redis中缓存雪崩,缓存穿透,缓存击穿等
缓存雪崩
????????由于原有缓存失效(或者数据未加载到缓存中),新缓存未到期间(缓存正常从Redis中获取,如下图)所有原本应该访问缓存的请求都去查询数据库了,而对数据库CPU和内存造成巨大压力,严重的会造成数据库宕机,造成系统的崩溃。比如我们设置缓存时采用了相同的过期时间,在某个时间节点,大量的 key 失效,导致大量的请求从缓存中获取不到数据而去请求数据库。
解决方法:
(1)碰到这种情况,一般并发量不是特别多的时候,可以加锁排队,加锁排队的解决方式分布式环境的并发问题,有可能还要解决分布式锁的问题;线程还会被阻塞,用户体验很差!因此,在真正的高并发场景下很少使用!
????????加锁排队只是为了减轻数据库的压力,并没有提高系统吞吐量。假设在高并发下,缓存重建期间key是锁着的,这是过来1000个请求999个都在阻塞的。同样会导致用户等待超时,这是个治标不治本的方法!
(2)给每一个缓存数据增加相应的缓存标记,记录缓存的是否失效,如果缓存标记失效,则更新数据缓存,
(3)设置有效期均匀分布
避免缓存设置相近的有效期,我们可以在设置有效期时增加随机值;
或者统一规划有效期,使得过期时间均匀分布。
(4)数据预热
对于即将来临的大量请求,我们可以提前走一遍系统,将数据提前缓存在Redis中,并设置不同的过期时间。
(5)保证Redis服务高可用
前面我们介绍过Redis的哨兵模式和集群模式,为防止Redis集群单节点故障,可以通过这两种模式实现高可用。
(6)做二级缓存,或者双缓存策略。A1为原始缓存,A2为拷贝缓存,A1失效时,可以访问A2,A1缓存失效时间设置为短期,A2设置为长期。
缓存穿透
缓存穿透意思就是某个不存在的key一直被访问,结果发现数据库中也没有这样的数据,最终导致访问该key的所有请求都直接请求到数据库了。
大并发的缓存穿透会导致缓存雪崩。
解决方案:
(1)如果查询数据库也为空,直接设置一个默认值存放到缓存,这样第二次到缓冲中获取就有值了,而不会继续访问数据库。
????????某个key数据并不存在,那么就存一个 NULL 就好了,但是一定不要忘记设置过期时间,因为假设id=3的记录不存在,然后本次访问没有查询到数据,缓存中存的是null如果过一会儿新增了一条记录为3的数据,如果缓存不设置过期时间,那么这条数据就永远获取不到。
(2)根据缓存数据Key的规则。例如我们公司是做机顶盒的,缓存数据以Mac为Key,Mac是有规则,如果不符合规则就过滤掉,这样可以过滤一部分查询。在做缓存规划的时候,Key有一定规则的话,可以采取这种办法。这种办法只能缓解一部分的压力,过滤和系统无关的查询,但是无法根治。
(3)采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的BitSet中,不存在的数据将会被拦截掉,从而避免了对底层存储系统的查询压力。关于布隆过滤器,详情查看:基于BitSet的布隆过滤器(Bloom Filter)
布隆过滤器(bloomfilter)是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以判断数据是否在表中。将数据项添加到布隆过滤器中,用k个不同的哈希函数映射数据项的位置。
例子:将“semlinker”数据项存入布隆过滤器中,使用三个不同的哈希方式产生三个索引246。查询这个数据项时,查看这三个哈希函数运算后产生的索引值,246其中任何一个索引位为‘0’,则该值不在集合中;均为1的话则可能存在在集合中。
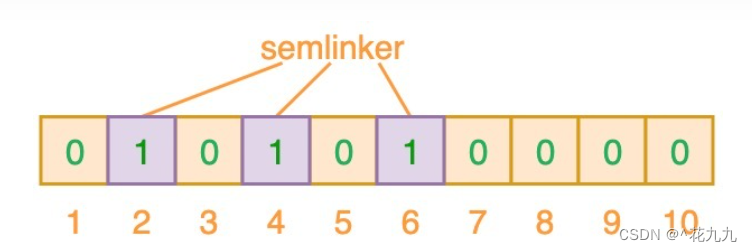
布隆过滤器优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
缓存击穿
Redis中一个热点key在失效的同时,大量的请求过来,从而会全部到达数据库,压垮数据库。
解决方法:
(1)设置热点数据永不过期
对于某个需要频繁获取的信息,缓存在Redis中,并设置其永不过期。当然这种方式比较粗暴,对于某些业务场景是不适合的。
(2)定时更新
比如这个热点数据的过期时间是1h,那么每到59minutes时,通过定时任务去更新这个热点key,并重新设置其过期时间。
(3)互斥锁
这是解决缓存穿透比较常用的方法。
互斥锁简单来说就是在Redis中根据key获得的value值为空时,先锁上,然后从数据库加载,加载完毕,释放锁。若其他线程也在请求该key时,发现获取锁失败,则睡眠一段时间(比如100ms)后重试。
缓存预热
????????缓存预热就是系统上线后,提前将相关的缓存数据直接加载到缓存系统。避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题!用户直接查询事先被预热的缓存数据!
解决方案:
(1)直接写个缓存刷新页面,上线时手工操作下;
(2)数据量不大,可以在项目启动的时候自动进行加载;
(3)定时刷新缓存;
缓存更新
????????redis 内存淘汰机制?(默认的有6中策略),我们还可以根据具体的业务需求进行自定义的缓存淘汰,常见的策略有两种:
(1)定时去清理过期的缓存;
(2)当有用户请求过来时,再判断这个请求所用到的缓存是否过期,过期的话就去底层系统得到新数据并更新缓存。
redis 内存淘汰机制有以下几个:
- noeviction: 不删除策略, 达到最大内存限制时, 如果需要更多内存, 直接返回错误信息。 大多数写命令都会导致占用更多的内存(有极少数会例外, 如?DEL?)。
- allkeys-lru:所有key通用; 优先删除最近最少使用(less recently used ,LRU) 的 key。
- allkeys-random:?所有key通用; 随机删除一部分 key。
- volatile-lru:只限于设置了?expire?的部分; 优先删除最近最少使用(less recently used ,LRU) 的 key。
- volatile-random:只限于设置了?expire?的部分; 随机删除一部分 key。
- volatile-ttl:只限于设置了?expire?的部分; 优先删除剩余时间(time to live,TTL) 短的key。
缓存降级
????????当访问量剧增、服务出现问题(如响应时间慢或不响应)或非核心服务影响到核心流程的性能时,仍然需要保证服务还是可用的,即使是有损服务。系统可以根据一些关键数据进行自动降级,也可以配置开 关实现人工降级。 降级的最终目的是保证核心服务可用,即使是有损的。而且有些服务是无法降级的(如加入购物车、结算)
????????在进行降级之前要对系统进行梳理,梳理出哪些必须誓死保护,哪些可降级;比如可以参考日志级别设置预案:
(1)一般:比如有些服务偶尔因为网络抖动或者服务正在上线而超时,可以自动降级;
(2)警告:有些服务在一段时间内成功率有波动(如在95~100%之间),可以自动降级或人工降级,并发送告警;
(3)错误:比如可用率低于90%,或者数据库连接池被打爆了,或者访问量突然猛增到系统能承受的最大阀值,此时可以根据情况自动降级或者人工降级;
(4)严重错误:比如因为特殊原因数据错误了,此时需要紧急人工降级。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!