满帮面试一面
满帮面试一面
这里记录一些面试的题目,希望可以帮助到大家
oracle和mysql如何在数据库层面处理空值?
MySQL
在 MySQL 中,处理空值(NULL)的方法与其他数据库类似。以下是一些在 MySQL 中处理空值的常见方法:
判断空值:使用 IS NULL 或 IS NOT NULL 来检查列是否为空。例如:
SELECT * FROM your_table WHERE your_column IS NULL; SELECT * FROM your_table WHERE your_column IS NOT NULL;
使用 IFNULL 函数:IFNULL 函数用于返回第一个非空表达式。例如:
SELECT IFNULL(your_column, 'Default Value') FROM your_table;
使用 COALESCE 函数:COALESCE 函数在 MySQL 中同样可用,它返回参数列表中的第一个非空表达式。例如:
SELECT COALESCE(your_column, 'Default Value') FROM your_table;
使用 IF 表达式:使用 IF 表达式来根据条件返回不同的值,包括处理空值的情况。例如:
SELECT IF(your_column IS NULL, 'No Value', your_column) AS processed_column FROM your_table;
Oracle
在 Oracle 数据库中,处理空值(NULL)有一些特殊的考虑和方法。以下是一些常见的方法:
判断空值:使用 IS NULL 或 IS NOT NULL 来检查列是否为空。例如:
SELECT * FROM your_table WHERE your_column IS NULL; SELECT * FROM your_table WHERE your_column IS NOT NULL;
使用 COALESCE 函数:COALESCE 函数用于返回参数列表中的第一个非空表达式。可以用它来处理空值,如:
SELECT COALESCE(your_column, 'Default Value') FROM your_table;
使用 NVL 函数:NVL 函数也可用于处理空值,它返回第一个非空表达式。例如:
SELECT NVL(your_column, 'Default Value') FROM your_table;
使用 CASE 表达式:使用 CASE 表达式来根据列值的不同情况进行处理,包括处理空值的情况。例如:
SELECT
CASE
WHEN your_column IS NULL THEN 'No Value'
ELSE your_column
END
FROM your_table;
spring内置的tomcat端口如何实现?
tomcat体系架构
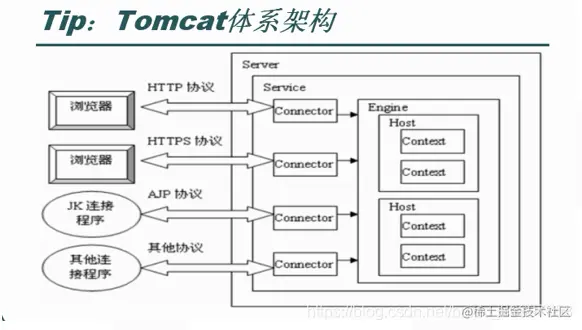
1.Server组件 即服务器,每个tomcat程序启动后,就是一个server。
2、Service组件 一个Server可以包含多个Service,Service这是一种抽象的服务,它把连接器和处理引擎结合在一起。
3、Connector组件: 一个Service可以有多个Connector,Connector组件用于处理连接和并发。一般说来常见于server.xml中的连接器类型通常有4种: 1) HTTP连接器 2) SSL连接器 3) AJP 1.3连接器 4) proxy连接器
4、Engine组件: Engine是Servlet处理器的一个实例,即servlet引擎,其defaultHost属性是用来为其定义一个接收所有发往非明确定义虚拟主机的请求的host组件。
5、Host组件: 位于Engine容器中,用于接收请求并进行相应处理的主机或虚拟主机。
6、Context组件: Context在某些意义上类似于apache中的路径别名,一个Context定义用于标识tomcat实例中的一个Web应用程序
http请求tomcat流程:
1、用户打开浏览器输入地址,请求被发送到本机端口9903,被在那里监听的Connector获得。
2、Connector把该请求交给它所在的Service的Engine来处理,并等待Engine的回应。
3、Engine获得请求,匹配所有的虚拟主机Host。
4、Engine匹配的Host(即使匹配不到也把请求交给该Host处理,因为该Host被定义为该Engine的默认主机),匹配它所拥有的所有的Context。
5、在它的mapping table中寻找出对应的Servlet 处理数据。
6、构造HttpServletRequest对象和HttpServletResponse对象,作为参数调用JspServlet的doGet()或doPost().执行业务逻辑、数据存储等程序。
7、照着上面的路劲逐步返回


redis多路复用模型如何实现?
因为Redis 是跑在单线程中的,所有的操作都是按照顺序线性执行的,但是由于读写操作等待用户输入 或 输出都是阻塞的,所以 I/O 操作在一般情况下往往不能直接返回,这会导致某一文件的 I/O 阻塞导,致整个进程无法对其它客户提供服务。而 I/O 多路复用就是为了解决这个问题而出现的。为了让单线程(进程)的服务端应用同时处理多个客户端的事件,Redis采用了IO多路复用机制。
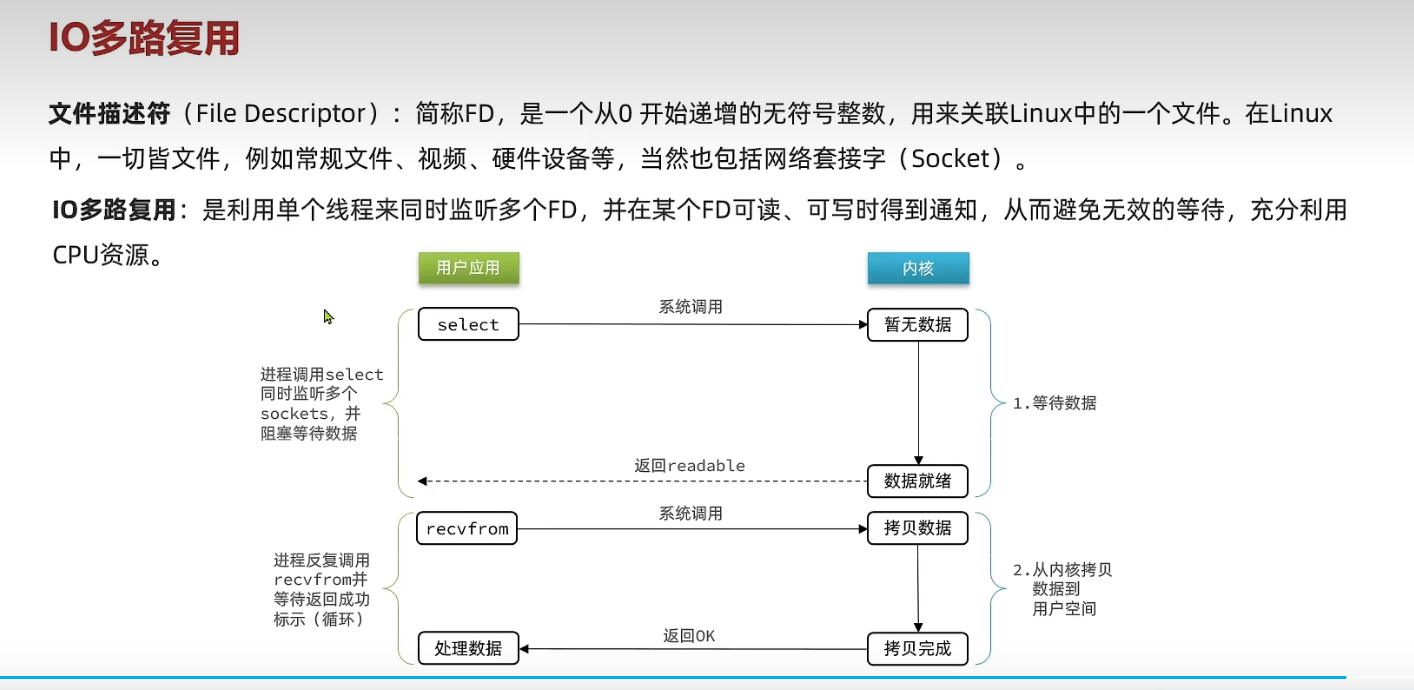
监听fd的方式有三种,分别为select,poll和epoll
select方案

poll方案

epoll方案
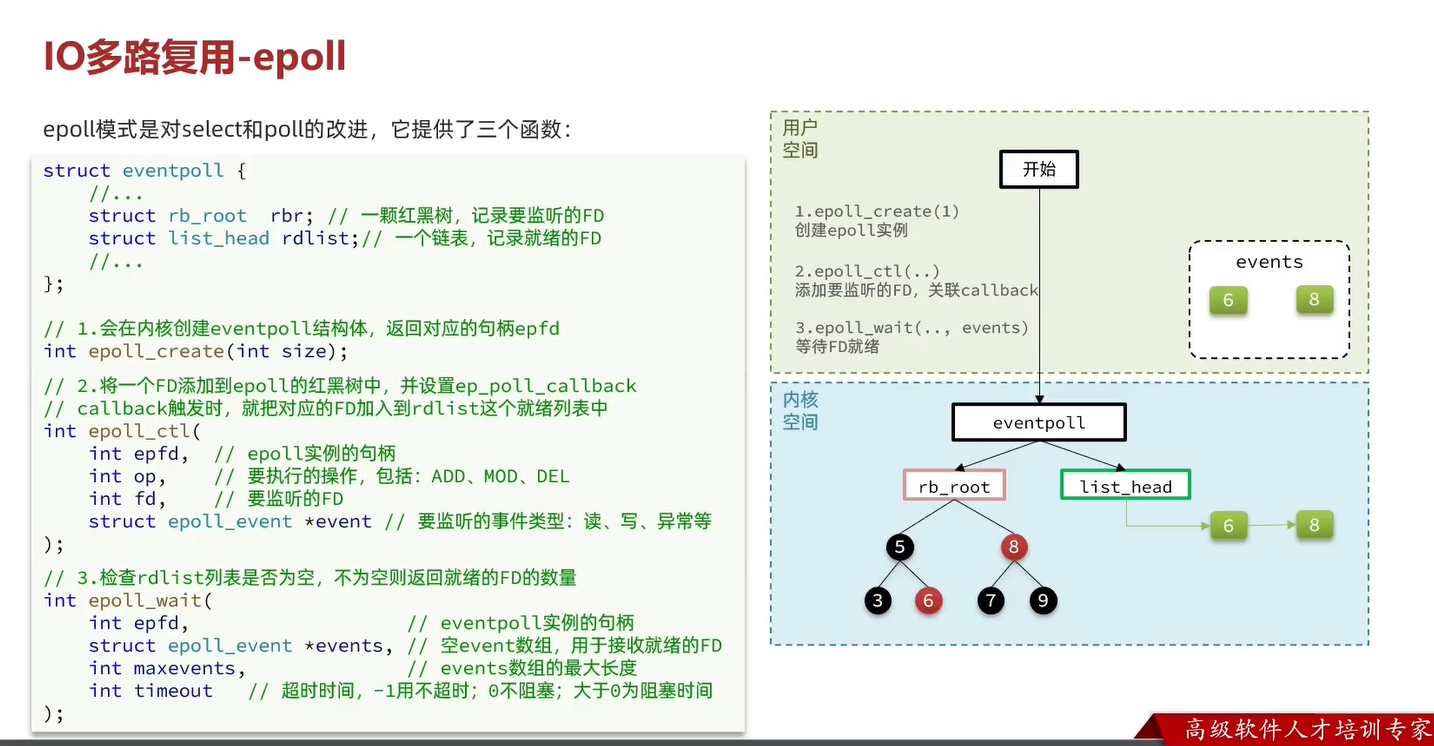
总结

你了解过哪些集合类,说说他们的实现原理?
ArrayList

数组越界异常
在多个线程进行add操作时可能会导致elementData数组越界。
具体逻辑如下:
- 列表大小为9,即size=9
- 线程A开始进入add方法,这时它获取到size的值为9,调用ensureCapacityInternal方法进行容量判断。
- 线程B此时也进入add方法,它获取到size的值也为9,也开始调用ensureCapacityInternal方法。
- 线程A发现需求大小为10,而elementData的大小就为10,可以容纳。于是它不再扩容,返回。
- 线程B也发现需求大小为10,也可以容纳,返回。
- 线程A开始进行设置值操作, elementData[size++] = e 操作。此时size变为10。
- 线程B也开始进行设置值操作,它尝试设置elementData[10] = e,而elementData没有进行过扩容,它的下标最大为9。于是此时会报出一个数组越界的异常ArrayIndexOutOfBoundsException.
元素值覆盖和为空问题
elementData[size++] = e 设置值的操作同样会导致线程不安全。从这儿可以看出,这步操作也不是一个原子操作,它由如下两步操作构成:
elementData[size] = e; size = size + 1;
在单线程执行这两条代码时没有任何问题,但是当多线程环境下执行时,可能就会发生一个线程的值覆盖另一个线程添加的值,具体逻辑如下:
- 列表大小为0,即size=0
- 线程A开始添加一个元素,值为A。此时它执行第一条操作,将A放在了elementData下标为0的位置上。
- 接着线程B刚好也要开始添加一个值为B的元素,且走到了第一步操作。此时线程B获取到size的值依然为0,于是它将B也放在了elementData下标为0的位置上。
- 线程A开始将size的值增加为1
- 线程B开始将size的值增加为2
这样线程AB执行完毕后,理想中情况为size为2,elementData下标0的位置为A,下标1的位置为B。而实际情况变成了size为2,elementData下标为0的位置变成了B,下标1的位置上什么都没有。并且后续除非使用set方法修改此位置的值,否则将一直为null,因为size为2,添加元素时会从下标为2的位置上开始。
LinkedList
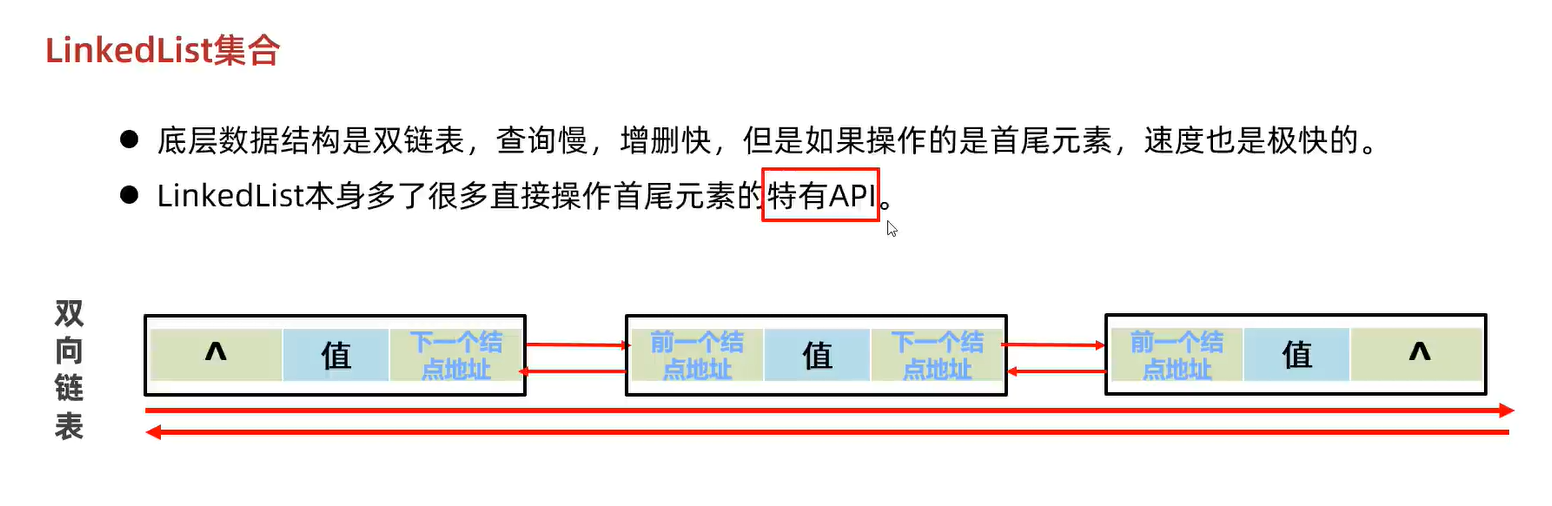
Linkedlist多线程下的错误
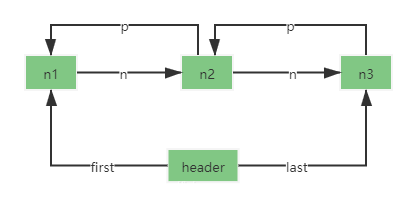
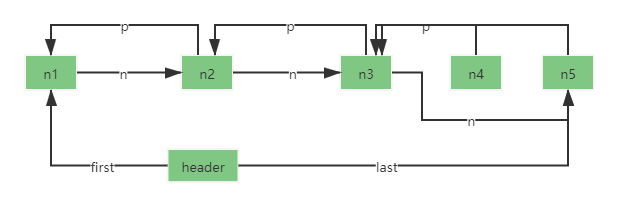
现在有3个结点n1、n2、n3。标记指针header的头结点指针first指向n1,尾结点指针last指向n3。
假如线程A、线程B同时要做add操作。
1.线程A找到last结点。
2.线程B找到last结点。(此时A、B找到的last结点是一样的)
3.线程A:新结点n4的previous设为last结点,之前的last结点的next设为新结点n4。size+1=4
4.线程B:新结点n5的previous设为last结点,之前的last结点的next设为新结点n5。size+1=5
Hashmap
HashMap基于哈希表的Map接口实现,是以key-value存储形式存在,即主要用来存放键值对。HashMap的实现不是同步的,这意味着它不是线程安全的。它的key、value都可以为null。此外,HashMap中的映射不是有序的。
JDK1.8之前的HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了节解决哈希碰撞(两个对象调用的hashCode方法计算的哈希码值一致导致计算的数组索引值相同)而存在的(“拉链法”解决冲突)。
JDK1.8之后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(或者红黑树的边界值,默认为8)并且当前数组的长度大于64时,此时此索引位置上的所有数据改为使用红黑树存储。
数组里面都是key-value的实例,在JDK1.8之前叫做Entry,在JDK1.8之后叫做Node。
扩容机制
JDK1.7扩容
条件:发生扩容的条件必须同时满足两点
1.当前存储的数量大于等于阈值
2.发生hash碰撞
因为上面这两个条件,所以存在下面这些情况:
就是hashmap在存值的时候(默认大小为16,负载因子0.75,阈值12),可能达到最后存满16个值的时候,再存入第17个值才会发生扩容现象,因为前16个值,每个值在底层数组中分别占据一个位置,并没有发生hash碰撞。
当然也有可能存储更多值(超多16个值,最多可以存26个值)都还没有扩容。原理:前11个值全部hash碰撞,存到数组的同一个位置(这时元素个数小于阈值12,不会扩容),后面所有存入的15个值全部分散到数组剩下的15个位置(这时元素个数大于等于阈值,但是每次存入的元素并没有发生hash碰撞,所以不会扩容),前面11+15=26,所以在存入第27个值的时候才同时满足上面两个条件,这时候才会发生扩容现象。
JDK1.8扩容
条件:
1.当前存储的数量大于等于阈值
2.当某个链表长度>=8,但是数组存储的结点数size() < 64时
特点:先插后判断是否需要扩容(扩容时是尾插法)
缺点:多线程下,1.8会有数据覆盖
举例: 线程A:往index插,index此时为空,可以插入,但是此时线程A被挂起 线程B:此时,对index写入数据,A恢复后,就把B数据覆盖了
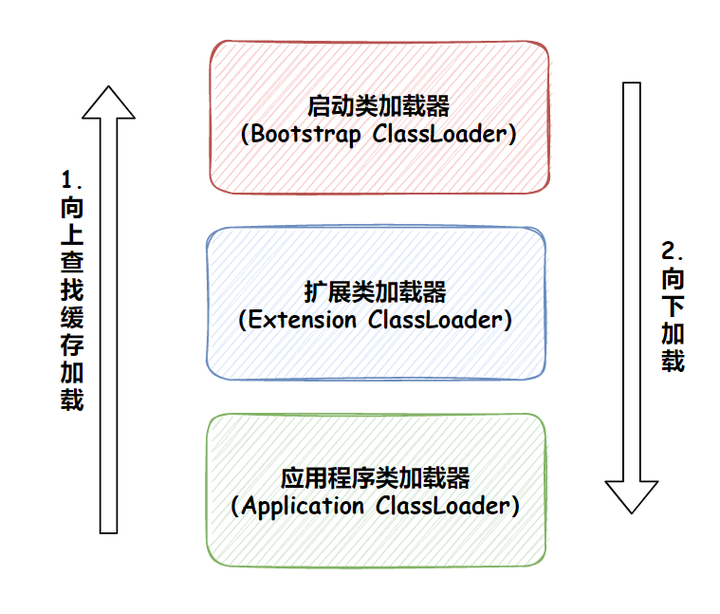
双亲委派模型
双亲委派模型的执行流程是这样的:
1、在应用程序类加载器的缓存里查找相应的类,如果能找到就返回对象,否则下一条;
2、在扩展加载器缓存中查找相应的类,如果能找到就返回对象,否则下一条;
3、在启动类加载器中查询相应的类,如果找到就返回对象,否则下一条;
4、在扩展加载器中查找并加载类,如果能找到就返回对象,并将对象加入到缓存中,否则下一条;
5、在应用程序类加载器中查找并加载类,如果能找到就返回对象,并将对象加入到缓存中,如果找不到就返回 ClassNotFound 异常。
bean的生命周期

组合索引最左原则原理
不按照最左匹配来为什么失效,其原因就在于联合索引的 B+ 树中的键值是排好序的。不过,这里指的排好序,其实是相对的,举个例子,有 (a, b, c) 联合索引,a 首先是排序好的,而 b 列是在 a 列排序的基础上做的排序,同样的 c 是在 a,b 有序的基础上做的排序。所以说,如果有 where a = xxx order by b = xxx 这种请求的话,是可以直接在这颗联合索引树上查出来的,不用对 b 列进行额外的排序;而如果是 where a = xxx order by c = xxx 这种请求的话,还需要额外对 c 列进行一次排序才行。
另外,如果有对 a,b,c 的联合条件查询的话,并且 a 是模糊匹配或者说是范围查询的话,其实并不能完全踩中联合索引(a,b,c),a 列右边的所有列都无法使用索引进行快速定位了。所以这个时候就需要进行回表判断也就是说数据库会首先根据索引来查找记录,然后再根据 where 条件来过滤记录。
Java中的引用
值传递(pass by value):在调用函数时,将实际参数复制一份传递到函数中,这样在函数中对参数进行修改,就不会影响到原来的实际参数;
引用传递(pass by reference):在调用函数时,将实际参数的地址直接传递到函数中。这样在函数中对参数进行的修改,就会影响到实际参数;
Java中只有值传递,在传递对象的过程中传递的是对象的地址
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!