国产670亿参数的DeepSeek:超越Llama2,全面开源
模型概述
DeepSeek,一款国产大型语言模型(LLM),凭借其670亿参数的规模,正引领着人工智能领域的新浪潮。这款模型不仅在多项中英文公开评测榜单上超越了700亿参数的Llama 2,而且在推理、数学和编程能力方面表现突出。最引人注目的是,DeepSeek在匈牙利最新高中数学考试中获得了65分的高分,显示出其卓越的数学解题能力。
-
Huggingface模型下载: https://huggingface.co/deepseek-ai
-
AI快站模型免费加速下载: https://aifasthub.com/models/deepseek-ai

技术创新
DeepSeek的核心架构借鉴了Llama模型,采用自回归Transformer解码器架构。它具有两个版本,分别是70亿和670亿参数。重要的是,该模型使用多头注意力(MHA)和分组查询注意力(GQA)技术,这些技术有效提高了模型的性能和效率。此外,它在2万亿个中英文token的数据集上进行了预训练,展现出了强大的双语处理能力。
性能展示
在标准基准测试中,DeepSeek展示了其强大的能力。在多种语言任务,如TriviaQA、MMLU、GSM8K、HumanEval等方面,DeepSeek都显示出了卓越的性能。特别是在中文QA测试中,DeepSeek的表现超越了GPT-3.5,验证了其在处理中文内容上的优势。

指令跟随能力
DeepSeek还通过了Google发布的指令跟随评测集的测试,得分59.1分,领先于众多开源模型。尽管与GPT-4还有一定差距,但这一成绩充分证明了其在理解和执行复杂指令方面的能力。

编码能力测试
DeepSeek在LeetCode最新真题的测试中也表现出色,其性能优于国内常见的大模型,并显著超越了GPT 3.5。这一结果证明了DeepSeek在编程领域的应用潜力。

训练细节
DeepSeek的训练过程着重于多步学习率计划,从2000个预测步骤开始,然后在大量token的基础上逐步达到最大学习率的一定比例。这种独特的学习率调整策略与Llama的传统余弦学习率衰减法截然不同,显示出其独特的训练效率。
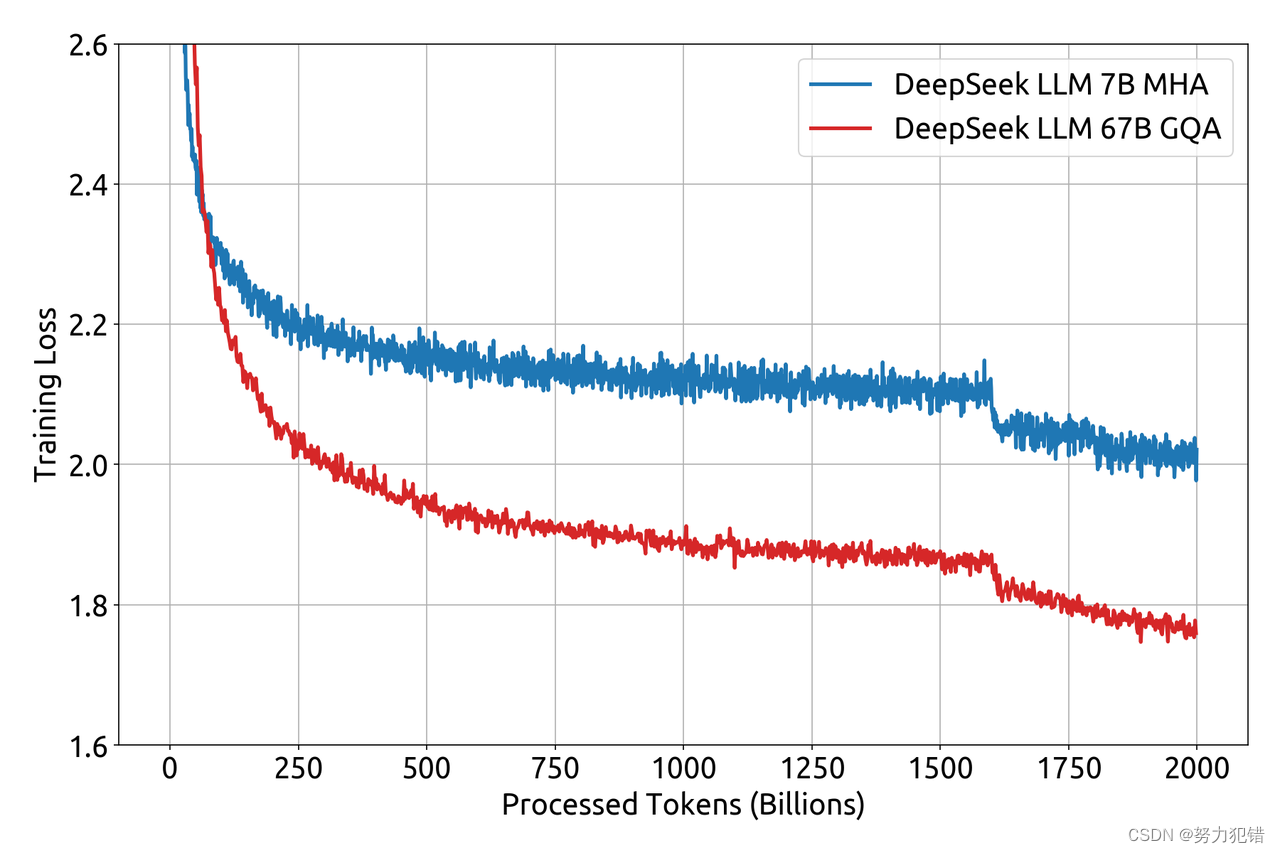
开放和可访问性
值得一提的是,DeepSeek提供了70亿和670亿两个参数版本的基础模型和指令微调模型,均已开源并可免费商用。这一举措极大地促进了AI社区的发展和创新。
结论
DeepSeek的出现标志着国产大模型技术的一大进步。它不仅在性能上超越了国际同类产品,还在开放性和可用性方面树立了新的标准。无疑,DeepSeek将在促进AI技术的广泛应用和创新方面发挥重要作用。
模型下载
Huggingface模型下载
https://huggingface.co/deepseek-ai
AI快站模型免费加速下载
https://aifasthub.com/models/deepseek-ai
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!