论文阅读: AAAI 2022行人重识别方向论文-PFD_Net
本篇博客用于记录一篇行人重识别方向的论文所提出的优化方法《Pose-Guided Feature Disentangling for Occluded Person Re-identification Based on Transformer》,论文中提出的PDF_Net模型的backbone是采用《TransReID: Transformer-based Object Re-Identification》的主干网络TransReID。
Pose-guided Feature Disentangling for Occluded Person
Re-identification Based on Transformer Tao Wang 北京大学机器感知深圳研究生院
论文:https://arxiv.org/abs/2112.02466
源码:https://github.com/WangTaoAs/PFD_Net
1. 论文所提方法
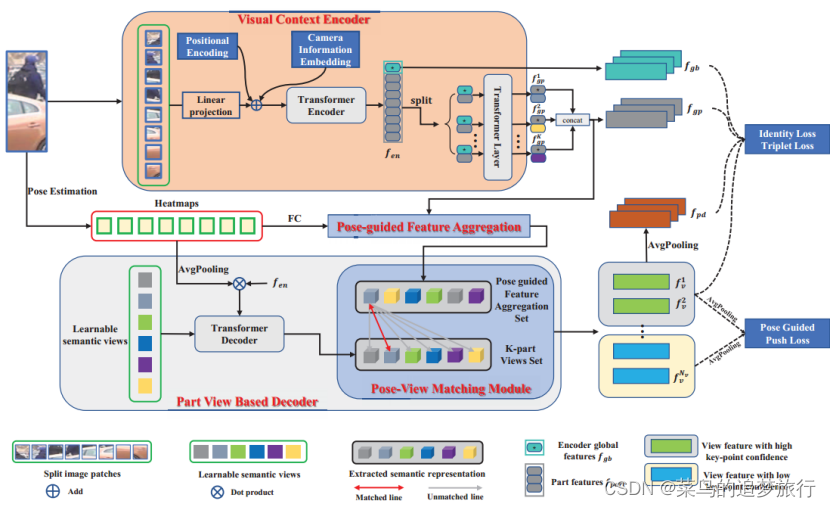
提出的PFD由四个部分组成。第一部分是视觉上下文编码器,它将摄像机信息编码到embedding中,以捕获全局上下文信息。第二部分是姿态引导特征聚合(PFA),它利用匹配和分布机制来初步引导可见的身体部位。第三部分是基于部分视图的解码器,在可学习语义视图的指导下,将姿势引导特征分解为判别视图集。第四部分是姿态-视图匹配模块(PVM),它将获得的视图集合(View set)和姿态引导的特征集合视为一个集合匹配问题。此外,为了强调可见身体部位的特征,提出了姿势引导下的Push Loss。有关更多详细信息,请参阅建议的方法。
3.1 Visual Context Transformer Encoder
我们使用基于Transformer的图像分类模型(即ViT(Dosovitskiy et al 2020))构建编码器。给定一个人物图像x∈,其中H、W、C分别表示高度、宽度和通道维度。我们首先通过使用滑动窗口将x分割成N个固定大小的补丁{|i=1,2,…,N}。步长可以表示为S,每个图像分块(Patch)的大小可以表示为P,补丁的数量N可以描述为:
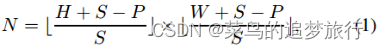
其中??是向下取整。当S等于图像分块大小P时,分割的图像块是不重叠的。当S小于P时,生成的图像块是重叠的,这可以减轻图像的空间邻域信息的损失。变换编码器只需要序列作为输入,因此在展平的像素块(flatten patch)上执行可训练的线性投影函数f(·),将像素块映射到D维,最终得到patch embeddings E∈,(即=f(),i=1,2。。。,N) 。
可学习的[class]token 被预先添加到像素块转换的embeddings中,并且输出的[class]token用作编码器全局特征表示 。为了保留位置信息,我们应用可学习的位置编码(positonal encodings)。然而,这些特征非常容易受到相机变化的影响,因此我们遵循(He et al 2021)中的方法来学习相机视角信息。那么最终的输入序列可以被描述为:
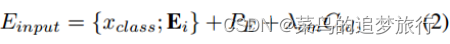
其中是位置嵌入(positional embeddings),∈是相机嵌入(camera embeddings),对于相同的图像,是相同的。是一个超参数,用于平衡相机嵌入的权重(weight)。接下来,输入embedding将由m个变换器层(transformer layers)处理。编码器的最终输出∈可以分为两部分(编码器全局特征和局部特征):∈和∈。为了学习人体部位(human parts)的更多判别特征,将部位特征(part features)按顺序分为K组,每组的大小为(N//K)×D。然后,连接编码器全局特征∈的每个组将被馈送到共享变换器层(shared transformer layer)中,以学习K组 part local feature(部分局部特征)=[,,…,]。
编码器监督损失(Supervision Loss)。我们采用交叉熵损失作为编码器全局特征和分组特征的单位损失和三元组损失。编码器损失函数可以公式化为:
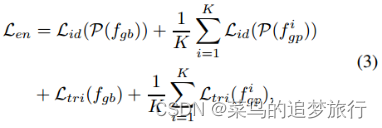
3.2姿势引导的特征聚合
被遮挡的人图像的身体信息较少,非身体部位的信息可能不明确,这会导致性能下降。因此,我们使用人体姿态估计器来从图像中提取关键点信息。
姿势估计。给定人物图像x,姿态估计器从输入图像中提取M个姿态点。然后,利用姿态点来生成热图H=[,,…,]。每个热图都被下采样到(H/4)×(W/4)的大小。每个热图的最大响应点(The maximum response point)对应于一个关节点。我们设置了一个阈值γ来过滤出高置信度标签和低置信度标签。但与(Miao et al 2019)不同的是,我们没有将关键点置信度得分小于γ的热图设置为0。相反,标签∈{0,1}, (i=1, …, M)将分配给每个热图。从形式上讲,热图标签可以表示为:
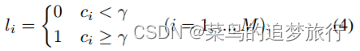
式中为第i个关键点的置信度得分。
姿态导向的特征聚合。为了整合姿态信息,我们设置K = M,正好等于关键点的个数。然后,对热图H应用全连接层,得到热图H′,其维数与组局部特征(the group part local feature)相同。然后,热图H′点乘(element-wisely)的每个元素,得到姿态引导特征P = [, ,…][m]。虽然P已经明确编码了人体不同部位的信息,但我们希望从中找到对某一身体部位贡献最大的部分信息。为此,我们开发了一种匹配和分配机制,该机制将部位局部特征( part local feature)和姿态点引导特征(pose guided feature)作为一个集合相似度度量问题。最后得到姿态引导特征聚合集S = { | i = 1,2,…, M}。对于每个,我们可以找到中最相似的特征,然后将两个特征相加形成Si。在形式上,
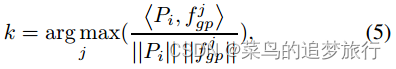

其中i = 1, 2, …, K, ?·,·?代表内积, 表示 与中最相似的内积。
3.3 Part View Based Transformer Decoder
在本节中,我们定义了一组可学习的语义部件视图来学习可区分的身体部件。可学习的语义部件视图可以表示为Z = { | i = 1,2,…, },和Z∈将作为查询(queries)添加到每个交叉注意层(cross-attention layer)。如图2所示,键值(key和values)来源于姿态点热图H与编码器输出的组合。将平均池化层应用于热图H,然后将相乘,最终输出∈×D。形式上,查询、键和值可以表示为:
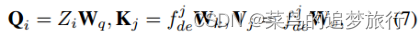
姿态-视图匹配模块:
在交叉注意机制中,部分语义视图可以学习到一些判别特征。然而,不知道是哪一部分或哪一种信息被学习了。因此,为了获得与人体骨骼相关的特征,我们提出了一个姿态视图匹配模块。由于姿态引导特征聚合集合S的每一个特征都与人体的某个关键点信息相关,我们可以通过计算人体部位视图与的相似度来找到与人体某个关键点相关的部位视图。将匹配的语义部件视图和姿势引导的特征聚合特征(pose guided feature aggregation feature)相加,得到最终的视图特征集合= { |i = 1,2,…, }。在形式上,
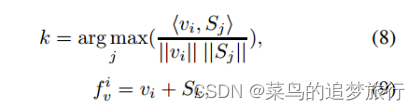
由于关键点置信度得分可以指示特征的哪一部分包含人体信息,热图标签可以引导我们将视图特征集分成两部分。视图集特征中热图标签 = 1的特征形成高置信度关键点视图特征集 = {|i = 1,2,…, L},其余组成低置信度关键点视图特征集 = { |i = 1,2,…, ?L},其中L表示中热图标签为1的特征个数。
推荐博客
如果想了解这篇论文的代码细节,推荐大家阅读这篇博客。
PFD_net和TransReID学习——一:TransReID backbone学习
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!