合提取,以捕捉风电数据之间的相关特征。其次,通过空间卷积层和时间卷积层有效地捕捉风电数据的空间特征和时间演变规律。这样可以充分利用风电数据的时空特性进行预测。
-
实验验证:作者采用了中国两处实际风电场的运行数据对提出的预测方法进行了实验验证。结果表明,相比传统的预测方法,将时空注意力模型和时空卷积模型融合在一起的预测方法具有更高的准确性和更好的稳定性。
综合来看,这篇论文提出了一种采用时空注意力和时空卷积的方法来预测风电功率。通过充分考虑风力发电数据的时空相关性,该方法在风电功率预测方面表现出较高的精确度和稳定性。这对电力系统的调度和运行具有重要的实际意义。
关键词:风电功率预测:时空相关性;图神经网络;时空注意力模型;时空卷积模型;
关键词解读:
-
风电功率预测:指对未来某段时间内的风电场输出功率进行预测。这对电力系统的调度和运行非常重要,因为准确的功率预测可以帮助平衡供需关系并提高电力系统的稳定性。
-
时空相关性:指风电数据在时域和空域上的相关性。风力发电的功率受到时间和空间因素的影响,因此考虑数据的时空相关性可以提高预测准确性。通过分析和利用不同时间点和不同位置之间的相关性,可以更好地捕捉风电场的变化趋势和特征。
-
图神经网络:一类专门用于处理图结构数据的神经网络模型。在风电功率预测中,风电场可以看作是一个具有空间关系的图结构,不同的风机之间存在连接关系。图神经网络可以通过捕捉节点之间的关系来学习图数据的特征,并在预测中起到重要作用。
-
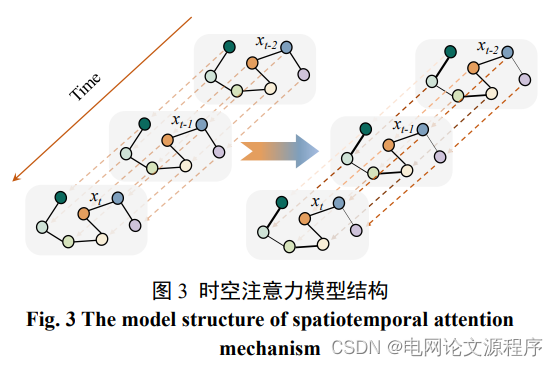
时空注意力模型:一种利用注意力机制来处理时空数据的模型。它可以自动学习不同时间和空间位置之间的权重,以选择性地聚焦于重要的时空关系。在风电功率预测中,时空注意力模型可以帮助准确地捕捉不同时间点和不同风机之间的时空相关性。
-
时空卷积模型:一种用于处理时空数据的卷积神经网络模型。它可以有效地捕捉数据在时间和空间上的特征和演变规律。在风电功率预测中,时空卷积模型可以通过卷积操作对风电数据的时空特征进行提取和建模,从而实现准确的功率预测。
综合来看,通过考虑风电数据的时空相关性,并结合图神经网络和时空注意力、时空卷积模型等技术,可以提供一种较为准确和稳定的风电功率预测方法。这些关键词在研究和应用风电功率预测方面具有重要的意义。
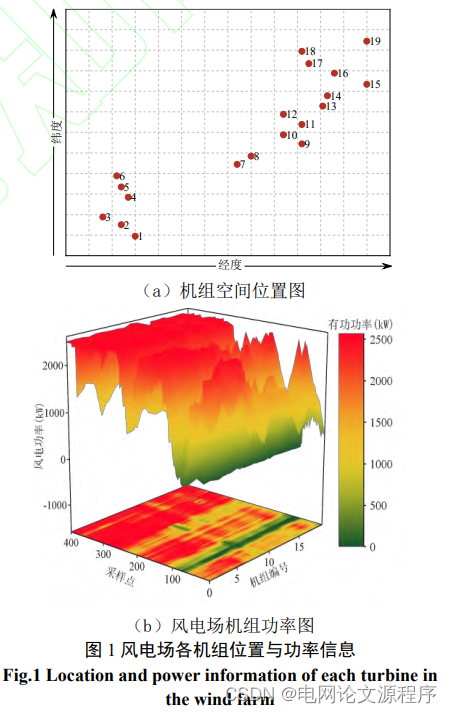
仿真算例:采用中国两个地区的风电场数据集进行相关 试验验证,其中风电场 A 位于中国东南地区,风电 场 B 位于中国华北地区。将每个风电场数据集分为 训练集、验证集和测试集,同时为了保证试验的公 平性,验证模型整体的稳定性,各个模型分别进行 10 次重复试验,采用 10 次重复试验评价指标的平 均值作为模型的最终评价指标,本文所有实验结果 均保持小数点后三位。 同时为验证本文所提模型对风电功率预测的 可行性,基于相同的风电功率数据集将本文所提出 的模型与常用的深度学习模型 BP、GRU 和 LSTM, 以及融合注意力机制的模型 A-LSTM、A-GRU 和图 神经网络模型 G-LSTM、G-GRU 进行预测性能对 比。为验证注意力机制对模型预测性能提升的有效 性,将 LSTM 、GRU 与 A-LSTM、A-GRU 模型进 行分析对比。为验证图结构网络特征提取的有效 性,将 LSTM 、GRU 与 G-LSTM、G-GRU 模型进 行对比。
仿真程序复现思路:
要复现该研究的仿真实验,需要按照以下步骤进行操作:
-
准备数据集:获取中国东南地区和华北地区的两个风电场数据集。将每个数据集划分为训练集、验证集和测试集。
-
模型选择:选择要比较的模型,包括本文提出的模型(A-LSTM、A-GRU、G-LSTM、G-GRU)以及常用的深度学习模型(BP、GRU、LSTM)。
-
重复试验:针对每个模型,进行10次重复试验,以验证模型整体的稳定性。在每次试验中,使用不同的随机种子或数据划分来保证试验的公平性。
-
评价指标计算:对于每次重复试验,计算预测性能指标,并将10次重复试验评价指标的平均值作为模型的最终评价指标。保留小数点后三位。
-
性能对比:使用相同的风电功率数据集,将本文提出的模型与常用的深度学习模型(BP、GRU、LSTM)进行预测性能对比。同时,分别对比LSTM、GRU和A-LSTM、A-GRU模型,以验证注意力机制对预测性能的提升效果。另外,对比LSTM、GRU和G-LSTM、G-GRU模型,以验证图结构网络特征提取的有效性。
以下是示例代码,展示了如何执行其中一次重复试验的模型训练和性能评价过程(以Python为例):
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# 准备数据集
wind_dataset_A = load_wind_dataset_A() # 加载风电场A的数据集
wind_dataset_B = load_wind_dataset_B() # 加载风电场B的数据集
# 划分数据集
X_train_A, X_val_A, y_train_A, y_val_A = train_test_split(wind_dataset_A['features'], wind_dataset_A['labels'], test_size=0.2, random_state=42)
X_train_B, X_val_B, y_train_B, y_val_B = train_test_split(wind_dataset_B['features'], wind_dataset_B['labels'], test_size=0.2, random_state=42)
# 模型训练和预测的函数
def train_and_predict(model, X_train, y_train, X_val):
model.fit(X_train, y_train) # 模型训练
y_pred = model.predict(X_val) # 模型预测
return y_pred
# 模型性能评价的函数
def evaluate_performance(y_true, y_pred):
mse = mean_squared_error(y_true, y_pred) # 均方根误差
rmse = np.sqrt(mse)
return rmse
# 重复试验次数
n_repeats = 10
# 评价指标列表
evaluation_results = []
# 执行重复试验
for i in range(n_repeats):
# 创建模型对象
model_A = ALSTM() # 使用A-LSTM模型
model_B = AGRU() # 使用A-GRU模型
# 在风电场A上进行训练和预测
y_pred_A = train_and_predict(model_A, X_train_A, y_train_A, X_val_A)
# 在风电场B上进行训练和预测
y_pred_B = train_and_predict(model_B, X_train_B, y_train_B, X_val_B)
# 计算评价指标并保存结果
result_A = evaluate_performance(y_val_A, y_pred_A)
result_B = evaluate_performance(y_val_B, y_pred_B)
evaluation_results.append((result_A, result_B))
# 计算平均评价指标
avg_result_A = np.mean([result_A for result_A, _ in evaluation_results])
avg_result_B = np.mean([result_B for _, result_B in evaluation_results])
# 打印结果
print(f"风电场A的平均均方根误差:{avg_result_A:.3f}")
print(f"风电场B的平均均方根误差:{avg_result_B:.3f}")
请注意,上述代码仅为示例,您需要根据您使用的模型库和工具进行相应的调用和操作。同时,这是一个基本的框架,您可能需要根据具体要求进行调整和扩展。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!