1分钟生成爆款风景视频,Stable Video Diffusion最简教程
AI视频是2024年的重头戏,各大AI厂商都在跑视频技术,快速推出更牛的黑科技,SD其实在11月底就出了一款官方视频大模型-SVD,来跟runway、pika抢这块大蛋糕。
之前生成的视频效果还不是很理想,远没runway效果好,就没去凑热闹去内容,但近期我们测试了下,试着拿来做AI风景的视频,发现效果还真的不错,关键还是免费的!看来它大模型每天训练升级得很快,那今天就给大家讲讲SVD的。
今天就仔细给大家介绍这款由Stable Diffusion官方推出的AI视频生成工具——Stable Video Diffusion(SVD),生成视频分辨率高达1024x576,画面流畅度和细节都很出色。
先给大家看三段官方视频



由于SVD是基于Stable Diffusion超强的绘画生成能力,所以进化很快,现在已经能高质量地实现了图生视频。不仅支持图生视频,还支持视频转视频,还支持3D合成视频功能!
只需一张图片,就可以进行3D合成,360度丝滑展示视频真的强,野心有点大,大有往工业级和影视级的AI工具站位,前景真的无限广阔。

不多说了,如何最快地用上Stable Video Diffusion?
我先贴出官方地址:
https://stable-video-diffusion.com/
接下来先来个最简单的傻瓜式演示操作:
第 1 步:打开SVD官方链接,选择并上传要转换为视频的图像(用MJ或SD生成图像)
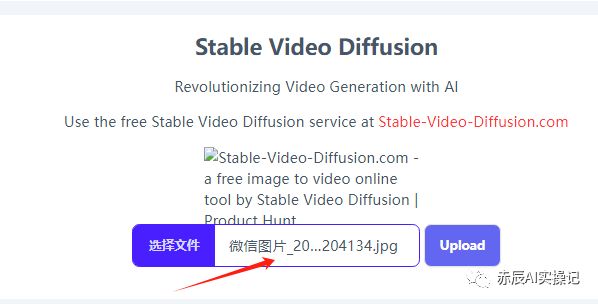
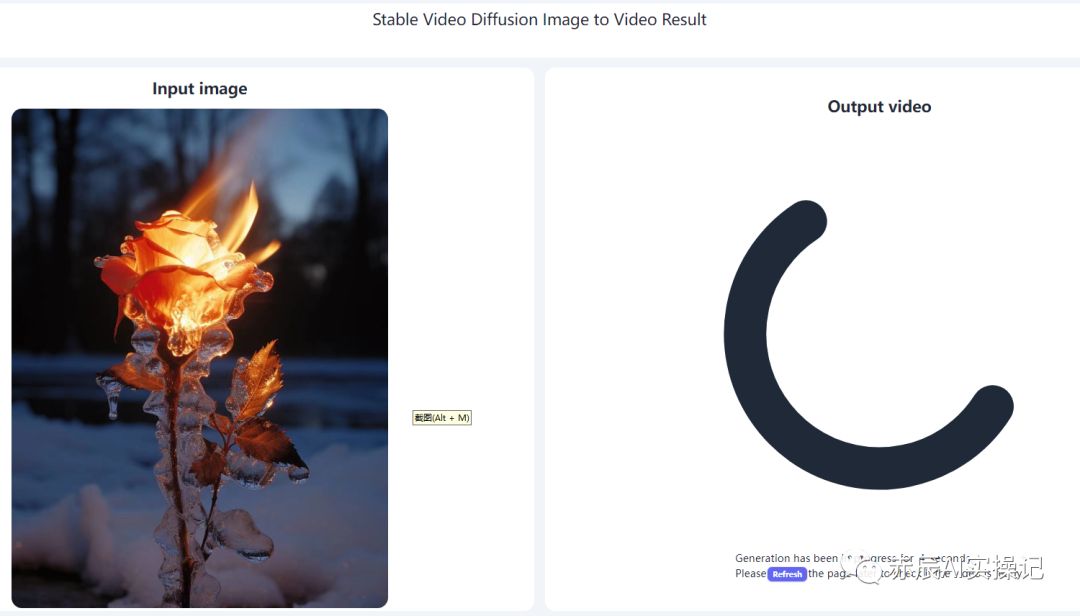
第 2 步:上传图像后,Stable Video Diffusion模型会对图进行处理,转成视频,整个过程需要等1-5分钟,具体取决于视频的复杂性。
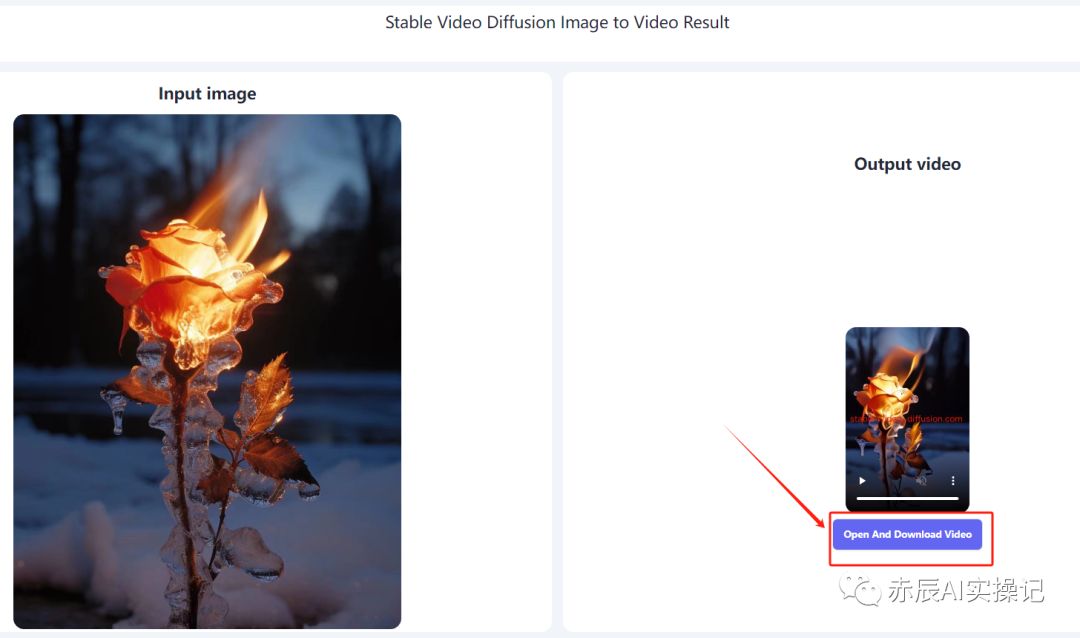
第 3 步:生成视频后,就可以将其下载,最后查看生成后的质量,当然如果觉得不满意,还可以进行调整或重新生成视频。
来看看视频生成效果
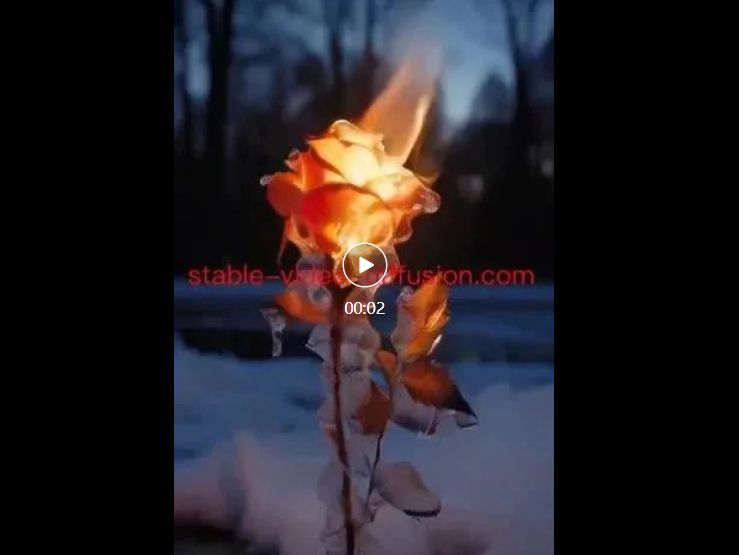
这次演示,大家有没发现少了个关键步骤?对的,我没有输入任何提示词!它是在没有任何提示词的情况下,直接读图,理解图片要表达什么样的内容,直接帮我生成视频效果!
居然知道我想要的视频效果,不愧是采用了6亿样本视频数据集训练出的开源大模型。而且效果非常接近小红书的爆款作品风景号。
SVD的出现,无疑也充当了一条鲶鱼,推进视频AI生成的爆发,它免费开源特性让大厂们瑟瑟发抖,让普通用户也能0付费体验这类黑科技。。
本期仅进行最快能用的在线演示操作,要更复杂点的,我们就得下载开源文件,进行本地安装运行,生成无水印的视频,对显卡的要求也高,这里操作很多,就不一一步骤贴出。感兴趣直接上以下网站
开源地址:
https://github.com/Stability-AI/stablediffusion
论文地址:
https://static1.squarespace.com/static/6213c340453c3f502425776e/t/655ce779b9d47d342a93c890/1700587395994/stable_video_diffusion.pdf
目前我相信它还处于非常初级阶段,1万米长跑,只跑了100米,仍然非常大的发展空间和可能性。也有局限性,比如:无法通过提示词进行精准控制视频运动的轨迹,也无法生成静态或者慢动作视频,而且在生成人物脸部处理方便还存在一些问题。
但相信随着视频生成式AI工具的快速发展,这些不用几个月都能快速突破,届时将进入人人都可以制作电影和短剧的时代,让我们拭目以待。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!