hadoop自动获取时间
1、自动获取前15分钟
substr(from_unixtime(unix_timestamp(concat(substr('20240107100000',1,4),'-',substr('20240107100000',5,2),'-',substr('20240107100000',7,2),' ',substr('20240107100000',9,2),':',substr('20240107100000',11,2),':','00'))-15*60,'yyyyMMddHHmmss'),1)
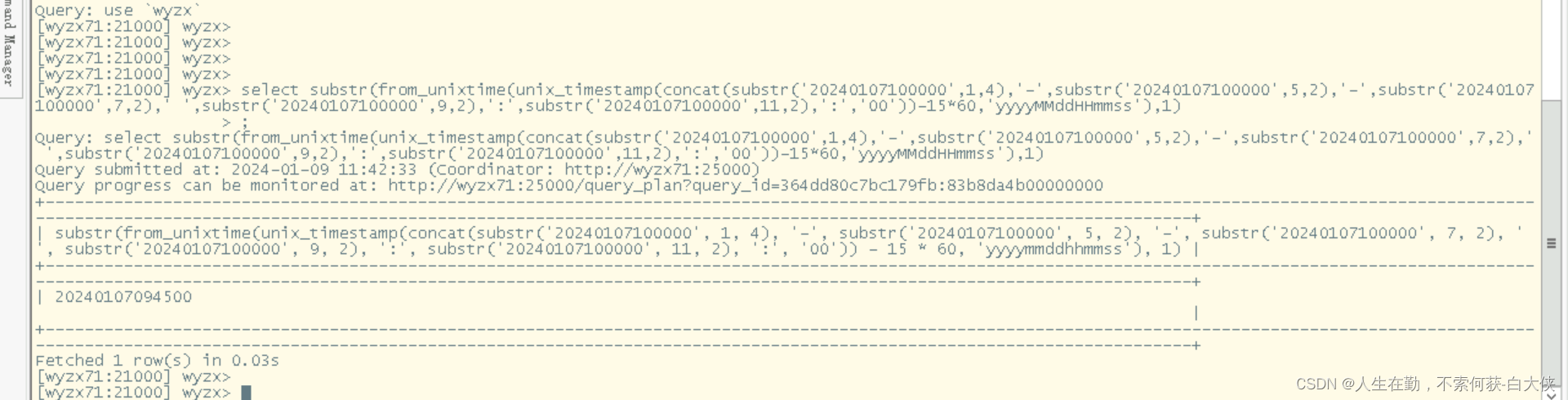
unix_timestamp:是将字符串的时间20240107100000转换成时间类型。
from_unixtime:将时间格式化
substr:转成字符串
最后15*60,将减去对应的秒数,作用是在当前时刻减去15分钟。利用这个逻辑可以减去其他时间,如一个小时,可以减去60*60。
2、获取当前时间
使用CURRENT_TIMESTAMP()
select CURRENT_TIMESTAMP();
±------------------------------+
| current_timestamp() |
±------------------------------+
| 2024-01-09 11:18:15.646162000 |
±------------------------------+
使用now()
select now();
±------------------------------+
| now() |
±------------------------------+
| 2024-01-09 11:18:28.925986000 |
±------------------------------+
这两个函数的作用是一致的,获取到的结果是时间戳。
另外可以在建表的时候,直接指定时间 datecreated timestamp NULL DEFAULT CURRENT_TIMESTAMP
但是不能将CURRENT_TIMESTAMP设置为1列以上。
要想只获取日期,不获取时间戳,用
to_date(now())
select to_date(now());
±---------------+
| to_date(now()) |
±---------------+
| 2024-01-09 |
±---------------+
其他不常用的时间:
-- 获取年份
select year(now())
-- 输出:2022
-- 获取季度
select quarter(now())
-- 输出:4
-- 获取月份
select month(now())
-- 输出:10
-- 获取月份英文名
select monthname(now())
-- 输出:October
-- 获取日期中的日
select day(now())
-- 输出:11
-- 获取小时
select HOUR(now())
-- 输出:14
-- 获取当天为每周第N天,周日为第一天
select DAYOFWEEK(now())
-- 输出:3
-- 获取明天(日期加减)
select date_add(now(),interval 1 days)
-- 输出:2022-10-12 14:39:26.916
3、impala自动获取两天前,并输出string格式的时间
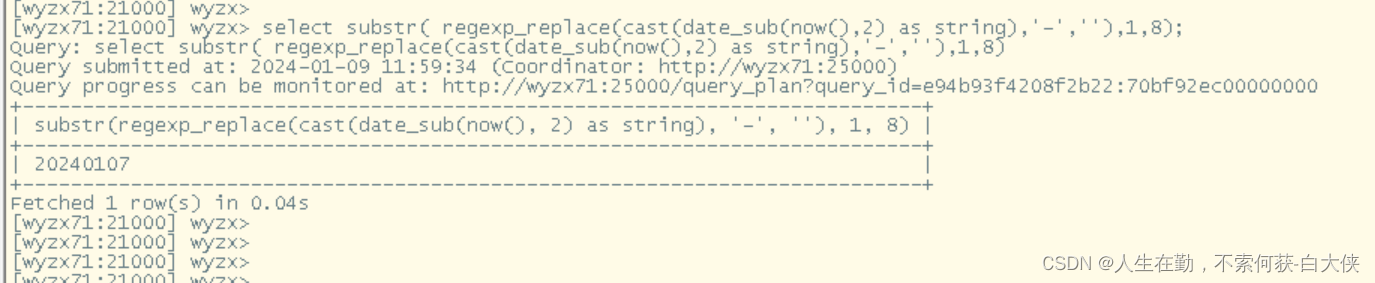
使用substr( regexp_replace(cast(date_sub(now(),2) as string),'-',''),1,8)
date_sub(now(),2) 取到前两天
cast() 转换成string
regexp_replace() 将时间戳中的‘-’去掉
最后取到日期的前2天。
4、impala自动获取两天后,并输出string格式的时间
将上述 date_sub() 替换成date_add()。
即select substr( regexp_replace(cast(date_add(now(),2) as string),'-',''),1,8);

5、impala获取本月有多少天
使用 select
32-dayofmonth(date_add(now(),+32-dayofmonth(now())))

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!