编译原理简介
编译系统的结构

词法分析(扫描)
编译的第一个阶段,从左到右逐行扫描源程序的字符,识别出各个单词(是高级语言中有是在意义的最小语法单元,由字符构成),确定单词的类型。将识别的单词转换成统一的机内表示即词法单元 简称Token
token:<种别码,属性值>

描述词法规则的有效工具是正规式和有限自动机。
正规式:用来确定单词是否和程序语言规范。
有限自动机:通过有限自动机进行单词和正规式比较
语法分析(parsing)
语法分析器从词法分析器输出的token序列中识别出各类短语,并构造语法分析树(parse tree),语法分析树描述了句子的语法结构
语法分析的规则
即语法规则又称文法,规定了单词如何构成短语、句子、过程和程序。
语法分析的方法
推导(derive)和归约(reduce)
推导:最左推导、最右推导
归约:最右归约、最左归约,推导的逆过程就是归约
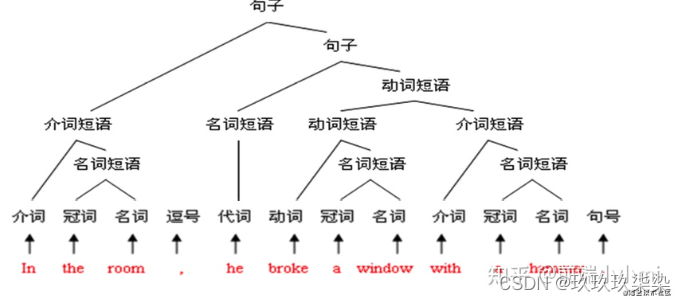
语法树
计算机通过语法树来进行分析,即语法分析过程也可以用一颗倒着的树来标示,这颗树叫语法树。正确的语法树叶子节点数必须是表达式的符号,例如
语义分析
语义的任务主要有两个
一. 收集标识符的属性信息
种属(Kind): 简单变量、复合变量(数组、记录、…)、过程、…
类型 (Type):整型、实型、字符型、布尔型、指针型、…
存储位置、长度
二. 语义检查
变量或过程未经声明就使用
变量或过程名重复声明
运算分量类型不匹配
操作符与操作数之间的类型不匹配
数组下标不是整数
对非数组变量使用数组访问操作符
对非过程名使用过程调用操作符
过程调用的**参数类型或数目不匹配 **
函数返回类型有误
中间代码生成
通常和语义分析一起实现。对语法分析识别出的各类语法范畴,分析他的含义,进行初步翻译,产生介于源代码和目标代码质检的一种代码
代码优化
对前面生成的中间代码进行加工变换,以便在最后极端产生更为高效的目标代码 ,需要遵循等价变换的原则,优化的方面包括:公共子表达式的提取、合并已知量、删除无用语句、循环优化。
目标代码生成
把经过优化的中间代码转化成特定机器上的低级语言
目标代码的形式:
绝对指令代码:可立即执行的目标代码
汇编指令代码:汇编语言程序,需要经过汇编程序汇编后才能运行
可重定位指令代码:先将各目标模块连接起来,确定变量、常数在主存中的位置,装入主存后才能成为可以运行的绝对指令代码
其他
出错处理
如果源程序有错误,编译程序应设法发现错误并报告给用户。由专门的出错处理程序来完成。 错误类型:
语法错误:在词法分析和语法分析阶段检测出来
语义错误:一般在语义分析阶段检测
逻辑错误:不可检测,比如死循环,一般不处理因为没办法在编译阶段检测出来
参考:https://zhuanlan.zhihu.com/p/362072187
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!