LLM对齐经验之数据越少越好?
LIMA
论文:LIMA: Less Is More for Alignment
要点:人工构建1K高质量样本用于对齐,高质量主要指输出的风格一致性,以及输入的多样性
LIMA是比较早提出Quality Over Quantity观点的论文。论文提出一个假设是模型的知识和能力几乎全部是预训练阶段注入的。而指令微调阶段的对齐只是学习和人类交互的回答形式。因此一个输入多样,输出形式一致的高质量指令数据集能帮模型快速学到回答形式。
指令数据集的构建方式是人工从Stack Exchange, wikiHow和Reddit里面分类筛选更高质量的问题和回答,来构建指令样本集。我们具体说下Stack Exchange样本的构建,其他两个思路是一致的
-
分类采样: 为了保证多样性,把Stack的分成75个科学类别和99个其他类别,从每个类别中采样200个问题
-
筛选:为了保证质量,在以上每个类别中筛选问题评分最高的,再筛选该问题中回答得分最高的
-
过滤:为了保证输出的一致性,过滤太长(4096字符)/太短(1200字符)的回答,过滤以第一人称回答,或者引用了其他回答的内容。以及对内容进行清洗只保留代码和文本部分。
-
样本构建:随机使用问题的标题或者描述作为输入,使用回答做为输出。
除了使用已有的QA数据,几位作者还人工构建了200条基于个人偏好随机创建的prompt,以及编写的回答,在回答编写过程中核心是注意回答风格的一致性。重要的事情说三遍,一致性,一致性,一致性。论文反复强调一致的回答风格可以加速模型收敛。
论文使用的是65B的LLAMA模型,1000条样本,微调了15个epoch,lr=1e-5, batch=32, max_seq_len =2048。最终是人工在验证集打分上,选择了5-10个epoch之间的checkpoint。
论文针对数据集的质量,数量和多样性进行了消融实验,如下图
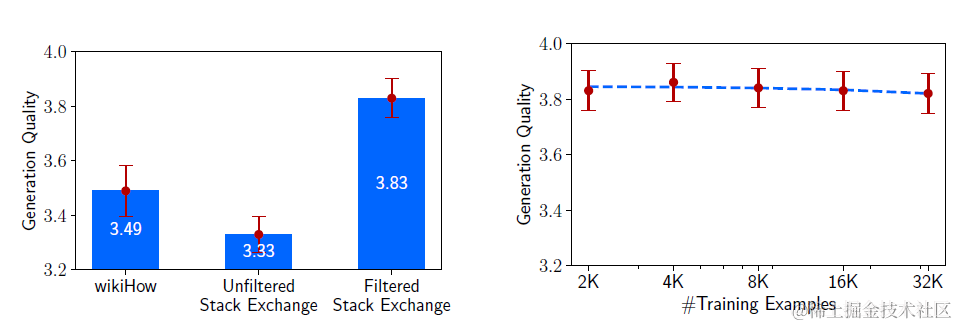
-
多样性:相似质量和数量,输入指令多样性更高的stack exchange的效果优于输入相对单一的wikiHow数据集
-
质量:同等量级上过滤后质量更高的stack Exchange数据集微调的效果更好
-
数量:从质量过滤后单一的stack exchange中采样更高量级的训练样本,并不能显著带来效果提升。之前公认的样本数量越多越好,可能更多是数量提升带来的指令多样性提升。
当然论文选择的样本数本身并无非常大的参考意义,因为这个选择的基座模型,模型大小,数据本身的多样性都相关,所以需要具体模型具体分析。
ALPAGASUS
论文:AlpaGasus: Training A Better Alpaca with Fewer Data
数据: GitHub - gururise/AlpacaDataCleaned: Alpaca dataset from Stanford, cleaned and curated
要点:模型自动化筛选高质量指令微调样本
论文起名终于从和动物纠缠不清,到开始上天入地,模型起名AlpaGasus=Alpaca+Pegasus,故名飞天羊驼,哈哈最近总会让人不由自主想到飞天茅台

对比LIMA,ALPAGASUS没有对什么是高质量进行很明确的定义,但是提出了自动化样本过滤的方案,成本更低,更简单粗暴。从原始52K的ALPACA样本中使用大模型自动筛选高质量的9K样本进行模型微调。
论文在以下4个测试集上进行评估,使用GPT-4给原始Alpaca和飞天羊驼进行偏好打分,胜率如下,在不同量级的训练样本上,飞天羊驼以80%+的胜率超越Alpaca,当训练样本在9K左右的时候,胜率最高~
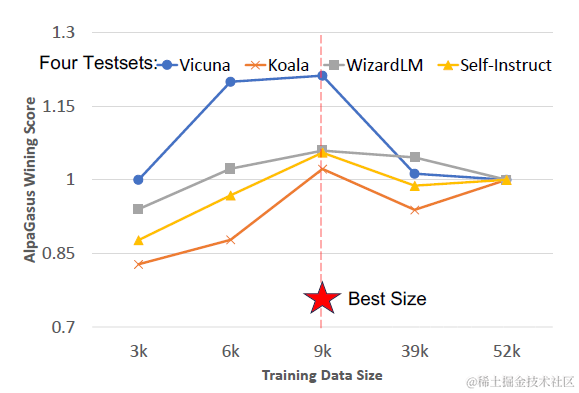
自动样本过滤机制比较简单,就是使用如下Prompt,让Chatgpt给(instruction, input, response)的三元组样本进行打分,并根据最终的打分分布,选定4.5分作为阈值,筛选打分>4.5的9K样本用于下游模型微调。

论文还进行了消融实验,对比了不同的筛选阈值得到的不同训练样本量的影响,3k/6k/9k中9K的样本量级,模型效果最好,但超过后模型效果会有下降。延伸下大概就是高质量的数据越多越好,但低质量的数据越少越好。同时对比了随机采样9K作为作为对照组,效果是显著差于使用模型打分筛选出的9K样本。
自动化数据筛选看起来非常美好且梦幻,但笔者本人有一个疑问,论文使用chatgpt来筛选样本,又用GPT4作为评估,是否会引入bias,这个bias主要来自chatgpt和gpt4相对一致的偏好。这一点除非引入人工评估,或者多个大模型例如Claude之类同时进行最终的评估打分,否则个人感觉可能出现妈妈看自己的孩子咋看都好看的情况......
LTD
论文:Maybe Only 0.5% Data is Needed: A Preliminary Exploration of Low Training Data Instruction Tuning
要点:聚类过滤相似度高的样本,筛选多样性样本用于对齐
LTD的样本筛选中心放在多样性,在任务微调上只使用0.5%的训练样本,还比原有效果提升了2%。论文对多样性给出了更形象的描述就是用最少的样本,去近似刻画当前全部指令集的空间分布。这么一描述,其实答案已经呼之欲出了,跑不了cluster,KNN,k-center这些方案,论文实现如下
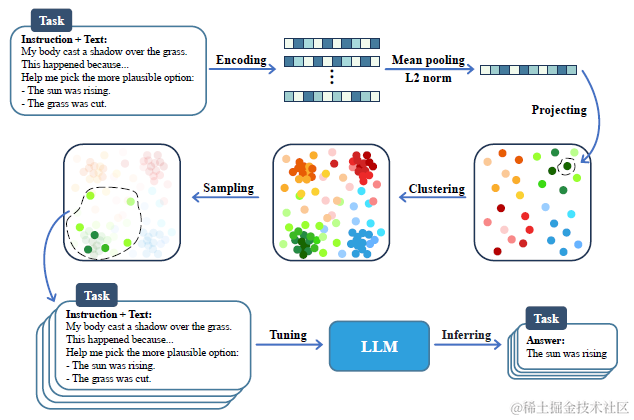
具体分成3个步骤
-
Sample embedding: 把指令样向量化,这里论文是把指令+回答一同输入BERT模型进行编码,并且做了l2正则化,这样后续聚类计算距离就可以直接使用cosine距离
-
Clustering:作者使用K-Means对所有指令样本进行聚类,不过个人更偏好aggolomerative clustering,毕竟k-means是密度聚类,而层次聚类是基于距离的,在文本聚类中距离是有明确含义的,可以更好保证不同cluster直接的粒度相对一致
-
Corest Sampling:基于聚类结果选择有代表性的样本来构建指令集。我本以为论文会直接从每个cluster动进行随机采样,意料之外的是论文采用了贪心的K-center算法来选取更有代表性的数据点,算法如下。目标是找到K的中心点,使得所有点到距离最近的中心点的距离之和最小化。实现是先用聚类中心点作为起始中心点,遍历所有其他点找到离所有起始点距离最远的点,把这个点也加入中心点,然后多次重复以上过程。

除了以上介绍的论文之外,还有几篇论文思想也或有相似,包括以下Reference中的
-
InstructionGPT-4:把多样性和质量进行综合打分的多模态微调模型
-
Instruction Minning: 使用指令评估集推理Loss来对指令数据进行高质量筛选的
-
Polite Flamingo:通过改写和重构构建高质量多模态模型输出数据
-
Textbooks:编程任务上构建教科书级别质量的预训练数据,和对应的习题集数据用于微调效果显著超越StarCoder
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!