谷歌推出了一种名为提示扩展(Prompt Expansion)的创新框架,旨在帮助用户更轻松地创造出既高质量又多样化的图像。

谷歌推出了一种名为提示扩展(Prompt Expansion)的创新框架,旨在帮助用户更轻松地创造出既高质量又多样化的图像。
论文标题:
Prompt Expansion for Adaptive Text-to-Image Generation
论文链接:
https://arxiv.org/pdf/2312.16720.pdf
问题陈述
文本到图像生成模型能够根据文本提示创造相应图像,但这通常需要精确和详细的指引。然而,存在两大挑战:
提示工程复杂:用户需精心设计提示以生成高质量图像。这涉及使用专业术语(如“35mm”、“背光”等)和独特描述(如“大胆创新”)。由于有效提示的不稳定性,用户需不断试验,这限制了模型的易用性和创造力。
图像多样性不足:即便用户提示未具体指定细节,生成的图像往往缺乏变化。例如,“南瓜灯设计”的提示可能导致风格和视角相似的图像。这不仅可能加剧社会偏见,还限制了探索更多元图像的可能。

提示扩展框架
提出的框架旨在通过将基本文本查询扩展为一组详细且多样的文本提示来缓解这些挑战。这些扩展提示,当输入到文本到图像模型中时,可以生成更多样化的高质量和审美上令人满意的图像。论文专注于减少用户在制作详细提示方面的努力,并提高生成图像的多样性和质量。
基础模型
一个文本到文本的模型,接收用户的文本查询(query),输出扩展的文本提示。该模型基于特别创建的提示扩展数据集进行训练。
再微调
基础模型进一步微调,以与下游的文本到图像模型对齐,优化它以生成导致高质量图像输出的提示。
可控制生成
该框架允许使用前缀来进行受控制的提示扩展,这些前缀指导生成的扩展类型。这包括添加特定细节、提升图像美感或促进生成图像的多样性等选项。
数据集和方法论
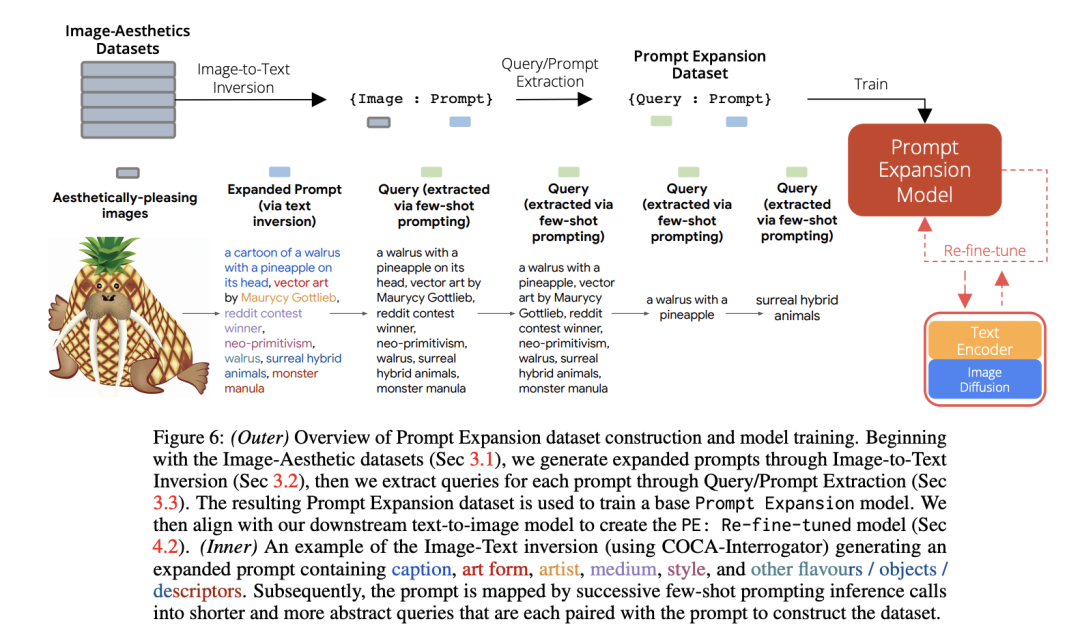
提示扩展(PE)框架需要一个模型接受用户文本查询作为输入,并返回N个文本提示作为输出,这样通过文本到图像的生成,这N个文本提示将返回一组与查询对齐的N个多样化、美观的图像。为了训练一个PE模型,需要一个将查询映射到提示的数据集。研究团队采用逆向构建的方式来创建。首先收集审美高质量的图像,包括模型生成的和自然图像。其次,将图像反转成与之紧密对应的提示文本,包括备用文本术语(将其称为“flavors”)。最后将反转的文本映射到一系列更贴近用户输入的高层次查询(参见3.3节)。这些查询与第二步的提示配对,形成了{查询:提示}( {query:prompt})数据集。
图像-审美数据集
研究团队整理了两个图像数据集:第一个是Webli-Align,由Webli和Align(数据集中的图像组成,筛选出高MUSIQ审美评分的图像。第二个是CrowdSourced,通过众包方式从文本到图像模型中获取输出。研究团队提供了一个类似于Gradio的文本到图像生成界面,允许来自大型组织的用户输入提示来生成图像。用户还可以对他们喜欢的图像进行点赞,研究团队利用这种点赞信号只保留最吸引人的图像,包括80k张Webli-Align(自然)和40k张CrowdSourced(生成)图像。
图像到文本反转
第二步是将图像-审美数据集中的图像反转成提示文本。查询是用户提供的输入,而提示是生成特定图像的文本。研究团队使用Interrogator(CLIP-Interrogator)方法进行图像到文本反转,通过串联生成的:(i)标题,和(ii)一组“口味”来计算出提示文本。标题是对图像内容的描述(例如,谁、什么、在哪里、何时)。口味是指改变图像风格的描述性词语或短语。
查询/提示提取
研究团队在数据集准备的最后阶段生成了与反转文本提示匹配的用户查询。他们使用FLAN-PaLMChilla 62B模型和少量示例提示来生成不同长度的查询和长提示。这些示例提示的格式是{提示:查询},示例可以在他们的文档中找到。对于每个反转提示,团队添加了示例提示作为上下文,并用模型生成相应查询。这样,他们得到了一系列长度不同的查询,适应于各种扩展提示。
方法
研究团队设计训练提示扩展模型根据以下两个阶段:
(一)在提示扩展数据集上训练一个基础提示扩展模型。
(二)针对下游的文本到图像模型对基础模型进行重新微调。
基础模型
研究团队构建的提示扩展框架基于文本生成模型,采用PaLM 2架构进行训练,其核心功能是把用户简单的文本查询转换成更丰富的提示文本。这些扩展通过添加关键词来提升图像质量,并引入额外细节以增强图像多样性。
重新微调
基础模型训练完毕后,研究团队进行了重新微调,以提升模型生成的图像质量。这个步骤通过筛选与下游文本到图像模型(如Imagen)更匹配的提示来进行,目的是生成更高质量的图像。
可控制生成
前缀控制:模型可利用特定前缀来产生指定类型的提示扩展,如增加更多调味料或多样化细节。
前缀逐渐减少:在训练过程中,模型逐步学会识别合适的前缀,以适应不同的查询。
多步骤扩展:用户可以从一系列生成的提示中选择一个,再次输入模型进行迭代,这一过程无需手动文本编辑。
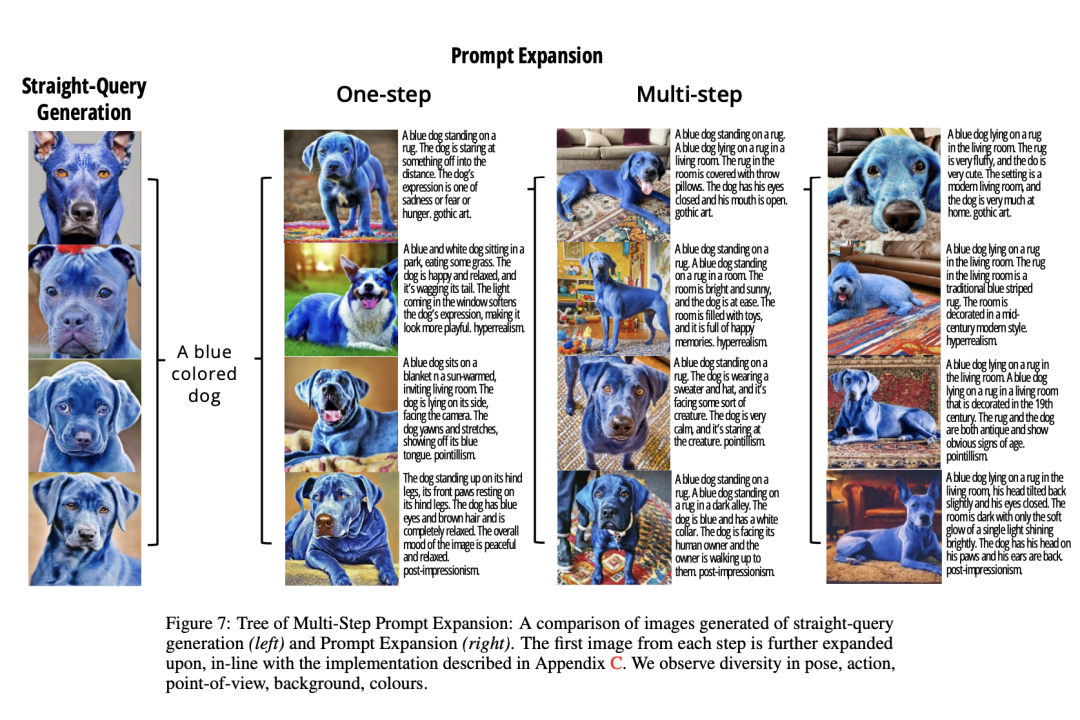
提示扩展框架的目的是简化用户创建多样化和审美上吸引人的图像的过程。研究团队推出了一种新的交互方式,允许用户通过选择图像来启动下一轮的迭代生成。图中展示了基于简单文本提示“一只蓝色的狗”直接生成的图像(左侧),以及通过提示扩展生成的图像(右侧)。左侧图像由于使用了相同的简单提示,因此外观相似。相比之下,右侧图像通过在提示中加入更多细节,如场景、动作和艺术风格,因此显得更为多样和详尽。右侧上部展示了在初始提示基础上经过一次扩展后的结果,下部则展示了经过多次扩展后,图像的创意和细节变得更加丰富。在自动评估和人工评估中,模型在多样性、审美和文本-图像一致性方面都展现了优于基线方法的性能。
实验
评估设置
实验设计使用了两组来源不同的查询样本:一组是代表不同领域和语言特点的PartiPrompts(PP)数据集中的200个提示;另一组是通过应用于Webli-Align(WA)图像的PE数据集生成过程构造的500个新测试查询。查询被分类为抽象的、具体的、短的(小于4个词)、中等长度的(4-7个词)或长的(超过7个词)。
模型变种
对比评估了几种不同的提示扩展模型变种:包括一个少量样本提示的基线模型,基础的提示扩展模型,以及使用完整提示扩展流程训练的PE:Re-fine-tuned模型。所有的模型生成的提示都作为输入提供给Imagen,并使用以下评估指标来衡量。
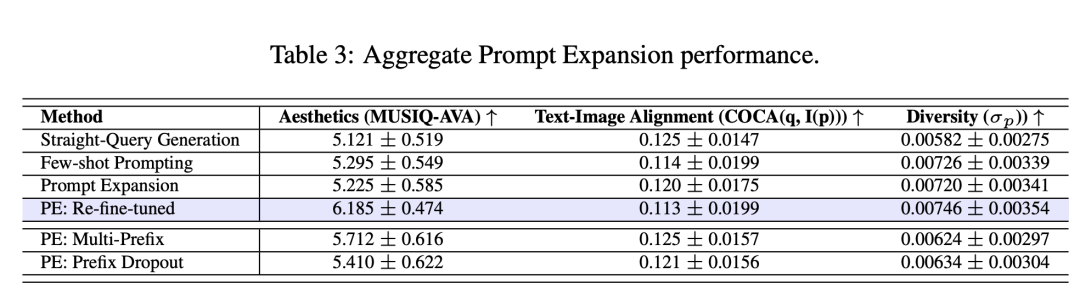
自动评估指标:
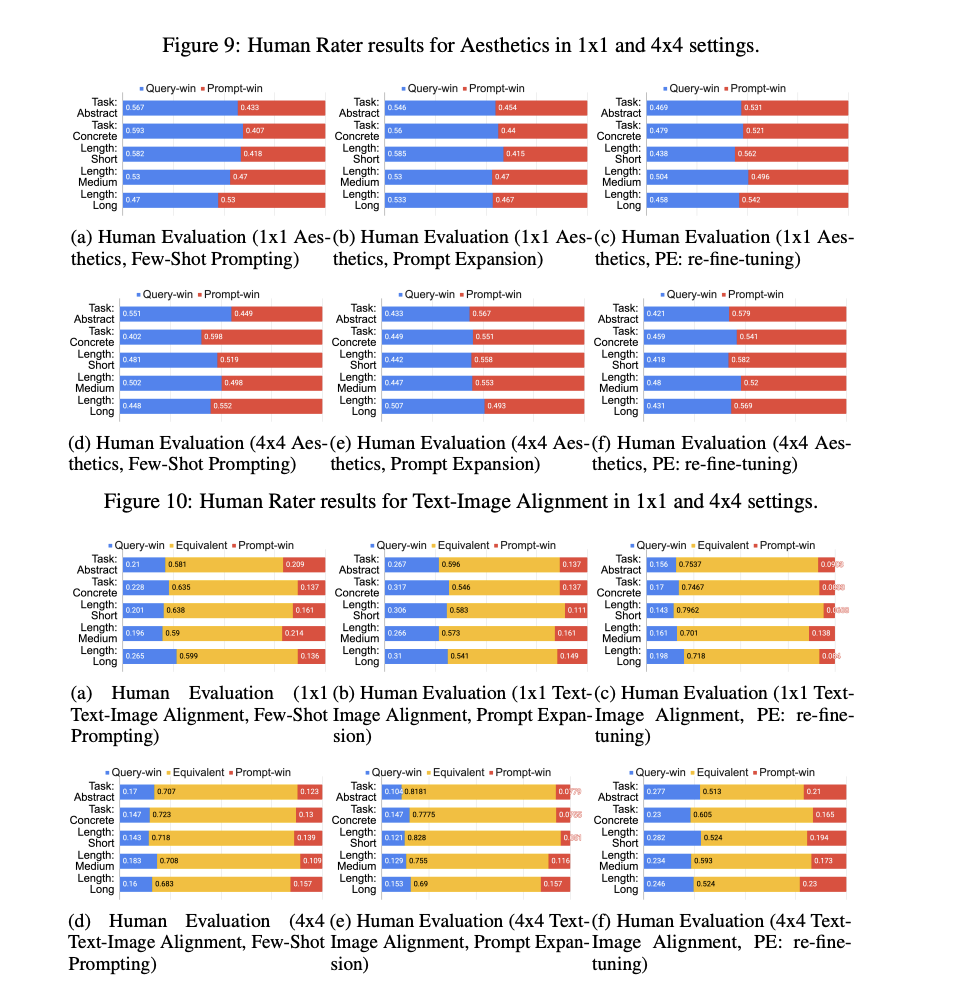
美学评估:使用MUSIQ模型(在AVA数据集上预训练)来评估图像的审美质量。多样性评估:使用COCA图像嵌入的方差来评估生成图像的多样性。文本-图像对齐评估:使用查询文本的COCA文本嵌入与生成图像的COCA图像嵌入之间的余弦相似度来评估文本-图像的对齐度。人类评估任务设计:进行了一项侧面对侧(SxS)的评估任务,其中评估员需要对给定文本查询生成的一对图像进行比较,每个图像由一种PE模型或另一种模型生成的提示生成。评估的两个主要标准是美学偏好和文本-图像对齐。
实验结果
多样性提升:提示扩展模型提高了生成图像的多样性,这一点在所有系统中都得到了一致的确认。尤其是经过重新微调的模型(PE: Re-fine-tuned),在多样性方面表现略胜一筹。
美学改进:提示扩展模型特别是经过重新微调的模型,在美学评分方面比直接查询生成的基线方法有了显著提升。这表明了模型相对于特定的下游文本到图像模型的优化部分对于提升图像美学值至关重要。
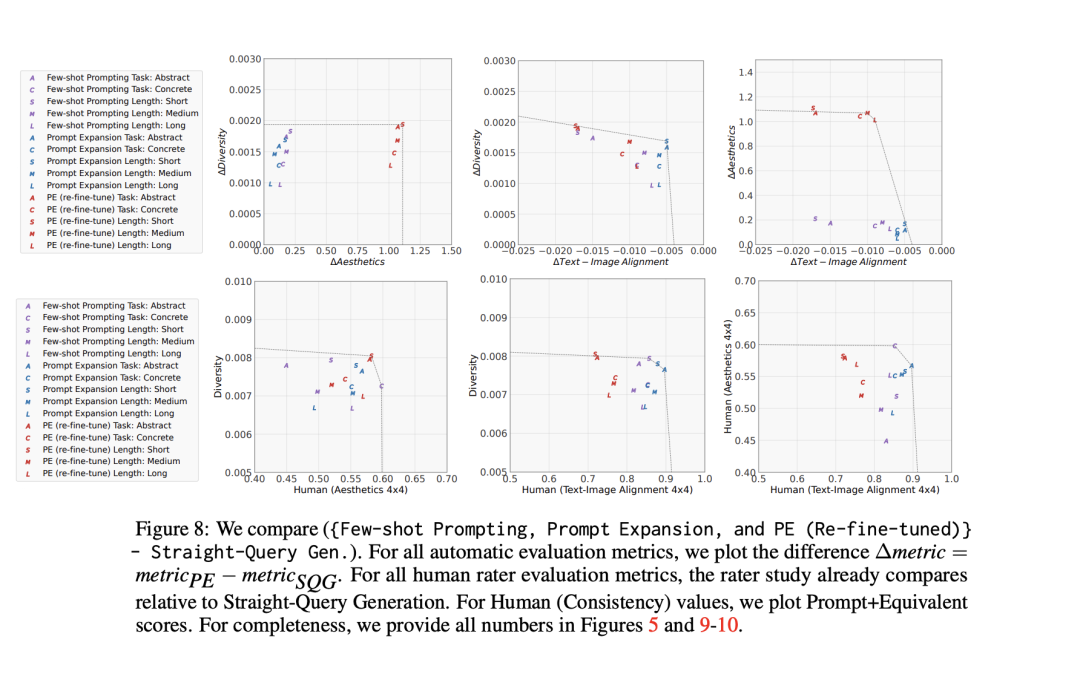
多样性与美学之间的关系:研究团队假设,增加的多样性可以提升生成图像的美学质量,因为多样性更高的提示可能会生成更吸引人的图像。实验结果表明,选择最佳图像(4x4设置)与随机选择图像(1x1设置)相比,前者在美学上有更高的获胜率,这进一步证实了多样性对于美学的积极影响。
文本-图像对齐与美学之间的平衡:研究团队注意到,虽然扩展提示可以设计得保留原始查询的所有语义,但它永远无法预期在与用户原始意图的对齐度上有所增加。因此,提示扩展的主要目标是在优化美学和多样性的同时,尽量减少对齐分数的下降。
可控制生成的效果:实验还表明,使用多前缀(PE: Multi-Prefix)的模型在美学上的表现优于基础的提示扩展模型,并且在文本-图像对齐上没有损失。这意味着,即使在没有显式优化的情况下,控制生成也能带来性能上的提升。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!