关联规则 Apriori算法原理
2023-12-17 00:01:27
Apriori算法
算法概述
Apriori算法利用频繁项集生成关联规则。它基于频繁项集的子集也必须是频繁项集的概念频繁项集是支持值大于阈值 (support) 的项集
- Apriori算法就是基于一个先验如果某个项集是频繁的,那么它的所有子集也是频繁的
算法流程
输入: 数据集合D,支持度闯值a 输出: 最大的频繁k项集
1)扫描整个数据集,得到所有出现过的数据,作为候选频繁1项集。k=1,频繁0项集为空集。 2) 挖掘频繁k项集
- a)扫描数据计算候选频繁k项集的支持度
- b)去除候选频繁k项集中支持度低于闻值的数据集,得到频繁k项集。如果得到的频繁k项集为空,则直接返回频繁k-1项集的集合作为算法结果,算法结束。如果得到的频繁k项集只有一项,则直接返回频繁k项集的集合作为算法结果,算法结束。
- c 基于频繁k项集,连接生成候选频繁k+1项集。 3) 令k=k+1,转入步骤2。
算法案例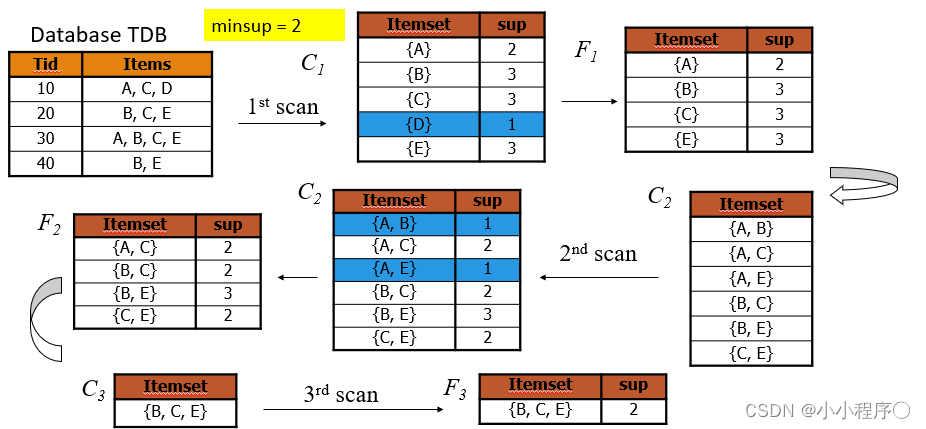
输入:
输出:

算法缺点
- Apriori 在计算的过程中有以下几个缺点可能产生大量的候选集。因为采用排列组合的方式,把可能的项集都组合出来了;每次计算都需要重新扫描数据集,来计算每个项集的支持度
文章来源:https://blog.csdn.net/2201_75381449/article/details/135038135
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!