31、杭州电子科技大、深圳大数据研究院、港中文第二附属医院提出:SCUNet++,堪称完美的缝合设计[太美丽家人们!]
本文由1杭州电子科技大学,2深圳大数据研究院,3香港中文大学第二附属医院于2023年12月22日发表于arXiv<Electrical Engineering and Systems Science?>。
论文:
《SCUNet++: Assessment of Pulmonary Embolism CT Image Segmentation
Leveraging Swin-UNet and CNN Bottleneck Hybrid Architecture with
Multi-Fusion Dense Skip Connection *》
肺栓塞(PE)是一种常见的肺部疾病,在严重情况下可能导致右心室肥厚和衰竭,仅次于心肌梗死和突然死亡,其诊断方法之一是肺动脉CT血管造影(CTPA)。然而,在临床实践中,由于成像技术的限制,PE检测存在挑战。CTPA可能产生类似于PE的噪声,这使得其存在的时间较长,且易导致过度诊断。然而,传统的PE分割方法无法充分考虑特征的分层结构,以及PE CT图像的局部和全局空间特征。
在本文中,作者提出了一种自动PE分割方法,称为SCUNet++(Swin Conv UNet++)。这种方法在编码器和解码器之间利用多个密集跳跃连接,并使用Swin Transformer作为编码器。同时,在解码子网络中融合不同尺度的特征,以补偿由于在Swin-UNet或其他最先进方法中的下采样所引起的空间信息损失,有效解决了上述问题。作者对这种方法进行了详细的理论分析,并在公开可用的PE CT图像数据集FUMPE和CAD-PE上进行了验证。
实验结果显示,作者提出的方法在FUMPE数据集上达到了Dice相似系数(DSC)的83.47%和Hausdorff距离95th百分位(HD95)的3.83,在CAD-PE数据集上达到了DSC的83.42%和HD95的5.10。这些结果表明,作者的方法在PE分割任务上表现出强大的性能,可能增强PE的自动分割准确性,并为临床医生提供强大的诊断工具。
论文地址:
代码地址:
https://github.com/JustifC03/SCUNet-plusplus
1 Introduction
肺栓塞(PE)是一种严重的生命威胁疾病,由血管内血栓脱落引起,阻塞肺动脉或其分支。栓子的大小决定了其分类为中央、叶状、段状或亚段状肺动脉。较小的栓子可能表现出轻微的症状或胸闷,而较大的栓子可能导致晕厥或突然死亡。这是因为血栓阻塞肺动脉,导致患者血管狭窄或堵塞,从而增加肺血管阻力,提高肺动脉压力,仅次于心肌梗死和突然死亡,排名第二。随着年龄的增长,肺栓塞的发病率上升,如果没有积极治疗,其死亡率将接近30%。然而,通过及时和适当的干预,这一比例可以降低到2%到11%。一个重要的临床挑战是在最小化与假阳性诊断相关风险的同时,迅速和准确地诊断肺栓塞。
CTPA是肺栓塞(PE)的主要诊断方法。在CTPA中,对比剂在血液中溶解,使血管呈现明亮,而栓子不会吸收对比剂,因此在CT图像中形成代表PE的暗区。根据放射科医生的经验,PE的 Voxel 值通常在-50 HU到100 HU之间,表示图像亮度水平。放射科医生通过仔细追踪每个动脉分支来使用这个特征来筛查PE。然而,PE诊断是一个非常复杂的任务,有几个原因:
-
首先,患者可能有数百或数千张CTPA图像,每张图像代表肺的切片。重复的图像阅读可以消耗医生大量的时间和精力,增加了误诊的风险。
-
其次,CTPA图像可以受到成像技术和因素的影响,如呼吸运动伪影、淋巴结和血管分支,引入了噪声干扰。
-
最后,CTPA需要高度的专业知识,医生对CTPA理解不足可能导致诊断延误和病例遗漏。为了应对这些挑战,计算机辅助检测(CAD)是放射科医生的重要工具。CAD可以实现准确检测和诊断PE,同时减少CTPA阅读时间,从而提高整体诊断效率。
在本文中,作者从临床角度出发,学习医生如何根据其特征在CT图像中定位肺栓塞(PE),并提出了一种肺栓塞分割方法,称为SCUNet++。该方法专注于CTPA图像,并融合了UNet++的优势、多个融合密集跳跃连接、Swin-Transformer注意力机制和Swin-UNet方法,并对网络进行了一些改进,以增强网络的分割准确性和稳定性。本文的主要贡献如下:
作者已经整理了一个为肺栓塞(PE)标注的CT图像数据集。在医疗专业人士的协作下,作者的团队仔细分析了公开可用的FUMPE和CAD-PE数据集。这些检查发现原始数据集标注中存在大量的不准确和不一致之处。作为纠正措施,作者承担了重新标注这些数据集的任务,以确保其准确性。此外,为了方便其他用户的访问和使用,作者在作者的GitHub仓库中提供了可下载的修正后的FUMPE数据集链接。
作者研究了将UNet++卷积神经网络与skip连接、Transformer注意力机制和Swin-UNet纯Transformer U-形状神经网络模型相结合的融合方法。这种集成方法导致了分割精度的提高。
引入了一个瓶 Neck ,该模块利用CNN块来解决Swin-Transformer块在从图像中提取局部空间特征方面的不足。这一有策略的添加随后导致了模型整体性能的提升。
2 Related Work
传统的医学图像分割方法主要依赖计算机图形学和机器学习技术进行分割。更成熟的方法包括基于阈值的图像分割,利用区域特征相似性的区域图像分割,使用边缘检测算子进行边界分割,以及基于曲线演化的轮廓分割。然而,传统的医学图像分割方法主要依赖图像像素的低级视觉特征。由于器官形状和轮廓的巨大变化,分割结果可能在实际应用中波动或下降,这使得在分割目标复杂度增加时确保足够的准确性变得具有挑战性。因此,传统的医学图像分割方法在提高分割准确性方面效果有限。
随着机器学习的广泛应用,医学图像处理中卷积神经网络的应用也得到了扩展,主要分为两类:分类和分割。
对于分类任务,杨等人设计了一种使用3D CTPA图像的肺栓塞(PE)检测两阶段模型。首先,提出候选区域,然后提取与血管对齐的3D候选区域。
接下来,根据血管对齐立方体的2D横截面和ResNet-18分类器移除非阳性。黄等人[8]提出了一种端到端的扩展深度学习模型PENet,该模型使用 Voxel CT成像来自动诊断PE。Huhtanen等人[9]提出的CNN-LSTM架构包括一个Inception-ResNet v2 CNN架构和一个处理CTPA堆叠整个切片序列的长短时记忆网络。这种架构在利用弱标记训练数据从CT肺动脉造影中检测PE方面表现出出色的性能,表明深度学习在任务中的潜力。Shi等人[10]提出了一种注意引导的PE自动检测模型,该模型包括两个阶段。
在第一阶段,在有限数量的像素级标注图像切片中训练2D卷积网络。在第二阶段,根据患者 Level 获得PE预测。Suman等人提出了一种基于注意机制的CNN-LSTM网络,包括两部分:一个捕捉图像属性和标签的CNN分类器和一个学习切片间依赖关系的序列模型。CNN为每个切片提取特征,具有注意机制的序列模型将这些空间特征和捕获到的长程依赖性结合在一起,为每个CT切片提供全局变化信息。
对于分割任务,近年来已经提出了几种基于深度学习的计算机辅助诊断研究方法来分割肺栓塞(PE)。袁等人提出了一种ResD-Unet架构,通过结合UNet网络、新的Residual-Dense块和混合损失函数,实现了肺动脉分割的高准确性和效率,解决了估计PE严重程度方面的挑战。郭等人提出了一种动脉意识的3D全卷积网络AANet,用于检测PE,解决了CTPA图像中出现许多分支的暗斑区域中检测PE的挑战。
然而,由于肺动脉层结构的复杂性、分支的存在以及每个层中每个个体大小和生长方向的巨大变化,分割肺动脉栓塞检测比其他病变检测(如肺结节)更具挑战性。因此,根据PE CT的特性选择合适的网络结构是一个值得进一步研究的话题。
上述提到的研究方法为本文提供了有价值的参考和启示,为后续研究提供了方向。然而,目前国内外的肺栓塞诊断研究主要集中在疾病存在与否的二分类检测上,自动分割PE的研究较少。基于U型结构的卷积网络在医学图像任务中很常见。尽管它们有用,但卷积网络存在固有的局限性,阻碍了其有效地学习全局信息,特别是在处理许多小病变(如PE)的情况下。这个问题在UNet和UNet++网络模型中未被解决。
相比之下,Swin-UNet通过引入 Short-Cut ,在Transformer-based U-shaped En-Decoder架构中重新引入分块图像,实现了全局语义特征学习。然而,Swin-UNet在尝试实现上采样过程中的详细分割结果时,也面临其自身的挑战。这是由于其完全依赖纯Transformer结构,而没有采用卷积操作。因此,该模型在PE CT图像分割过程中容易受到其他病变(如结节)、肺组织其他成分和噪声的干扰。
根据上述发现,本文提出将类似于UNet++的多融合密集跳跃连接引入到Swin-UNet模型结构中。这种集成使得可以从Swin-UNet模型结构中有效地合并不同深度的下采样特征图。因此,模型可以同时关注上下文信息和空间视觉信息。

此外,不同深度的特征图可以部分共享相同的编码器,并通过深度监督进行联合反馈学习。为了补偿Swin Transformer模块在瓶颈层中缺乏局部空间特征提取的问题,本文还提出将Swin-UNet的原始瓶颈层替换为卷积模块。混合架构模型能够有效地提取图像的局部空间特征以及整体全局特征,并组合深度和浅层语义信息以准确识别PE的分割,如图1所示。
3 Method
3.1 Overview of the Architecture
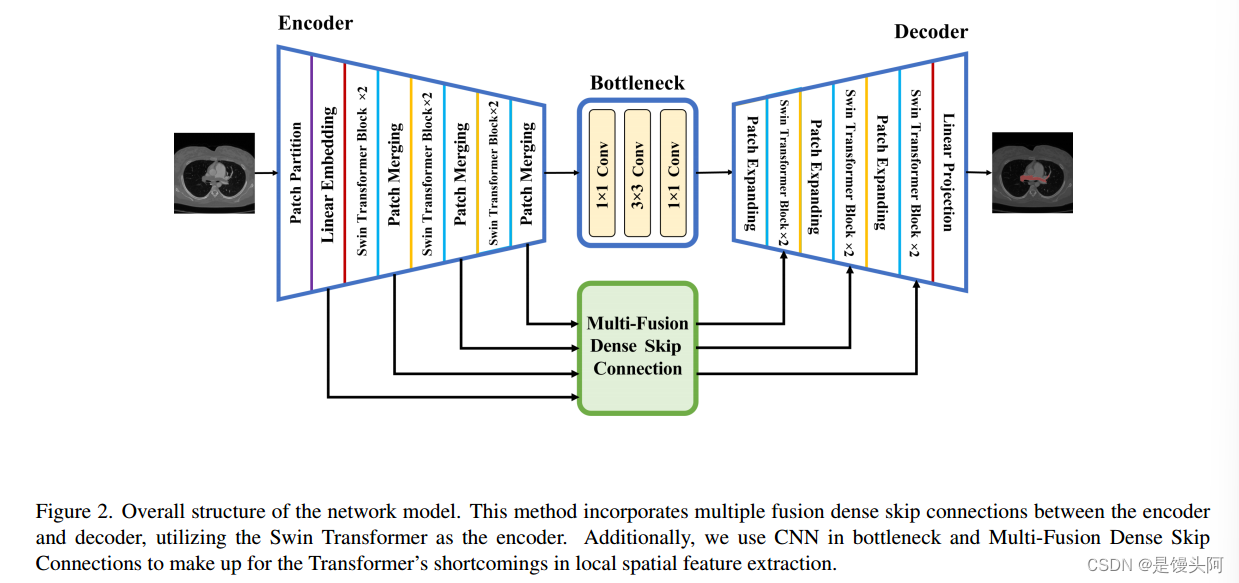
本文提出的SCUNet++模型的整体结构如图2所示。该模型包括四个主要模块:编码器模块、CNN-Neck 、解码器模块和多融合密集跳跃连接模块。
对于编码器模块,图像被转换为序列嵌入,CT切片被划分为大小为W*H的非重叠块,然后通过线性嵌入层将特征维度投影到C维度。经过一系列Swin Transformer块和像素合并层的处理后,生成层次特征表示。像素合并层负责降采样和维度增加,而Swin Transformer块负责特征表示学习。
编码器之后,特征图被输入到CNN瓶 Neck ,该模块采用CNN块进行替代构建,以弥补Swin Transformer块在图像局部空间特征提取方面的不足。
多融合密集跳跃连接模块,受UNet++跳跃连接方法启发,添加在解码器和编码器之间,基于Swin Transformer块。它通过多融合密集跳跃连接将提取的上下文特征与来自编码器的多尺度特征融合,以补偿由降采样引起的空间信息损失。解码器模块包括一个Swin Transformer块和像素扩展层。像素扩展层将相邻维度的特征图扩展为大特征图,其分辨率为2*上采样,而Swin Transformer块负责特征表示学习。
最后,使用最后一个像素扩展层进行四倍上采样,恢复特征图的分辨率到输入分辨率(W*H),然后应用线性投影层进行像素级分割预测。
3.2 Double Swin-Transformer Block
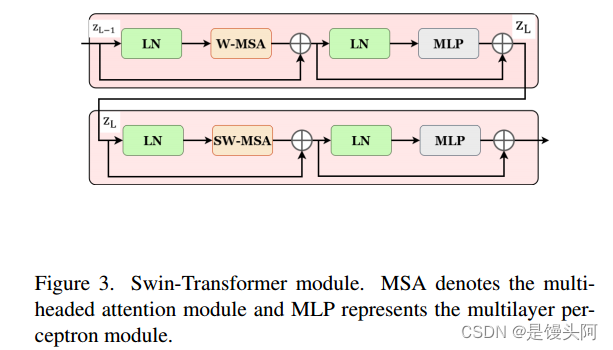
如图3所示,Swin-Transformer块基于位移窗口构建,这与传统的多头自注意力(MSA)模块有所不同。本文提出的双Swin-Transformer块包括两个连续的Swin-Transformer块。每个Swin-Transformer块包括一个LN层、一个MSA模块、一个残差连接和一个包含两个MLP层的GELU非线性激活函数的层。
此外,作者应用了基于窗口的多头自注意力(W-MSA)模块和基于位移窗口的多头自注意力(SW-MSA)模块到这两个连续的Swin-Transformer块,分别进行处理。这种方法增强了模型捕捉长程依赖性和学习全局和远程语义信息交互的能力。
3.3 Encoder
编码器基于双Swin-Transformer块构建:
-
首先,将图像转换为序列嵌入,并将W*H*3切片划分为大小为4*4的非重叠块,因此每个块的特征维度为4*4*3=48。线性嵌入层将特征维度映射到C。
-
然后,将大小为H/4*W/4*C的特征作为两个连续的Swin-Transformer块的输入,用于学习特征表示。
-
最后,通过像素合并层将下采样因子为2,以减少表示数量并加倍特征维度。因此,在像素合并层完成了维度和分辨率的变化。编码器重复这个过程三次,每次都包括两个Swin-Transformer块和一个像素合并层。
3.3.1 Patch Merging Layer
当根据行和列的奇偶性组合像素点时,有四种可能的组合。因此,输入的像素块可以分为四个部分,并使用像素合并层将这四个部分合并。这样,特征分辨率减半为原始分辨率的1/2。由于合并操作将特征维度增加到原始维度的四倍,之后应用线性层将特征维度减少到原始维度的1/2。
3.3.2 Bottleneck (CNN Block)
使用仅Swin-Transformer块来构建图像中提取局部空间特征的瓶颈可能是不够的。因此,作者试图使用CNN块替换原始瓶颈,以充分学习深度特征表示,并弥补网络在提取图像中局部空间特征方面的不足。CNN块包括一个网络结构,其中使用了一个
![]()
序列,每个卷积前后都应用了BN-ReLU操作。在瓶颈中,特征大小和分辨率保持不变,以确保特征表示的一致性。
3.4 Decoder
解码器的结构与编码器相同。在解码器中,像素扩展层对提取的深度特征进行2倍上采样,并将相邻维度的特征图 Reshape 为更高分辨率的特征图。相应地,特征维度减半为原始维度的1/2。
3.4.1 Patch Expanding Layer
以第一个像素扩展层为例,在升采样过程之前,对输入特征(W/32*H/32*8C)应用线性层。这一操作旨在放大特征维度,将其加倍(W/32*H/32*16C)。在此之后,通过重新排列操作,输入特征的分辨率提高到初始输入分辨率的2倍。相反,特征维度减少到初始输入特征维度的四分之一。
3.4.2 Multi-Fusion Dense Skip Connection
受到UNet++的 Short-Cut 概念的启发,SCUNet++使用多融合密集 Short-Cut 方法在解码器子网络中实现聚合语义缩放和高度灵活的编码器特征。
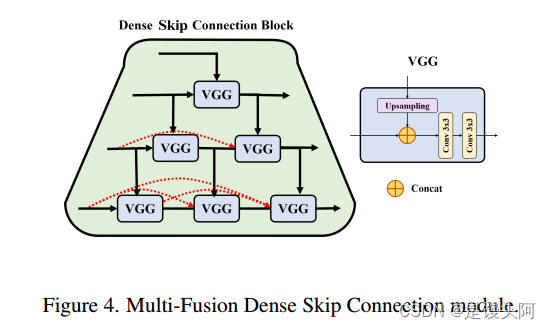
如图4所示,所提出的模型采用密集连接,通过引入嵌套和密集多融合密集 Short-Cut 实现长和短连接的结合。此外,还添加了一个卷积结构,用于填充模型中心空洞,以补偿由于Swin-UNet纯Transformer结构导致的图像特征提取细节缺失。这种策略有效地减少了编码器和解码器之间的语义差距,同时捕捉各种 Level 的特征和不同大小的感知场,以获得更丰富的多尺度信息。
因此,作者的模型可以有效地提取CTPA图像的局部空间特征和整体全局特征,集成深度和浅层语义信息,并执行缝合处理,以最小化降采样过程引起的空间信息损失。
4 Experiment
4.1 Dataset
如图5所示,作者使用公开可用的FUMPE和CAD-PE数据集进行了实验。作者只选择了固定角度的肺栓塞图像及其对应的标签。由于FUMPE数据集的初始标注结果存在不准确之处,作者与医学专业人士合作,对数据集进行了审查和重新标注。

在经过全面审查后,作者最终得到了35名患者获得的8,792张CTPA图像,这些图像的标注由医生提供。CAD-PE数据集中包含91张CTPA图像,其中所有血栓都由有经验的放射科医生在每次扫描中分割。经过筛选后,CAD-PE数据集包含8,900张CTPA图像,这些图像都是肺栓塞的。同时,作者对两个数据集的图像大小进行了标准化,都为512512像素,并将每个肺栓塞病例按9:1的比例分为训练和测试。
5?Ablation Study

在本节中,如图7所示,作者通过消融实验评估了跳跃连接和CNN块对模型分割性能的影响。
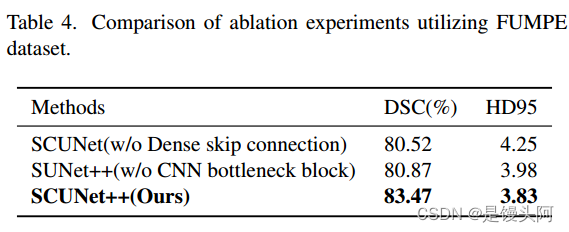
如表4和表5所示,作者通过比较在测试集上的Dice值,对以下配置进行了评估:没有(w/o)密集跳跃连接,没有CNN块,以及完整的SCUNet++模型。
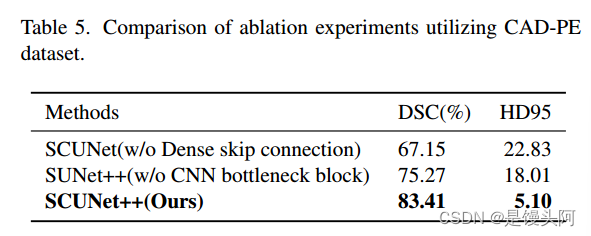
在CAD-PE数据集中,当作者在SCUNet的基础上添加密集跳跃连接模块时,DSC从67.15%提高到83.41%,HD95从22.83降低到5.10。这表明,由于去除了密集跳跃连接模块,分割效果不满意,因为编码器和解码器之间存在语义差距。当作者在SUNet++的基础上添加CNN瓶 Neck 时,DSC从75.27%提高到83.41%,HD95从18.01降低到5.10。这表明,由于去除了CNN瓶 Neck ,图像的局部空间特征提取不足,因为只使用了Swin-Transformer块来构建瓶颈,这将导致图像局部空间中特征提取的不足。
同时,作者在FUMPE数据集上也进行了类似的消融实验,并得到了相似的结果。SCUNet++在DSC和HD95两个指标上均取得了最佳结果,分别为83.47和3.83。基于这两个数据集上的实验结果,作者可以得出结论:模型的各个模块都对分割结果产生了显著的影响。
SCUNet++网络模型通过引入嵌套的多融合密集跳跃连接来加强连接,最终设计出具有长和短连接的密集连接。此外,它还包含一个卷积结构来填充模型中间的空洞位置。这种结构使得可以捕获不同 Level 的特征和大小不同的感知场,从而获得更丰富的多尺度信息。此外,SCUNet++采用CNN块作为瓶颈来充分学习深度特征表示,弥补了网络在从图像中提取局部空间特征方面的不足。
因此,消融实验证实了作者的假设,即跳跃连接和CNN块的引入可以提高网络模型的分割Dice值。这些模块的融合使得所提出的网络模型可以有效地利用局部空间特征、整体全局特征和深浅语义信息,最终极大地提高了肺栓塞分割的准确性和稳定性。
6 Conclusion
本文提出了一种新的自动分割网络SCUNet++,用于CTPA图像。作者根据疾病特性和实际分割过程调整网络结构。该网络在编码器和解码器之间引入多个融合的密集跳跃连接,使解码器子网络能够融合不同尺度的特征,并补偿由下采样引起的空间信息损失。作者在发布的FUMPE和CAD-PE数据集上的实验结果表明,该方法在分割精度方面超过了其他最先进的state-of-the-art方法,对PE的诊断产生了积极影响。
在未来,作者计划使用更可靠的标注肺栓塞(PE)数据来进一步改进网络的准确性和鲁棒性,确保方法的稳定性和可靠性。此外,作者将继续与PE专家合作,包括年龄、性别、手术史等额外的患者信息,以开发可量化和可靠的评估指南。这些指南将帮助医生更好地评估患者的状况和风险水平,最终促进为患者提供更准确的诊疗方案。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!