关于“Python”的核心知识点整理大全47

目录

16.1.10 错误检查
我们应该能够使用有关任何地方的天气数据来运行highs_lows.py中的代码,但有些气象站会 偶尔出现故障,未能收集部分或全部其应该收集的数据。缺失数据可能会引发异常,如果不妥善 地处理,还可能导致程序崩溃。 例如,我们来看看生成加利福尼亚死亡谷的气温图时出现的情况。将文件death_valley_ 2014.csv复制到本章程序所在的文件夹,再修改highs_lows.py,使其生成死亡谷的气温图:
highs_lows.py
--snip--
# 从文件中获取日期、最高气温和最低气温
filename = 'death_valley_2014.csv'
with open(filename) as f:
--snip-- 运行这个程序时,出现了一个错误,如下述输出的最后一行所示:
Traceback (most recent call last):
File "highs_lows.py", line 17, in <module>
high = int(row[1])
ValueError: invalid literal for int() with base 10: '' 该traceback指出,Python无法处理其中一天的最高气温,因为它无法将空字符串(' ')转换 为整数。只要看一下death_valley_2014.csv,就能发现其中的问题:
2014-2-16,,,,,,,,,,,,,,,,,,,0.00,,,-1 其中好像没有记录2014年2月16日的数据,表示最高温度的字符串为空。为解决这种问题, 我们在从CSV文件中读取值时执行错误检查代码,对分析数据集时可能出现的异常进行处理,如 下所示:
highs_lows.py
--snip--
# 从文件中获取日期、最高气温和最低气温
filename = 'death_valley_2014.csv'
with open(filename) as f:
reader = csv.reader(f)
header_row = next(reader)
dates, highs, lows = [], [], []
for row in reader:
1 try:
current_date = datetime.strptime(row[0], "%Y-%m-%d")
high = int(row[1])
low = int(row[3])
except ValueError:
2 print(current_date, 'missing data')
else:
3 dates.append(current_date)
highs.append(high)
lows.append(low)
#根据数据绘制图形
--snip--
#设置图形的格式
4 title = "Daily high and low temperatures - 2014\nDeath Valley, CA"
plt.title(title, fontsize=20)
--snip-- 对于每一行,我们都尝试从中提取日期、最高气温和最低气温(见1)。只要缺失其中一项 数据,Python就会引发ValueError异常,而我们可这样处理:打印一条错误消息,指出缺失数据 的日期(见2)。打印错误消息后,循环将接着处理下一行。如果获取特定日期的所有数据时没 有发生错误,将运行else代码块,并将数据附加到相应列表的末尾(见3)。鉴于我们绘图时使 用的是有关另一个地方的信息,我们修改了标题,在图表中指出了这个地方(见4)。 如果你现在运行highs_lows.py,将发现缺失数据的日期只有一个:
2014-02-16 missing data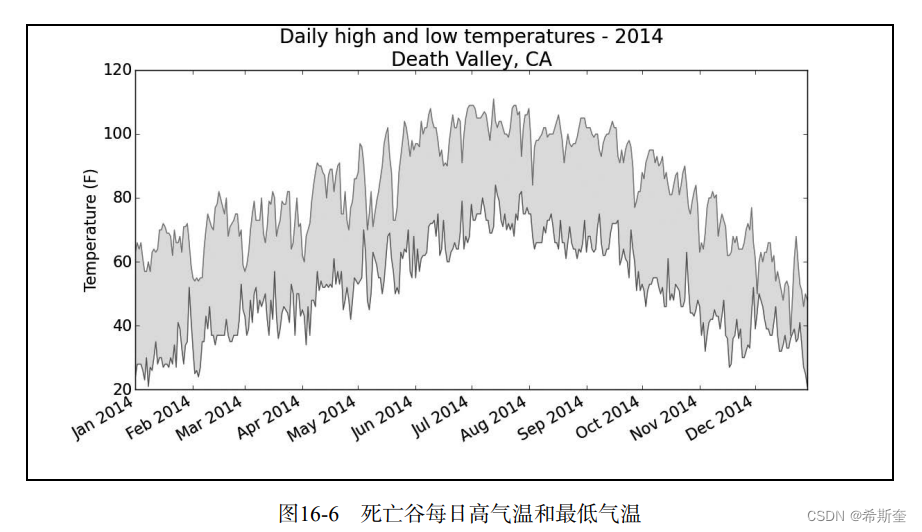
将这个图表与锡特卡的图表对比可知,总体而言,死亡谷比阿拉斯加东南部暖和,这可能符 合预期,但这个沙漠中每天的温差也更大,从着色区域的高度可以明显看出这一点。
使用的很多数据集都可能缺失数据、数据格式不正确或数据本身不正确。对于这样的情形, 可使用本书前半部分介绍的工具来处理。在这里,我们使用了一个try-except-else代码块来处理 数据缺失的问题。在有些情况下,需要使用continue来跳过一些数据,或者使用remove()或del 将已提取的数据删除。可采用任何管用的方法,只要能进行精确而有意义的可视化就好。
16.2 制作世界人口地图:JSON 格式
在本节中,你将下载JSON格式的人口数据,并使用json模块来处理它们。Pygal提供了一个 适合初学者使用的地图创建工具,你将使用它来对人口数据进行可视化,以探索全球人口的分布 情况。
16.2.1 下载世界人口数据
将文件population_data.json复制到本章程序所在的文件夹中,这个文件包含全球大部分国家 1960~2010年的人口数据。Open Knowledge Foundation(http://data.okfn.org/)提供了大量可以免 费使用的数据集,这些数据就来自其中一个数据集。
16.2.2 提取相关的数据
我们来研究一下population_data.json,看看如何着手处理这个文件中的数据:
population_data.json
[
{
"Country Name": "Arab World",
"Country Code": "ARB",
"Year": "1960",
"Value": "96388069"
},
{
"Country Name": "Arab World",
"Country Code": "ARB",
"Year": "1961",
"Value": "98882541.4"
},
--snip--
] 这个文件实际上就是一个很长的Python列表,其中每个元素都是一个包含四个键的字典:国 家名、国别码、年份以及表示人口数量的值。我们只关心每个国家2010年的人口数量,因此我们 首先编写一个打印这些信息的程序:
world_population.py
import json
# 将数据加载到一个列表中
filename = 'population_data.json'
with open(filename) as f:
1 pop_data = json.load(f)
# 打印每个国家2010年的人口数量
2 for pop_dict in pop_data:
3 if pop_dict['Year'] == '2010':
4 country_name = pop_dict['Country Name']
population = pop_dict['Value']
print(country_name + ": " + population)我们首先导入了模块json,以便能够正确地加载文件中的数据,然后,我们将数据存储在 pop_data中(见?)。函数json.load()将数据转换为Python能够处理的格式,这里是一个列表。 在?处,我们遍历pop_data中的每个元素。每个元素都是一个字典,包含四个键—值对,我们将 每个字典依次存储在pop_dict中。 在?处,我们检查字典的'Year'键对应的值是否是2010(由于population_data.json中的值都是 用引号括起的,因此我们执行的是字符串比较)。如果年份为2010,我们就将与'Country Name' 相关联的值存储到country_name中,并将与'Value'相关联的值存储在population中(见?)。接下 来,我们打印每个国家的名称和人口数量。 输出为一系列国家的名称和人口数量:
Arab World: 357868000
Caribbean small states: 6880000
East Asia & Pacific (all income levels): 2201536674
--snip--
Zimbabwe: 12571000我们捕获的数据并非都包含准确的国家名,但这开了一个好头。现在,我们需要将数据转换为Pygal能够处理的格式。
16.2.3 将字符串转换为数字值
population_data.json中的每个键和值都是字符串。为处理这些人口数据,我们需要将表示人 口数量的字符串转换为数字值,为此我们使用函数int():
world_population.py
--snip--
for pop_dict in pop_data:
if pop_dict['Year'] == '2010':
country_name = pop_dict['Country Name']
1 population = int(pop_dict['Value'])
2 print(country_name + ": " + str(population))在1处,我们将每个人口数量值都存储为数字格式。打印人口数量值时,需要将其转换为字 符串(见2)。 然而,对于有些值,这种转换会导致错误,如下所示:
Arab World: 357868000
Caribbean small states: 6880000
East Asia & Pacific (all income levels): 2201536674
--snip--
Traceback (most recent call last):
File "print_populations.py", line 12, in <module>
population = int(pop_dict['Value'])
1 ValueError: invalid literal for int() with base 10: '1127437398.85751'原始数据的格式常常不统一,因此经常会出现错误。导致上述错误的原因是,Python不能直 接将包含小数点的字符串'1127437398.85751'转换为整数(这个小数值可能是人口数据缺失时通 过插值得到的)。为消除这种错误,我们先将字符串转换为浮点数,再将浮点数转换为整数:
2world_population.py
--snip--
for pop_dict in pop_data:
if pop_dict['Year'] == '2010':
country = pop_dict['Country Name']
population = int(float(pop_dict['Value']))
print(country + ": " + str(population)) 函数float()将字符串转换为小数,而函数int()丢弃小数部分,返回一个整数。现在,我们 可以打印2010年的完整人口数据,不会导致错误了:
Arab World: 357868000
Caribbean small states: 6880000
East Asia & Pacific (all income levels): 2201536674
--snip--
Zimbabwe: 12571000每个字符串都成功地转换成了浮点数,再转换为整数。以数字格式存储人口数量值后,就可 以使用它们来制作世界人口地图了。
16.2.4 获取两个字母的国别码
制作地图前,还需要解决数据存在的最后一个问题。Pygal中的地图制作工具要求数据为特 定的格式:用国别码表示国家,以及用数字表示人口数量。处理地理政治数据时,经常需要用到 几个标准化国别码集。population_data.json中包含的是三个字母的国别码,但Pygal使用两个字母 的国别码。我们需要想办法根据国家名获取两个字母的国别码。 Pygal使用的国别码存储在模块i18n(internationalization的缩写)中。字典COUNTRIES包含的 键和值分别为两个字母的国别码和国家名。要查看这些国别码,可从模块i18n中导入这个字典, 并打印其键和值:
countries.py
from pygal.i18n import COUNTRIES
1 for country_code in sorted(COUNTRIES.keys()):
print(country_code, COUNTRIES[country_code])在上面的for循环中,我们让Python将键按字母顺序排序(见?),然后打印每个国别码及其 对应的国家:
ad Andorra
ae United Arab Emirates
af Afghanistan
--snip--
zw Zimbabwe 为获取国别码,我们将编写一个函数,它在COUNTRIES中查找并返回国别码。我们将这个函 数放在一个名为country_codes的模块中,以便能够在可视化程序中导入它:
country_codes.py
from pygal.i18n import COUNTRIES
1 def get_country_code(country_name):
"""根据指定的国家,返回Pygal使用的两个字母的国别码"""
3 for code, name in COUNTRIES.items():
? if name == country_name:
return code
# 如果没有找到指定的国家,就返回None
4 return None
print(get_country_code('Andorra'))
print(get_country_code('United Arab Emirates'))
print(get_country_code('Afghanistan')) 往期快速传送门👆(在文章最后):
感谢大家的支持!欢迎订阅收藏!专栏将持续更新!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!