MySql海量数据存储与优化
一、Mysql架构原理和存储机制
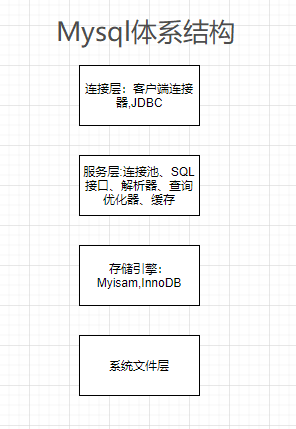
1.体系结构
2.查询缓存
3.存储引擎
存储引擎的分类
- innodb:支持事务,具有支持回滚,提交,崩溃恢复等功能,事务安全
- myisam:不支持事务和外键,查询速度高
- Memory:利用内存创建表,访问速度非常快,因为数据在内存,而且默认使用Hash索引,但是一旦关闭,数据就会丢失
- Archive:归档类型引擎,仅能支持insert和select语句
- Csv:以CSV文件进行数据存储,由于文件限制,所有列必须强制指定not null,另外CSV引擎也不支持索引和分区,适合做数据交换的中间表
- BlackHole: 黑洞,只进不出,进来消失,所有插入数据都不会保存
- Federated:可以访问远端MySQL数据库中的表。一个本地表,不保存数据,访问远程表内容。
- MRG_MyISAM:一组MyISAM表的组合,这些MyISAM表必须结构相同,Merge表本身没有数据,对Merge操作可以对一组MyISAM表进行操作。
INNODB和myIsam的对比
- 事务和外键
- innodb支持事务和外键,具有安全性和完整性,适合大量的insert和update操作。
- myisam不支持事务和外键,它提供高速存储和检索,适合大量的select操作。
- 锁机制
- Innodb支持行级锁,锁定指定记录,基于索引来加锁实现。
- myisam支持表级锁,锁定整张表。
- 索引结构
- innodb使用聚集索引(聚簇索引),索引和记录在一起存储,即缓存索引,也缓存记录。
- myisam使用非聚集索引,索引和记录分开。
- 并发处理能力
- myisam使用表级锁,会导致写操作并发低,读之间并不阻塞
- innodb读写阻塞可以与隔离级别有关,可以采用多版本并发控制(MVCC)来支持高并发。
- 存储文件
- innodb表对应两个文件,一个.frm表结构文件,一个.ibd数据文件
- myisam表对应三个文件,一个.frm表结构文件,一个MYD表数据文件,一个.MYI索引文件。默认限制是256TB。
- 适用场景
- myisam:不需要事务支持(不支持);并发相对较低(锁定机制问题);数据修改相对较少,以读为主;数据一致性要求不高。
- innodb:需要事务支持;行级锁对高并发有很好的的适应能力;数据更新较为频繁的场景;数据一致性要求较高;硬件设备内存较大,可以利用innodb较好的缓存能力来提高内存利用率,减少磁盘的IO。
INnoDb内存结构
-
Buffer Pool:缓冲池,简称BP。
-
Page管理机制
page根据状态可以分为三种类型:
- free page:空闲page,未被使用过
- clean page:被使用的page,数据没有被修改过
- dirty page:脏页,被使用page,数据被修改过,页中数据和磁盘中的数据产生了不一致。
针对上面三种类型,innodb通过三种链表结构来维护和管理
- free list:表示空闲缓冲区,管理free page
- flush list:表示需要刷新到磁盘的缓冲区,管理dirty page,内部page按修改时间排序。脏页即存在于flush 链表,也在LRU链表中,但是两种互不影响,LRU链表负责管理page的可用性和释放,而flush链表负责管理脏页的刷盘操作。
- lru list:表示正在使用的缓冲区,管理clean page和dirty page,缓冲区以midpoint为基点,前面链表称为new列表区,存放经常访问的数据,占63%;后面的链表称为old列表区,存放使用较少数据,占37%。
-
改进型LRU算法维护
-
-
Change Buffer:写缓冲区。
3.1 undo log
undo:?undo意思为撤销和回退,以撤销为目的,指能回到过去的某种状态。
undo log:?事务在开始之前,会将历史的数据保存到undo log中,当发生回滚或者未提交事务时数据库崩溃了,可以通过undo log回退到数据的快照版本,撤销掉未提交的事务对数据库产生的影响。
undo log的产生和销毁:?undo log在事务开始之前产生,在事务结束之后也不会立即销毁,而是先将undo log加入到删除列表中,而是通过后台的线程purage thread进行销毁;uodo log的本质是逻辑日志,是记录的一个相反的过程,例如:如果执行的是一个delete操作,则在undo log中记录一条insert操作,执行的是一个insert操作,则在undo log日志中记录一条delete操作,如果是执行的一个update 操作,则在undo log中记录一条相反的update记录。
undo log在MVCC(多版本并发控制)中的应用:?事务提交之前,undo log中先保存了旧版本的数据,此时事务没结束时,可以供其他的事务进行快照读。 (理解:事务A执行更新操作,首先先把旧版本数据同步到 undo buffer中(后续会持久化道undo log中),事务B手动开启事务,执行查询操作,会在undo log中读取快照版本数据)
3.2 redolog
redo:?redo的含义就是重做,意思是恢复操作,在数据库发生意外时重现操作。
redo log:?事务修改的任意数据,都将最新的数据备份到redo log中,称为重做日志。
redo log的生成和释放:随着事务的操作的执行,就会产生redo log,随着事务的提交,会将生产的redo log写到log buffer中,并不是随着事务的结束log buffer中的数据会立即写入到磁盘中。等到buffer pool中的脏页刷新到磁盘中之后,redo log的使命也就完成了,redo log占用的空间就可以被重用(覆盖写入)。
redo log的实现原理:?redo log是为了事务的持久化这一特性的产物,当事务提交时,buffer pool里面的脏页还没有全部的刷新到硬盘时,数据库宕机了,当重启mysql之后,就可以依据redo log里面的内容进行重做,继续将数据持久化到硬盘中。
redo log写入机制:?redo log的写入机制是顺序写入的方式,写满时则进行回溯,进行覆盖写。
3.3 binlog
二、Mysql索引存储机制和工作原理
1.索引类型
- 从索引的存储结构划分:B-Tree索引、Hash索引、FULLTEXT全文索引、R Tree索引
- 从应用层次划分:普通索引、唯一索引、主键索引、复合索引
- 从索引键值类型划分:主键索引、辅助索引(二级索引)
- 从数据存储和索引键值逻辑关系划分:聚集索引、非聚集索引
普通索引:即针对数据库表创建索引
唯一索引:与普通索引类似,添加唯一索引的列值必须唯一,但允许有空值
主键索引:特殊的唯一索引,不允许有空值,一般是在建表的时候同时创建主键索引。
组合索引: 为了进一步的榨取mysql的效率,考虑建立组合索引,即将数据库表中的多个字段联合起来作为一个组合索引。
- 好处:形成索引的覆盖,提高where语句的查询效率
- 使用原则:where后的第一个条件就应该是复合索引的第一列,依次类推。
- 如果一个表中的数据在查询的时候有多个字段总是同时出现,就可以将这些字段作为复合索引使用,提高覆盖率,提高查询的效率
全文索引:
2.索引原理
用于快速查找记录的一种数据结构。需要额外的开辟空间和数据维护工作。
- 索引是物理数据页存储,在数据文件中(innodb-ibd文件),利用数据页存储。
- 索引可以加快检索速度,但同时也会降低增删改操作速度,索引维护需要代价。
二分查找法
二分查找法也叫作折半查找法,时间复杂度是log2 N,二分查找法的优点是等值查询和范围查询的效率比较高,缺点是对于一些增删改的操作比较慢。
查询过程:
- 首先要求查询的序列是有序的,在这里我们以递增序列为例
- 定义两个指针,左指针L和右指针R,分别位于序列的两端
- 计算出(L+R)/2的值M,根据这个索引值M获取数据值,用数据值和目标数据比较,如果相等则返回结果,如果数据值大于目标数据值,那么将R指针定为M-1,L不变,如果数据值小于目标数据值,那么将L指针定为M+1,R不变。重复以上查询过程,直到查询出数据(或者最后也没有数据)为止。
Hash结构
B+Tree结构
B树的阶数指的是每个节点最多有几个子节点(N阶指的是有N个子节点)
每个节点里面最多存放N-1个值
-
B-Tree结构
- 索引值和data数据存放在整棵树结构上
- 每个节点可以存放多个索引值和数据值
- 树节点的多个索引值自左到右升序排列
- 从根节点开始,对根节点的数据按照二分查找法查找,找不到的话便遍历子节点,直到所对应的指针为空或者已经是叶子结点才结束。
-
B+Tree结构
- 非叶子结点只存储索引值,这样可以存储更多的索引
- 叶子结点存储所有的索引值和对应数据
- 叶子结点之间用指针连接,提高区间的访问性能
- 相比B树,B+树进行范围查找时,只需要查找定位两个节点的索引值,然后利用叶子结点的指针进行遍历即可。而B树需要遍历范围内所有的节点和数据,显然B+Tree效率高。
聚簇索引和辅助索引
- 聚簇索引和非聚簇索引:B+tree结构中,叶子结点中主键索引和数据存放在一块,称为聚簇索引;索引和数据不存放在一块,则称为非聚簇索引。
- 主键索引和辅助索引:B+Tree结构中,叶子结点中存放的是主键字段值就属于主键索引,如果存放的是非主键字段值就属于辅助索引(二级索引)。
3.索引分析与优化
3.1 Expain排查sql性能
- id:固定标识
- select_type:表示查询的类型,常用的值如下:
- SIMPLE:表示查询的语句比较简单,不包含子查询或者union
- PRIMART:表示此查询是最外层的查询。(如果一条查询语句为union或者是含有子查询,那么最外层的那个sql查询类型便是PRIMARY)
- UNION:表示此查询是UNION的第二个或后续的查询
- DEPENDENT UNION:union中的第二个或者后续的查询语句,使用到了外边的查询结果
- UNION RESULT:UNION的结果
- SUBQUERY:select子查询语句
- DEPENDENT SUBQUERY:select子查询语句依赖外层 的查询的结果。
最常见的查询类型就是simple,表示我们没有使用子查询和联合查询
# 使用sql案例:
# SELECT_type = SIMPLE
EXPLAIN SELECT * FROM `lagou_auth_code`;
# SELECT_type = PRIMART 和 SUBQUERY
EXPLAIN select * from lagou_auth_code where create_time = (SELECT MAX(create_time) from lagou_auth_code);
EXPLAIN SELECT a.code,
(SELECT email from lagou_token where token = 'b53e8b9c-04a2-4b3e-8306-e5a50a8c2c85') temail
FROM lagou_auth_code a ;
# SELECT_type = PRIMART 和 DEPENDENT SUBQUERY
explain SELECT email,`code`
from lagou_auth_code l1
where create_time = (
SELECT MAX(create_time) from lagou_auth_code l2 where l1.email = l2.email);
# SELECT_type = PRIMART 和 UNION 和 UNION RESULT
EXPLAIN SELECT code
from lagou_auth_code where email = 'zae_zangchuanlei@163.com'
UNION
SELECT token
from lagou_token where email = 'zae_zangchuanlei@163.com';
# SELECT_type = PRIMART 和 DEPENDENT SUBQUERY 和 DEPENDENT UNION
EXPLAIN
SELECT * from lagou_auth_code
where id in (
SELECT id
from lagou_auth_code
where id = '394017376523259904'
UNION
all
SELECT id
from lagou_auth_code)
-
table:表示哪张表
-
partitios
-
type:连接类型(数据库引擎以什么方式去查询出数据,是比较重要的属性,根据这个属性可以判断出是全局扫描还是基于索引的扫描查询),常用属性值如下,自上至下效率越来越高。
-
ALL:表示全表扫描,性能最差。
-
INDEX:表示基于索引的全局扫描,先扫描索引再扫描全表数据。(在排序的情况下效率较高)
-
range:表示使用索引范围查询,使用>、>=,<,<=,in等等
-
ref:表示使用非唯一索引进行单值查询。
-
eq_ref:一般情况下出现在多表join查询中,表示前面的那个表每一个记录,都只能匹配后面表的一行结果(表设计时采用的一对一的方式)
-
const:表示我们使用主键或唯一索引做等值查询了,也被称作常量查询。
-
NULL:表示不用访问表,速度最快。
-
-
possible_keys:表示的是查询时能够使用到的索引。注意并不一定会真正的使用。
-
key:表示查询时真正使用的索引,显示的是索引名称。
-
key_len:表示查询使用索引的字节数量,可以用它来判断是否全部使用了组合索引,或者只用到索引的最左不分的部分字段值。
key_len的计算规则如下:
- 字符串类型:字符串长度跟字符集有关:latin1=1、gbk=2、utf8=3、utf8mb4=4. char(n):n字符集长度
varchar(n):n字符集长度+2字节 - 数值类型:int:4个字节
- 时间类型:DATE:3个字节
- 字段属性:NULL属性占1个字节
- 字符串类型:字符串长度跟字符集有关:latin1=1、gbk=2、utf8=3、utf8mb4=4. char(n):n字符集长度
-
ref
-
rows:记录行数(mysql查询优化器会根据统计信息,估算SQL要查询到结果需要扫描多少行记录。原则上rows是越少效果越好)
-
filtered
-
extra:额外的扩展的一些信息。表示很多额外的信息,各种操作会在extra提示相关信息,常见的几种如下:
- Using where:表示查询需要通过索引回表查询数据
- Using index:表示查询需要通过索引,索引就可以满足所需数据。
- Using filesort:表示查询出来的结果需要额外排序,数据量小在内存,大的话在磁盘,因此有Using fileSort建议优化。
- Using temprorary:查询使用到了临时表,一般出现去重,分组等操作。
3.2 回表查询
通过索引查询主键值,然后再去聚簇索引查询记录信息
3.3 覆盖索引
只需要在一棵索引树上就能获取SQL所需的所有列数据,无需回表,速度更快,这就叫做索引覆盖。
3.4 最左前缀原则
复合索引遵循最左前缀原则,最左前缀顾名思义就是最左优先,即查询中条件使用到最左边的列,那么索引将会生效,如果查询使用第二列或者其他非最左边的列,那么索引将会失效。
3.5 LIKE查询
面试题:mysql在使用like查询的时候,索引能不能起作用?
回答:mysql在使用的时候是可以被使用的,但是有条件,只有把%字符写在后面才会使用到索引。“target%”。
3.6 NULL查询
面试题:如果mysql表的某一列含有NULL值,那么包含该列的索引是否有效?
mysql可以在含有NULL的列上使用索引的,但是NULL和其他数据还是有区别的,不建议列上允许为NULL。最好设置NOT NULL,并给一个默认值。(NULL列需要增加额外的空间去记录其值是否为NULL)
3.7 索引与排序
4.查询优化
4.1 慢查询定位
- 开启慢查询日志:如果一个sql执行的时间超过了它指定的一个时间,那么便把这条sql记录在慢查询日志中。
- 看慢查询日志是否开启:show variables like 'slow_query_log%'.
- 通过如下命令开启慢查询日志:
- set global slow_query_log = on;开启慢查询日志
- set global slow_query_log_file = 'OAK-slow.log'; 指定日志文件名
- set global log_queries_not_using_indexes = ON; 表示会记录没有使用索引的查询sql
- SET long_query_time = 10;指定慢查询的阈值,单位是秒。如果sql执行时间超过阈值,就属于慢查询,记录在文件中。
- 查询慢查询日志:mysqldumpslow工具;使用文本打开。
4.2 慢查询优化
查询是否使用了索引,只表示一个sql的执行过程,并不代表这个sql的执行效率,列入一个sql中where id = 1,这个就使用到了主键索引,而且是单值查询,此时效率就会高,但是如果where id > 0,即使存在主键索引,但由于还是范围查找,全表臊面,效率也还是没有提高。而慢查询日志关注的是sql的执行时间,一个sql一旦执行时间超过了指定的阈值,那么就会出现在慢查询日志中,即使一个sql使用了索引,但是它的效率不高执行不快的话,也是会出现在慢查询日志中。
我们在关注索引时,不要只关注到是否使用了,还要关注索引是否减少了扫描表的行数,如果扫描行数少了,那么效率才会得到提升。对于一个大表来讲,不仅仅要去创建索引,还是提高过滤性。过滤性好,执行效率才会高。
4.3 分页查询优化
三、Mysql事务和锁工作原理
1.ACID特性
- 原子性:一个事务里面,对数据的修改操作,要么全部执行,要么全部不执行。
- 持久型:一个事务一旦提交,那么对数据的修改将是永久的,后续的操作或者故障不应该对其有影响,不会丢失。
- 隔离性:不同事务之间互相独立互不影响,一个事务内部的操作及使用的数据对其他的并发事务是隔离的。
- 一致性:事务的开始和结束,数据库的完整性并未被破坏,一致性包括约束一致性和数据一致性。
2.事务控制的演进
2.1 并发事务
事务并发处理的一些问题:
- 更新丢失:当两个或多个事务更新同一行记录,会产生更新丢失现象。可以分为回滚覆盖和提交覆盖。
- 回滚覆盖:一个事务的回滚操作把其他数据提交的数据给覆盖了。
- 提交覆盖:一个事务的提交操作把其他数据的提交的数据给覆盖了。
- 脏读:一个事务读取到了另一个事务修改但为提交的数据。
- 不可重复读:一个事务多次读取同一条数据,发现读取出的数据不一致。(数据内容,由于其他事务在这个事务期间更新这条数据的内容)
- 幻读:一个事务中多次按相同条件查询,结果查询出的结果条数不一致,多了或者少了几行记录。(数据条数,由于其他事务在这个事务期间新增或者删除某些数据.注意,只能在事务一期间修改了事务二新增的那条数据,才会发生幻读,否则也不会发生。)
2.2 排队
完全顺序的执行所有事务的数据库操作,不需要加锁,简单的说就是全局排序。序列化的执行所有的事务单元,数据库的某一时刻只会执行某一个事务,符合强一致性,但是执行效率不高,处理性能低。
2.3 排他锁
支持并发的处理事务,如果两个事务处理中涉及到同一块的数据时,则会触发排他锁,或者叫互斥锁,先进入的事务会独占资源,其他的事务进入等到的一个状态,等它处理完后释放锁,另一个事务才会进入。
排他锁和排队的区别在于:排队是对于整个数据库操作而言,每次只要一个事务在进行,而排他锁使用时,可以支持多事务操作数据库处理不同的表数据,只有发生事务冲突(也就是两个事务操作同一块的表数据时),才会触发互斥锁,导致其他事务堵塞等待。【可以参考生活中上厕所的案例:排队就是卫生间每次只能有一个人,排他锁就是多坑位可以允许多个人,只有当坑位不够时,会导致其他人等待】
2.4 读写锁
读写锁可以让读和读的操作并行,读写,写读,写写还是要加排他锁。
2.5 MVCC(多版本控制)
使用的是copy on write的思想,除了支持读和读的并行,还支持读和写,写和读的并行,但是仍然不能保证写和写的并行。
MVCC被称为多版本控制,是很巧妙的产生多个版本,让事务可以看到自己应该可以看到的数据版本,将稀缺的独占资源互斥转化为并发,大大提高了系统的吞吐量和执行效率。
如何生成多版本?:每次事务操作之前,都会在undo日志中记录修改之前的数据状态和事务号,该备份记录可以用于其他事务的读取,也可以进行必要时的数据回滚。
快照读:读取的是记录的快照版本(可能是历史版本)不用加锁。
(理解:事务A修改了某条数据,但此时还未提交事务,事务B要读取这条数据,通过undo log拿到历史版本的数据,进行读取)
当前读:读取的是当前最新的版本,保证读的是当前返回的信息,需要加锁,让其他事务不会并发的修改这条记录。
(理解:事务A修改了某条数据,然后事务A在接下来的操作又读取这条数据,读取到的就是最新的修改的数据。)
MVCC的过程原理
- 事务一进来修改某条数据,将该数据进行加锁,然后将操作记录redo log
- 把该行修改前的值记录到undo log中
- 修改该行的数据,填写事务号,将回滚指针指向undo log中记录的那行记录
3.事务隔离级别
3.1隔离级别类型
- 读未提交:解决回滚覆盖类型的更新丢失,其他现象仍然可能发生。
- 读已提交(Read Commited):解决了脏读,不能解决不可重复读和幻读
- 可重复读:解决了不可重复读,但是仍然可能发生幻读
- 串行化:解决了幻读,但是导致了大量的超时和锁竞争,效率低下。
数据库的隔离级别越高,并发问题就越小,但是并发处理能力越差(代价)。
事务隔离级别,针对innodb支持事务的引擎。
事务隔离级别和锁的关系
- 事务隔离级别是sql92定制的标准,相当于事务并发控制的整体解决方案,本质上是对锁和MVCC使用的封装,隐藏了底部细节。
- 锁是数据库实现并发控制的基础,事务隔离采用锁来实现,对响应的操作加不一样的锁,可以防止其他事务同时岁数据进行操作。
- 对用户来讲,首先选择使用隔离级别,当选用的隔离级别没法解决并发的问题或者需求时,才有必要再开发中手动的设置锁。
mysql的默认隔离级别:可重复读
oracle的默认隔离级别是:读已提交
3.2 Mysql隔离级别控制
显示隔离级别:show variables like 'tx_isolation'
select @@tx_isolation
4.锁机制和实战
4.1 锁分类
- 从操作的粒度可以分为表级锁,行级锁和页级锁
- 表级锁:对整张表进行加锁,锁定力度大,发生锁冲突的概率最高,并发度最低。innodb,myisam,BDB使用
- 行级锁:对访问的某行数据进行锁定,锁定力度低,发生锁冲突概率最低,并发度最高。innodb使用
- 页级锁:每次锁定相邻的一组数据,锁定粒度在表级锁和行级锁之间,并发度一般。应用在BDB引擎中。
- 从操作的类型可分为读锁和写锁
- 读锁(s锁):共享锁,针对同一份数据,多个读操作可以同时进行而不会互相影响。
- 写锁(x锁):排他锁,当前的操作没有完成之前,它会阻断其他写锁和读锁。
- IS锁、IX锁:意向读锁、意向写锁,属于表级锁。S和X主要针对行级锁。在对表记录添加X和S锁之前,会先对表天剑IS锁和IX锁。
- 解释:事务A对记录添加了S锁,可以进行读操作,不能进行修改操作。其余的事务可以对该记录追加S锁,但不能追加X锁,如果想追加X锁的话,要等所有的S锁释放之后;;;事务A对记录添加了X锁,可以对该记录进行读操作和写操作,其余的事务不能同时对记录进行读和写的操作。
- 从操作的性能可分为乐观锁和悲观锁
- 乐观锁:一般的实现方式是对记录数据版本进行比对,在数据更新提交的时候才会进行冲突检测,如果发现冲突了,则提示错误信息。
- 悲观锁:在对一条数据进行修改的时候,为了避免同时是被其他人修改,在修改数据前采用先绑定,再修改的控制方式。共享锁和排他锁是悲观锁的不同实现,但都属于悲观锁的范畴。
4.2 行锁原理
4.3 悲观锁
悲观锁,是指在数据处理的过程中国,将数据处于锁定状态,一般使用数据库的锁机制实现。从广义上来看,行锁,表锁,读锁,写锁,共享锁,排他锁,都属于悲观锁的范畴。
- 表级锁 (加读锁:
lock table 表名 read;,查看表加过的锁:show open tables,删除表锁:unlock tables)- 表级读锁:当前表追加读锁,当前连接和其他的连接都可以进行读操作;但是当前连接修改操作会报错,其他连接修改操作会阻塞等待
- 表级写锁:当前表追加写锁,当前连接可以进行读和修改的操作,但是其他连接读和修改的操作都会进入阻塞等待状态。
- 行级锁
- 共享锁(行级锁-读锁)【sql:
select * from where deptno=1 lock in share mode】总结:事务使用了共享锁,只能读取,不能修改,其他事务可以重复加读锁。 - 排他锁(行级锁-写锁)【sql:
select * from where deptno=1 for update】总结:事务使用了排他锁,当前事务可以读取和修改,但是其他的事务不能够读取和修改操作。
- 共享锁(行级锁-读锁)【sql:
行级锁的实现其实是依靠其对应的索引,所以说如果操作没用到索引的查询,那么会锁住全表记录。
4.4 乐观锁
悲观锁和乐观锁都可以解决事务写写并发,在应用中可以根据并发处理能力区分,比如对并发率要求高的选择乐观锁;对于并发率要求低的可以选择悲观锁。
- 乐观锁实现原理
- 使用版本字段(version)先给数据表新增一个版本号字段,每次操作都会将版本号加一,每次更新提交的时候将检查版本号和数据库表的版本号。(hibernate封装了乐观锁的机制)
- 使用时间戳
4.5死锁与解决方案
-
表锁死锁:
产生原因:用户A访问A表,锁住了A表,然后又访问表B;另一个用户B访问B表,锁住了B表,然后又访问A。A和B用户互相等待对方释放锁,引发了死锁。
解决方案:调整程序逻辑,尽量按照相同的顺序执行。
-
行级锁死锁:
产生原因一:在事务中执行没有索引的条件的查询,引发了全表扫描,把行级锁上升为了全表记录锁定(等价于表锁),多个这样的事务发生之后,就容易产生了死锁和阻塞。
解决方案一:不要使用太多的连表查询,使用explain关键字分析sql,必要时添加索引。
产生原因二:两个事务分别想拿到对方持有的锁,互相等待,于是产生死锁。
解决方案二:1.同一个事务,尽可能的做到一次锁定所需要的所有资源。 2.按照id对资源进行排序,然后按照顺序进行处理。
-
共享锁转换为排他锁
产生原因
事务A:select * from dept where deptno = 1 lock in share mode;// 共享锁1
update dept set dname = 'java' where deptno=1;//排他锁,3 【由于B有一个排他锁在等待,所以也没法获取一个排他锁,引发了死锁】
事务B:update dept set dname='java' where deptno=1;//由于A有共享锁,没发货区到排他锁,需要等待。 2
解决方案?1.不让用户重复点击,避免引发同时对同一条记录多次操作。2.使用乐观锁进行控制。
- 死锁排查
- 查看死锁日志:
show engine innodb status - 查看锁状态变量:
show status like 'innodb_row_lock%'- Innodb_row_lock_current_waits:当前正在等待锁的数量
- Innodb_row_lock_time:从系统启动到现在锁定总时间长度
- Innodb_row_lock_time_avg: 每次等待锁的平均时间
- Innodb_row_lock_time_max:从系统启动到现在等待最长的一次锁的时间
- Innodb_row_lock_waits:系统启动后到现在总共等待的次数
- 查看死锁日志:
四、Mysql集群架构及相关原理
1.集群架构设计
应用架构演变
- 单一架构
- 缺点:数据量太大,超出一台服务器承受;读写操作量太大,超出一台服务器承受;一台服务挂了,应用也会挂掉。
2021/4/23 10:42:22 2021/4/23 10:42:24
- 缺点:数据量太大,超出一台服务器承受;读写操作量太大,超出一台服务器承受;一台服务挂了,应用也会挂掉。
- 主从架构
- 优点:主库可以抗住写的压力,从库承受读的压力,保证了高可用。
- 缺点:数据量太大,超出一台服务器承受;写操作太大,超出一台服务器承受。
- 分库分表
- 优点:水平拆分每个实例拥有全部数据的1/n,解决数据量大的问题。
- 缺点:如何保持数据一致性。
- 云数据库:将mysql做成一个saas服务,服务提供商负责解决可配置性,可扩展性,多用户存储结构设计等这些疑难问题。
2.主从模式
2.1 主从复制适用场景
主从复制用途
- 实时灾备,用于故障切换 - 高可用
- 读写分离,提供查询服务 - 高扩展
- 数据备份,避免影响业务 - 高可用
主从复制部署条件
- 从库数据库能连接主库
- 主库要开启binlog日志(设置log——bin参数)
- 主从server-id不同
2.2 主从复制实现原理
2.2.1 主从复制
主从复制的步骤
- 主库将数据库信息的变更记录到binlog日志中
- 从库读取主库的binlog日志,将信息写入relay log中继日志中
- 从库读取relay log中继日志从库中进行replay,将信息变更到自己的数据库中
涉及到的线程
- Master服务将数据库信息的变更记录写入到binlog日志中,BinLogDump Thread将binlog日志中的内容传递给Slave的IO Thread。
- Slave服务的IO Thread将接收到的信息内容写入到relay log中继日志中
- Slave服务的SQL Threa读取relay log,解析relay log的内容,放在自己服务器上执行
主从复制可能存在的问题
- 主库宕机后,数据可能会丢失 (binlog日志信息还没完全同步到从库的中继日志中就挂掉了)
- 从库只有一个Sql Thread,主库的写压力大,复制很有可能延迟。
针对主从复制存在的问题想到的解决方案
- 半同步复制 - 解决数据可能丢失的问题
- 并行复制 - 解决重复复制延迟的问题
2.2.2 半同步复制
2.3 并行复制
主从数据库搭建过程
-
阶段一:准备过程
1.准备两台服务器:132和130,其中130作为master,132作为slave。
2.使用rpm 安装包。tar -xvf mysql安装包。
3.检查mariadb :rpm -qa|grep mariadb
4.如果存在mariadb的话将进行移除:rpm -e mariadb-libs-5.5.41-2.el7_0.x86_64 --nodeps,避免干扰
5.rpm -ivh mysql-community-common-5.7.28-1.el7.x86_64.rpm
6.rpm -ivh mysql-community-libs-5.7.28-1.el7.x86_64.rpm
7.rpm -ivh mysql-community-libs-compat-5.7.28-1.el7.x86_64.rpm
8.rpm -ivh mysql-community-client-5.7.28-1.el7.x86_64.rpm
9.rpm -ivh mysql-community-server-5.7.28-1.el7.x86_64.rpm
10.rpm -ivh mysql-community-devel-5.7.28-1.el7.x86_64.rpm
11.将mysql实例化:mysqld --initialize --user=mysql
12.cat /var/log/mysqld.log 查看密码
13.启动mysql服务:systemctl start mysqld.service
14.systemctl status mysqld.service 查看mysql服务的状态
15.mysql -u root -p 登录mysql set password=password('root')修改密码
16.systemctl stop iptables 将iptables关闭
17.systemctl stop firewalld 将防火墙关闭
18.systemctl disable firewalld.service 将防火墙禁掉,防止自己启动
-
阶段二:主从配置
1.进入到主库服务器 :cd etc -- 进入etc文件夹下
2.vi my.cnf 【开bin_log功能:log_bin=mysql-bin server-id=1 sync-binlog=1(开启同步,每次执行写入性操作都与磁盘同步) binlog-ignore-db=information_schema(忽略指定的库不再同步,可以配置多个)】
3.systemctl reatart mysqld 重启mysql服务
4.开启mysql 授权,先进入mysql主库。然后执行命令:grant replication slave on?.?to 'root'@'%' identified by 'root'; 授权
5.grant all privileges on?.?to 'root'@'%' identified by 'root';
6.flush privileges;刷新授权操作
7.show master status;查看数据库的状态
8.进入从库的配置。同样修改my.cof 【server-id=2 relay_log=mysql-relay-bin read_only=1】
9.重新启动从库,使修改的配置生效。
10.查看从库的状态:show slave status;
11.change master to master_host='192.168.95.130',master_port=3306,master_user='root',master_password='root',master_log_file='mysql-bin.000002',master_log_pos=869;//设置与master的连接命令,针对binlog文件;
12.对主库进行一些操作,看一下从库有没有记录数据。
13.追加从库的话,需要把历史数据给同步过去:
mysqldump --all-databases > mysql_backup_all.sql -uroot -p 将数据生成sql文件。
半同步复制实战
-
主库
1.查看是否支持动态的加载:select @@have_dynamic_loading;
2.show plugins;查看可支持的插件
3.install plugin rpl_semi_sync_master soname 'semisync_master.so';安装插件
4.show variables like '%semi%';查看半同步复制
5.设置开启半同步复制功能:
set global rpl_semi_sync_master_enabled=1;set global set global rpl_semi_sync_master_timeout=1000; -
从库
1.install plugin rpl_semi_sync_slave soname 'semisync_slave.so'; 安装插件
2.set global rpl_semi_sync_slave_enabled=1;3.stop slave; start slave;
在var文件夹下,查看mysql.log,就能看到我们的执行日志。
并行复制实战
-
主库
1.show variables like '%binlog_group%';
2.set global binlog_group_commit_sync_delay=1000;每组同步提交延迟设置
3.set global binlog_group_commit_sync_no_delay_count=100;一个组里面有多少事务数 -
从库
1.show variables like '%slave%'
2.set global slave_parallel_type='LOGICAL_CLOCK';// 设置
3.set global slave_parallel_workers =8;// 设置线程数
4.show variables like '%relay_log%';5.set global relay_log_recovery=1; 【可读模式下需要进入my.cnf中添加属性】
set global relay_log_info_repository='table';
?
2.4 读写分离
主从同步延迟问题解决方案:
- 写后立即读:写操作完成的一段时间内,读操作去主库中,等过了这段时间后,读操作去从库中。
- 二次查询:读请求来了之后先去从库中读,如果从库中没有再去请求主库,这样做相当于把读压力又返还给了主库。为了避免恶意攻击,建议对数据库访问API进行封装,可以有效的提高安全性,降低耦合度。
- 根据业务划分:对于一些经常用到的业务,,实时性要求比较高的,读写操作都可以在主库。而将一些冷门业务,不经常用到的,实时性要求不高,可以去从库中读。这需要开发人员根据业务进行判断。
读写分离实战 - 借助中间件
1.新增一台主机134:proxy (记着关闭防火墙等操作)
2.下载mysql-proxy-0.8.8.5-linux-el6-x86-64bit.tar.gz
3.tar -xzvf mysql-proxy-0.8.8.5-linux-el6-x86-64bit.tar.gz
4.vim /etc/mysql-proxy.cnf :
[mysql-proxy]
user=root
admin-username=root //用户名
admin-password=root //密码
proxy-address=192.168.95.134:4040 // 代理服务的地址
proxy-backend-addresses=192.168.59.130:3306 //设置写库的地址
proxy-read-only-bankend-addresses=192.168.95.132:3306,ip:port,ip:port // 设置读库的地址
proxy-lua-script=/root/mysql-proxy-0.8.8.5-linux-el6-x86-64bit/share/doc/mysql-proxy/rw-splitting.lua //指定lua脚本运行位置
log-file=/var/log/mysql-proxy.log //日志位置
log-level=debug //日志级别
daemon=true //进程方式,后台进行
keepalive=true //是否尝试重启
5.chmod 660 /etc/mysql-proxy.cnf //指定文件权限:可读可写
6.修改lua脚本的最小连接数为1,方便后续测试看到效果:vim mysql-proxy-0.8.8.5-linux-el6-x86-64bit/share/doc/mysql-proxy/rw-splitting.lua
7.cd mysql-proxy-0.8.8.5-linux-el6-x86-64bit/bin 进入到bin路径下,开始启动 ./mysql-proxy --defaluts-file=/etc/mysql-proxy.cnf
3.双主模式
3.1 适用场景
概念:双主模式是指两台服务器互为主从,其中任意一台的数据发生变更,都会同步到另外一台服务器的数组库。
使用双主双写还是双主单写:?建议使用双主单写,原因是双主双写存在以下问题:
- ID冲突:如果在A表写入某些数据,数据同步到B表时还没结束,此刻再从B表写入,假设此时ID是自增的话,就容易和从A表同步过来的数据发生ID冲突。(可以采用mysql自动增长步长来解决问题,但是这样对数据库的扩展和运维都不太又好)
- 更新丢失:同一条记录在两个主库中进行更新,会发生前面的覆盖掉后面的更新。
双主模式实战:
1.在之前配置的master主机上进行修改,vim /etc/my.cnf
relay_log=mysql-relay-bin
log_slave_updates=1
#如果是双主双写,为了避免id冲突,可以设置下面两个参数,id从1开始,以2递增
auto_increment_offset=1
auto_increment_increment=2
2.重新启动mysql,systemctl restart mysqld
3.进入mysql命令端,show master status
4.开始配置另外一台新的master,重复之前的操作。show master status;
5.开始指定master1和master2互相复制。以下操作master1和master2都要指定,互相进行指定。
6.change master to master_host='192.168.95.133',master_port=3306,master_user='root',master_password='root',master_log_file='mysql-bin.000001',master_log_pos=884;
然后启动slave:start slave;
测试:create table test1(id int primary key auto_increment,name varchar(20))engine=innodb charset=utf8;
3.2 MMM架构
3.3 MHA架构
3.4 主备切换
五、互联网海量数据处理实战
六、Mysql第三方工具实战
七、MySql性能优化
1.系统配置优化
1.1 保证从内存中读取数据
mysql会在内存中保存一些数据,通过LRU算法将一些不常用的数据写入到磁盘中。要尽可能的扩大内存的数据存储,这样的话会提高查询效率。
默认mysql的使用内存存储数据大小为125M,要根据场景需要,如果某台服务器只是用来部署mysql的,可以将mysql的使用内存大小调整到总内存的3/4或者4/5甚至更多,如果这台服务器还部署了其他的应用程序,那就不宜调整那么高,根据实际情况尽可能的多调整。
调整步骤:
- 通过命令
show global status like‘innodb_buffer_pool_pages_%’可以查看innodb_buffer_pool的一些参数当前状态,假如看到了innodb_buffer_pool_pages_free = 0表示内存已经用光。 - 修改my.cnf文件。加入:
innodb_buffer_pool_size = 750M表示将mysql内存使用空间扩大到了750M。
1.2 数据预热
默认情况下,只有当数据被读取过一次后,才能将数据缓存在innodb_buffer_pool中。
因此我们可以将数据进行预热,在mysql启动时就将硬盘中所有的数据加载到内存中,数据预热能够提高查询的效率。
(1)数据预热的脚本
SELECT DISTINCT
?CONCAT('SELECT ',ndxcollist,' FROM ',db,'.',tb,
??' ORDER BY ',ndxcollist,';') SelectQueryToLoadCache
??FROM
?(
????SELECT
?????engine,table_schema db,table_name tb,
?????index_name,GROUP_CONCAT(column_name ORDER BY seq_in_index)
ndxcollist
????FROM
???(
??????SELECT
???????B.engine,A.table_schema,A.table_name,
???????A.index_name,A.column_name,A.seq_in_index
??????FROM
???????information_schema.statistics A INNER JOIN
???????(
??????????SELECT engine,table_schema,table_name
??????????FROM information_schema.tables WHERE
?????????engine='InnoDB'
???????) B USING (table_schema,table_name)
??????WHERE B.table_schema NOT IN ('information_schema','mysql')
??????ORDER BY table_schema,table_name,index_name,seq_in_index
???) A
????GROUP BY table_schema,table_name,index_name
?) AA
ORDER BY db,tb;
将该脚本保存为loadtomem.sql
(2)执行命令
mysql -uroot -proot -AN < /root/loadtomem.sql > /root/loadtomem.sql
(3) 在需要数据预热时,重启数据库
mysql -uroot < /root/loadtomem.sql > /dev/null 2>&1
1.3 降低磁盘的I/O次数
(1) 增大redo_log,减少落盘次数
将innodb_log_file_size设置成0.25 * innodb_buffer_pool_size
(2) 生产中不开启慢查询日志,只有遇到问题时才开启慢查询日志排查问题。
(3) 写redo_log策略innodb_flush_log_at_trx_commit设置为0和2
如果不涉及安全性比较高的金融系统操作,或者事务要求都特别小,是可以将redo_log的策略设置为0或者2,以减少I/O次数
1.4 提高磁盘的读写能力
使用SSD或者内存硬盘
2.表结构设计优化
2.1 设计中间表
一般针对于统计类型的功能,实时性不高的可以设计中间表。
2.2 设计冗余字段
为了减少表之间的关联,应适当的增加一些冗余的字段,可以有效的提高查询效率。
2.3 拆表
对于单表中的字段太多(比如一个表中有100条数据)可以进行拆表,如果不经常使用的一些属性以及存储数据较多的一些字段,可以单独拆出一个表来。
2.4 主键优化
每张表建议都要有一个主键(主键索引),建议设置为int类型,自增原则(不考虑分布式场景下时可如此,分布式下建议使用雪花算法。)
2.5 字段的设计
数据库的表越小,那么在它上面执行查询效率也就越高。
因此再给数据库表字段设置宽度时尽可能的设计的小。
另外,尽量把字段设置为NOT NULL,这样表中不存在NULL值,在查询的时候就不需要单独再去比较NULL值了,mysql中的NULL值查询很耗费资源。
对于一些省份等字段,可以考虑将字段设置为ENUM属性,因为在mysql数据库中,ENUM属性的查询和数值效率差不多高,要高于varchar类型,下面将写一段关于ENUM类型使用的代码。
# 首先我本地数据库中存在这么一个表格persion3,它的原本字段有(id,name,sex,address,time)
# 首先创建该类型的值时要初始化几个值,比如要增加province字段时,默认要在山东,河南,江苏中选择城市
alter table persion3 add column province enum('山东','河南','江苏') collate utf8_bin default NULL comment '省份' after time;
# 然后新增一条数据时,需要在enum定义的组里面写
insert into persion3 values('1','zae',1,'北京',now(),'山东')
# 下面演示一种错误的写法,因为山西没有在ENUM中定义
insert into persion3 values('1','zae',1,'北京',now(),'山西')
另外,设置字段时能用数值的就用数值,例如sex可以使用0或者1
3.sql语句以及索引优化
4.Mysql开发规约
5.复杂sql优化实践
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!