目标检测-One Stage-SSD
前言
根据前文目标检测-Two Stage-YOLOv1可以看出YOLOv1的主要缺点是:
- 每个格子针对目标框的回归是不加限制的,导致目标的定位并不是很精准
- 和Faster RCNN等先进Two Stage算法相比,没有应用多尺度特征图的思想
- 预训练时与实际训练时输入大小不一致,模型需要去适应这种分辨率的转换,会影响最终精度
SSD(Single Shot MultiBox Detector)针对上述缺点做了改进
提示:以下是本篇文章正文内容,下面内容可供参考
一、SSD的网络结构和流程
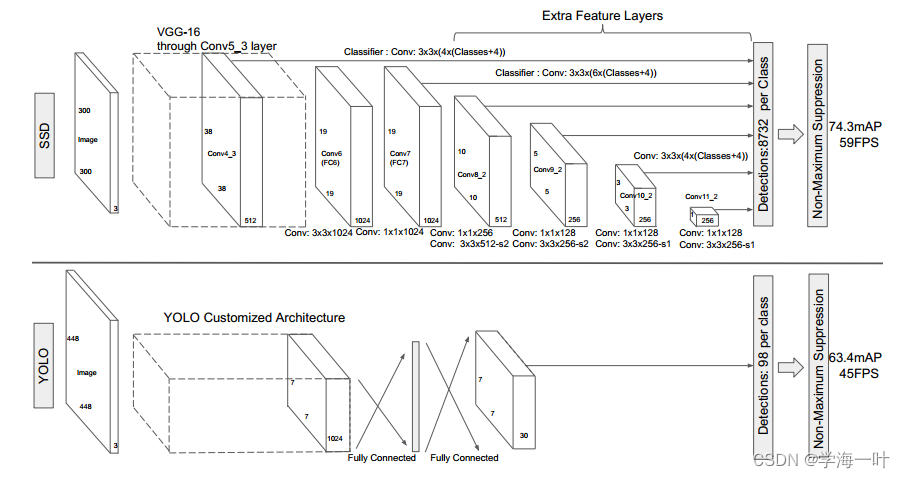
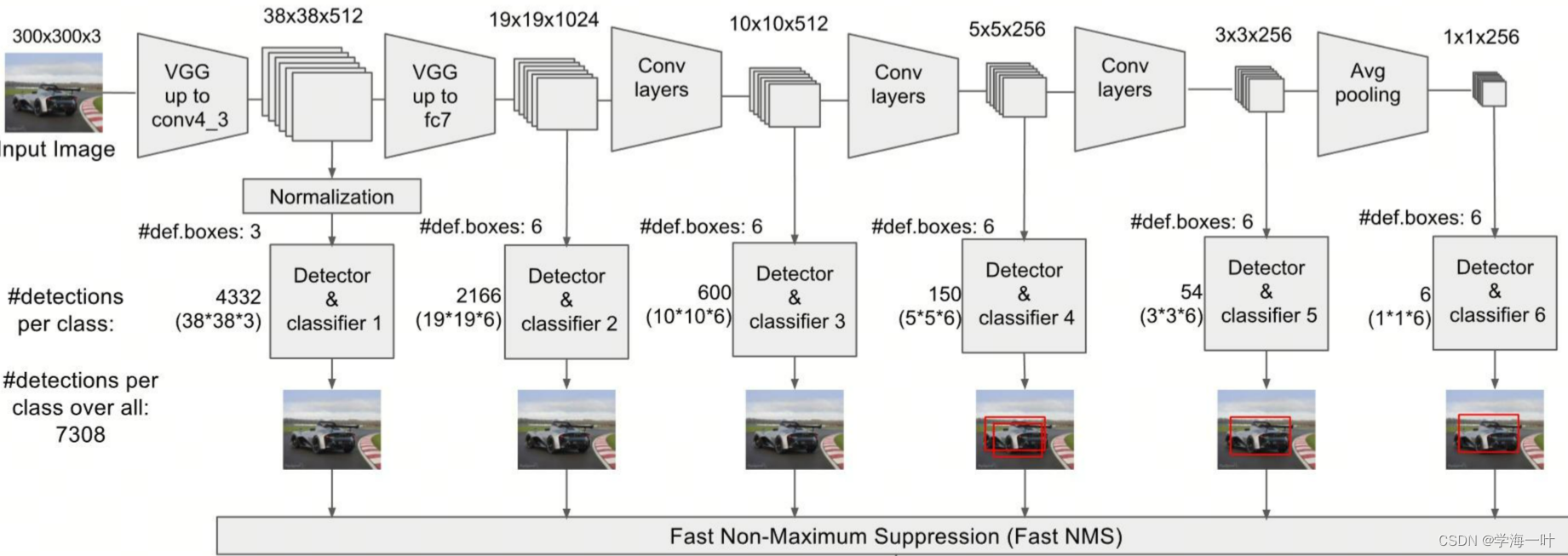
- 将影像输入VGG16,得到不同卷积层的多尺度特征图(38,19,10,5,3,1)
- 引入了anchor机制,不同尺度特征图每个像素预设置不同数量的先验框 [4, 6, 6, 6, 4, 4]
ps:产生共计 3 8 2 × 4 + 1 9 2 × 6 + 1 0 2 × 6 + 5 2 × 6 + 3 2 × 4 + 1 2 × 4 = 8732 38^2×4+19^2×6+10^2×6+5^2×6+3^2×4+1^2×4 = 8732 382×4+192×6+102×6+52×6+32×4+12×4=8732 个anchor
SSD中anchor的大小尺寸(scale)并不是按照特征图的大小统一缩放对应的,而是手动设置了一个线性插值变换,使浅层使用较小的scale,往深层逐渐增大scale。由于随着层次加深感受野逐渐增大,这意味着SSD使用感受野小的feature map检测小目标(较小的scale),使用感受野大的feature map检测更大目标(较大的scale)。
- 将不同尺度特征图的anchor输入不同的分类和边框回归器
- 使用非极大值抑制NMS去除冗余窗口
二、SSD的创新点
- 引入了多尺度特征图和anchor机制,改进了YOLOv1边框不加限制的缺点
- 为适应数据集的输入,采用了两种大小输入:300 × 300和512 × 512
- 使用了一些数据增强手段
总结
SSD结合了YOLO中的回归思想和Faster R-CNN中的anchor机制,使用全图各个位置的多尺度区域特征进行回归,既保持了YOLO速度快的特性,也保证了窗口预测的跟Faster R-CNN一样比较精准。SSD在VOC2007上mAP可以达到72.1%,速度在GPU上达到58帧每秒。
但是,和Faster RCNN使用SPP不限制输入大小相比,到目前为止,One Stage算法都是缩放到固定大小,可能会使图片变形失真。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!