【MyBatis】#{}和${} | 数据库连接池

前言
前面我们学习了 MyBatis 的基础操作,其中参数的传递使用到了
#{},而参数的传递不仅仅只有这一个可以使用,还有 ${} 可以使用,那么今天这篇文章我将为大家说说关于 #{} 和 ${},这个是 MyBatis 在面试中最常问的面试题,以及数据库连接池相关的知识。
#{}和${}的使用
首先我们还是需要在 YAML 配置文件中配置数据库的相关配置。
# 配置数据库相关信息
spring:
datasource:
url: jdbc:mysql://127.0.0.1:3306/mybatis_test?characterEncoding=utf8&useSSL=false
username: root
password: lmh041105666
# 打印mybatis日志
mybatis:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
UserInfoMapper文件中的代码
@Mapper
public interface UserInfoMapper {
//这里是使用#{}作为参数的传递
@Select("select * from userinfo where id=#{id}")
public UserInfo selectById(Integer id);
}
单元测试中代码
@Slf4j
@SpringBootTest
class UserInfoMapperTest {
@Autowired
private UserInfoMapper userInfoMapper;
@Test
void selectById() {
log.info(userInfoMapper.selectById(3).toString());
}
}

然后我们讲这里的 #{} 改为 ${} 看看有什么效果。
@Select("select * from userinfo where id=${id}")
public UserInfo selectById(Integer id);
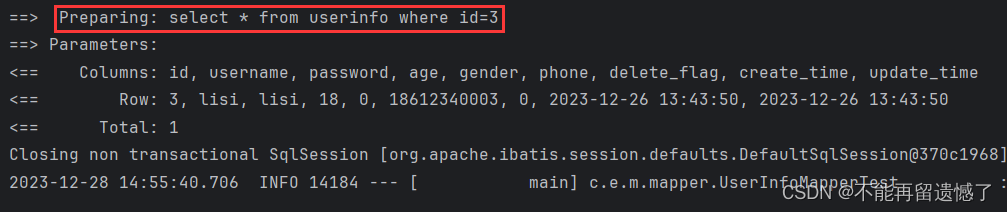
这里可以看到 #{} 和 ${} 的一个区别:使用 #{} 进行参数的传递的时候,不是直接将输入的参数拼接到后面,而是先使用 ? 进行占位,这种 SQL 我们称之为“预编译SQL”。而使用 ${} 进行参数传递的时候,会将输入的参数直接拼接到 SQL 的后面,这种 SQL 我们称之为“即时SQL”。这两个 SQL 的区别我们后面再说。
上面我们传入的参数都是 Integer 类型的参数,那么如果我们传入的参数类型是 String 的话,会发生什么呢?
@Select("select * from userinfo where username=#{username}")
public UserInfo selectByName(String username);
@Test
void selectByName() {
log.info(userInfoMapper.selectByName("小美").toString());
}
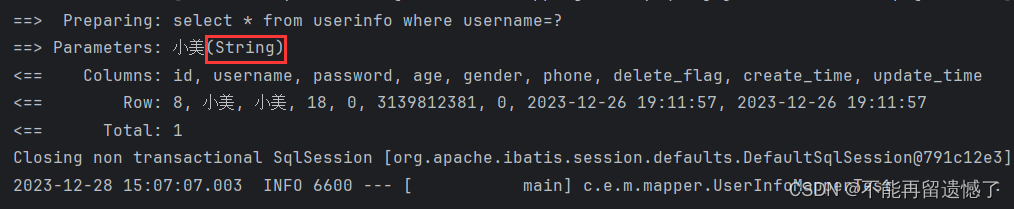
可以看到,使用 #{} 进行参数的传递的时候,会对传递的参数的类型进行识别,我们传入的类型是 String 类型的话,就会识别为 String 类型,我们再来看看使用 ${} 传递参数,参数的类型为 String 类型的情况。
@Select("select * from userinfo where username=${username}")
public UserInfo selectByName(String username);

通过观察 MyBatis 打印出来的日志可以发现,传递参数的时候,直接将我们传递的参数拼接到了 SQL 的末尾,而且没有加上引号,那么在 SQL 中没有加引号的字符串会被认为是表中的列,而我们当前表中没有 小美 这个列,所以就会报错,那么我们如何解决这个问题呢?
因为使用 ${} 进行参数的传递的时候是直接将传递的参数拼接到 SQL 的对应位置,所以我们可以手动在 SQL 中加入引号。
@Select("select * from userinfo where username='${username}'")
public UserInfo selectByName(String username);

通过上面的两个例子,我们可以发现:#{} 使用的是预编译 SQL,通过 ? 占位的方式,提前对 SQL 进行编译,然后把参数填充到 SQL 语句中,并且 #{} 会根据参数类型,自动拼接 ‘’。而 ${} 则会直接进行字符的替换,一起对 SQL 进行编译,如果参数为字符串类型,需要我们手动在 SQL 中加入引号。
#{}和${}的区别
当别人问我们 #{} 和 ${} 的区别的时候,实际上是在问预编译 SQL 和即时 SQL 的区别。
当一个客户发送一条 SQL 给服务器之后,大致流程是这样的:
- 解析语法和语义,校验 SQL 语句是否正确
- 优化 SQL 语句,制定执行计划
- 执行并返回结果
一个 SQL 如果执行流程是这样的话,那么这个 SQL 就被成为 即时SQL。
但是呢,绝大多数情况下,某一条 SQL 语句可能会被反复调用执行,或者每次执行的时候只有个别的值不同(比如 selelct 的 where 子句值不同,update 的 set 子句不同,insert 的 values 值不同)。如果我们每次调用这种 SQL 都按照上面的语法解析、SQL 优化、SQL 编译等,那么效率就会降低了。
类似这种 SQL,我们就可以使用预编译 SQL 的方法来提升效率。
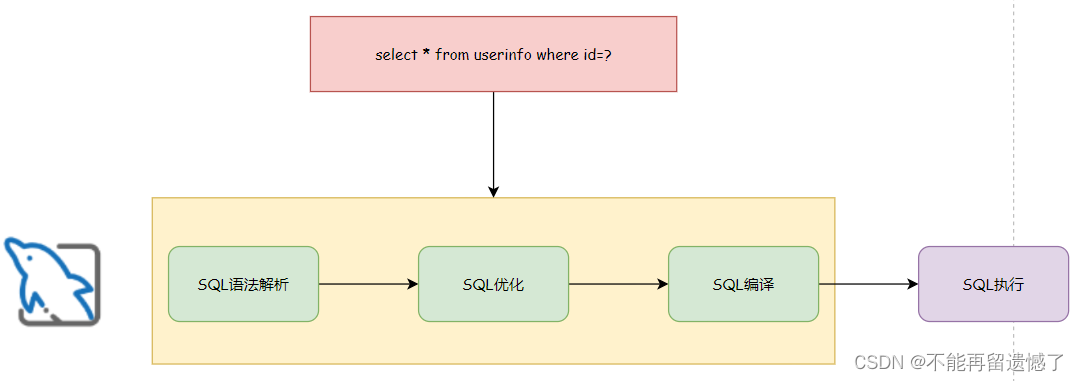
预编译SQL是一种常见的数据库优化技术,其主要目的是提高数据库查询的效率和安全性。在预编译SQL中,SQL语句和参数被分开处理。首先,SQL语句被编译成一个中间形式,这个中间形式通常是与数据库管理系统(DBMS)的内部表示相对应的。然后,参数值与编译后的SQL语句进行动态绑定,最终生成可以直接执行的SQL语句。后面再传入参数执行这条语句的时候(只是输入的参数不同),省去了解析优化的过程,一次来提高效率。
预编译 SQL 的优点不止是可以提高效率,还可以防止 SQL 注入。
什么是 SQL 注入?
SQL注入是一种常见的网络攻击方式,发生在Web应用程序中。它利用了Web应用程序对用户输入数据合法性没有进行充分验证或过滤不严的漏洞。攻击者可以在Web应用程序中事先定义好的查询语句的结尾上添加额外的SQL语句,从而实现在管理员不知情的情况下执行非法操作。
当用户在Web页面上输入数据时,如果这些数据未经过适当的验证和处理,攻击者可以在其中插入或“注入”恶意的SQL代码。当这些数据被用来构建SQL查询时,这些恶意的SQL代码就会被执行。攻击者可以执行非授权的任意查询,从而进一步得到相应的数据信息。
例如,假设一个Web应用程序的登录页面允许用户输入用户名和密码。如果应用程序没有对用户输入进行适当的验证,攻击者可以在用户名或密码字段中输入如’ OR ‘1’='1之类的SQL代码。当应用程序将这些数据用于构建SQL查询时,这些代码会使得查询变成
SELECT * FROM users WHERE username='' OR '1'='1' AND password='password',从而绕过正常的验证,获得所有用户的访问权限。
因为 ${} 传递参数的方式也就是即时 SQL 不会对用户的输入进行充分检查,而 SQL 又是直接拼接而成的,在用户输入参数的时候,在参数中添加一些 SQL 关键字,达到改变 SQL 运行结果的目的,从而实现恶意攻击。
给大家举个例子:
@Select("select * from userinfo where username='${username}'")
public List<UserInfo> selectByName(String username);
@Test
void selectByName() {
log.info(userInfoMapper.selectByName("'or 1='1").toString());
}
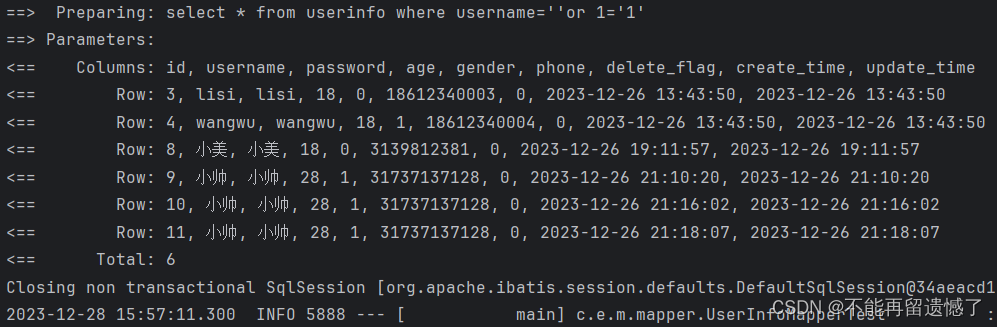
通过这样传递参数的话,那么将我们传递的参数直接拼接在 SQL 中,就会出现这样的 SQL:select * from userinfo where username='' or 1='1',在这里 1 会被解释为字符串 ‘1’,那么这时 ‘1’='1’为真,那么这时就会将数据库中该表中的所有信息都给显示出来,这样就会导致数据的泄露。
通过观察代码的执行结果,我们也可以发现,表中的所有信息都被显示出来了。
而如果我们使用 #{} 来实现 SQL 的注入,看看可以达到效果吗?
@Select("select * from userinfo where username=#{username}")
public List<UserInfo> selectByName(String username);
@Test
void selectByName() {
log.info(userInfoMapper.selectByName("'or 1='1").toString());
}

通过预编译 SQL 占位的方式,我们输入的参数会被认为是表中的 username 列中的一个名称,而不会被解析成为上面的 SQL,表中没有一个叫“or 1='1"的username,所以查询结果为0,也就是说,通过预编译 SQL 的方式可以有效的解决 SQL 注入的情况。
所以为了防止 SQL 注入,我们应尽量选择 #{} 来使用,那么是否就代表着 ${} 就不被使用了了呢?不是这样的,既然出现了,那么它就有存在的意义。
排序功能
有一些情况下,只能使用 ${},而不能使用 #{}。其中很典型的情况就是涉及到排序的时候,根据我们输入的参数决定是升序排列还是降序排列。
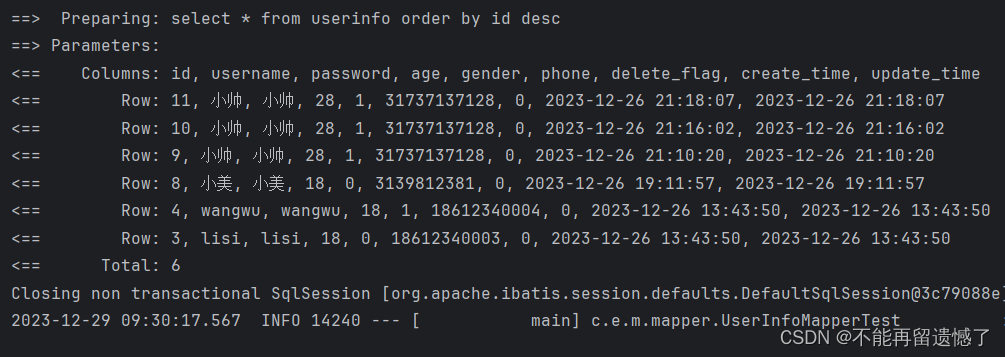
@Select("select * from userinfo order by id #{sort}")
public List<UserInfo> selectBySort(String sort);
@Test
void selectBySort() {
log.info(userInfoMapper.selectBySort("desc").toString());
}


可以看到,本来我们进行排序查询的话,排序规则是不需要加上引号的,而在预编译占位的情况下,因为传递来的参数是字符串类型,所以在拼接 SQL 的时候,该参数就被加上了引号,所以就导致出现错误,在这种情况下我们就得使用 ${} 来进行 SQL 的直接拼接。
@Select("select * from userinfo order by id ${sort}")
public List<UserInfo> selectBySort(String sort);
所以当我们进行传递排序规则的时候,需要使用到 ${}。
模糊查询
MySQL 中的模糊查询使用 like 关键字,% 用来匹配任意任意数量的字符(包含0个),_ 用来匹配单个字符,那么如果我们想用参数传递的方式来指定模糊查询的规则的话,就不能使用 #{} 的。
@Select("select * from userinfo where username like '%#{like}%'")
public List<UserInfo> selectByLike(String like);
@Test
void selectByLike() {
log.info(userInfoMapper.selectByLike("小").toString());
}
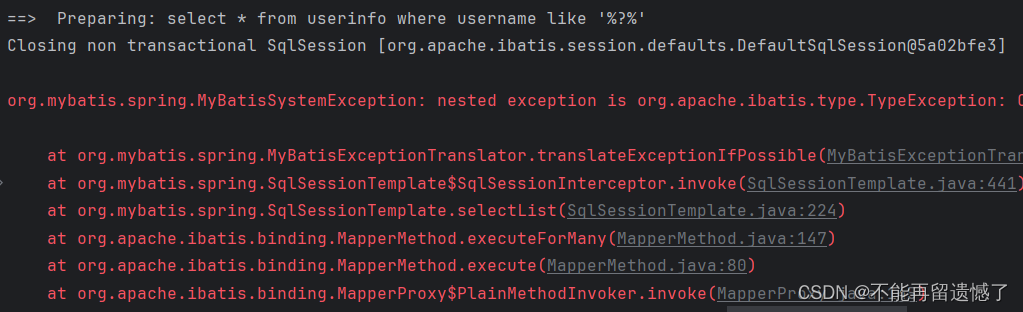

同样也是,使用 #{} 进行参数的传递的话,因为传递过来的参数的类型是字符串类型,所以在进行 SQL 拼接的时候就会自动加上引号也就是 ‘%‘小’%’,这样的形成的 SQL,就是有问题的 SQL。
我们使用 ${} 的话就不会出现这种问题:
@Select("select * from userinfo where username like '%${like}%'")
public List<UserInfo> selectByLike(String like);
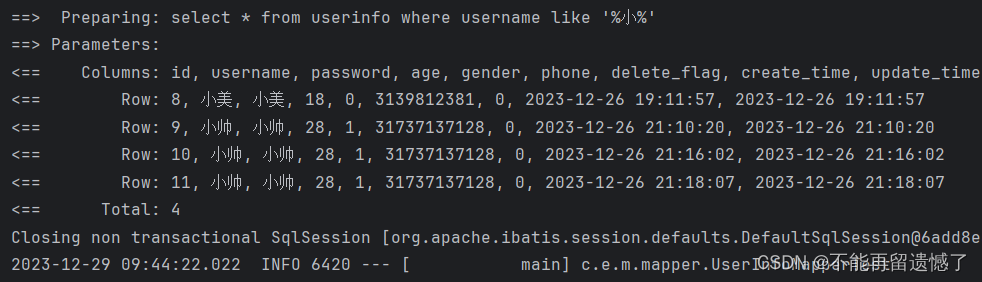
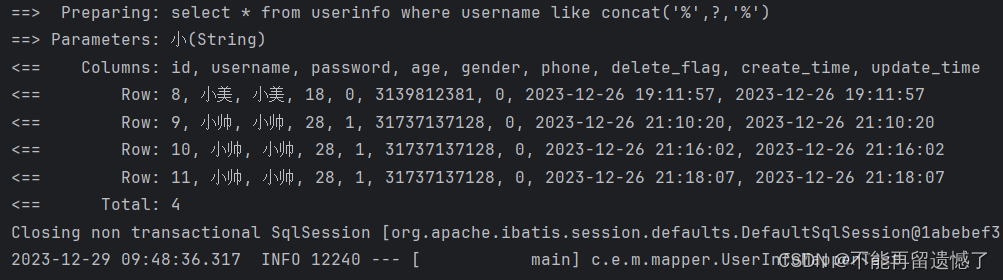
但是在这种情况下还是会发生 SQL 注入的情况,所以我们不推荐使用 ${},而是使用 SQL 内置的函数 concat()。
@Select("select * from userinfo where username like concat('%',#{like},'%')")
public List<UserInfo> selectByLike(String like);
总结 #{} 和 ${} 的区别
- 在使用 #{} 进行参数的传递的时候,会根据参数的类型,在拼接 SQL 的时候做出调整,而 ${} 则是直接进行 SQL 的拼接。
- 在排序,传递排序规则的时候不能使用 #{},因为 SQL 编译的时候会根据传递的字符串类型,在 SQL 中加入引号,所以这种情况下只能使用 ${}。
- 进行模糊查询的时候,虽然直接使用 #{} 会出现问题,使用 ${} 不会出现问题,但是我们不使用 ${},因为会发生 SQL 注入,而是使用 SQL 内置函数 concat()
- 最重要的就是预编译 SQL 和即时 SQL 的区别:
-
- 预编译 SQL 性能更高
-
- 预编译 SQL 不存在 SQL 注入的问题
所以在实际开发的过程中,能使用 #{} 的情况就尽量使用 #{},如果要使用 ${},就一定要考虑到 SQL 注入的问题。
数据库连接池
数据库连接池是程序在启动时创建足够多的数据库连接,并将这些连接放入一个池子中。这个池子中的连接可以被程序动态地申请、使用和释放。其作用是分配、管理和释放数据库连接,使得应用程序可以重复使用现有的同一个数据库连接,而不是每次都重新建立连接,从而避免了资源的消耗,提高了程序执行的效率。
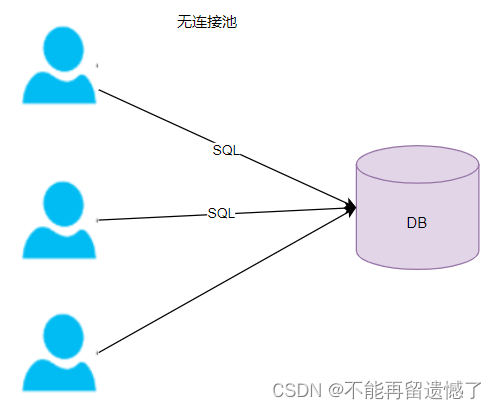
当没有数据库连接池的话,当客户端向服务器发送 SQL 请求的话,会先创建一个 Connection 连接,然后通过这个连接访问到服务器,当请求完成之后,这个连接又会被销毁,下次再请求的时候,还是需要先创立连接,然后再释放连接,这样是比较消耗资源的。
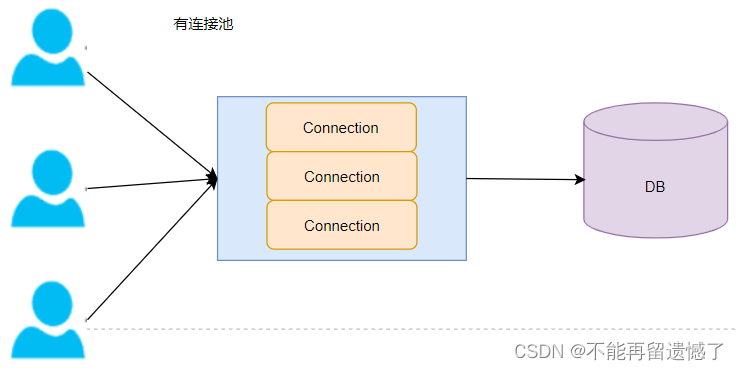
当使用数据库连接池的情况,当程序启动的时候,就会在数据库连接池中创建一定数量的 Connection 对象,当客户端需要访问服务器的时候,可以直接使用数据库连接池中的 Connection 对象,并且当使用完成之后,会将 Connection 对象归还给数据库连接池,这样就极大的节省了 CConnection 对象的创建和销毁所需要的时间。
总的来说,使用数据库连接池具有以下优点:
- 减少网络开销
- 资源重用
- 提升系统的性能
常见的数据库连接池有:C3P0、DBCP、Druid、Hikari,当前比较流行的是 Hikari和Druid。
而在我们的 SpringBoot 中,默认使用的数据库连接池是 Hikari。

当我们启动 MyBatis 的 SpringBoot 项目的时候,就会启动 Hikari 数据库连接池,建立 Connection 对象。
如果我们想要更换 SpringBoot 使用的数据库连接池的话,只需要将要更换到的数据库连接池的依赖添加到 pom.xml 文件即可。
这里假设我们更换 SpringBoot 的数据库连接池为 Druid:
将下面这个坐标添加到 pom.xml 文件中。并且刷新 pom.xml 文件,将新添加的依赖下载下来。
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.17</version>
</dependency>

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!