Spring源码之依赖注入(二)
一. @Autowire底层注入逻辑
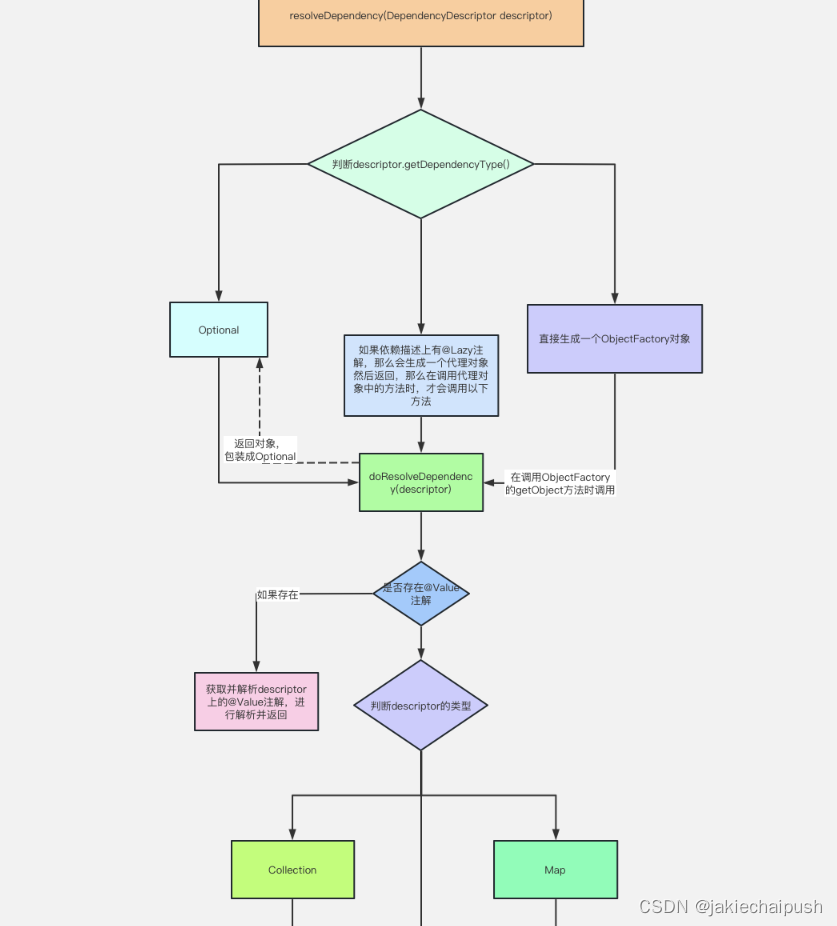

前面我们分析了Spring时如何找到某个目标类的所有注入点这一个核心逻辑,但还没又对核心注入方法inject进行详细分析,下面我们就来详细分析Spring拿到所有的注入点之后,是如何实现注入的逻辑的。首先我们回到inject方法。
public void inject(Object target, @Nullable String beanName, @Nullable PropertyValues pvs) throws Throwable {
Collection<InjectedElement> checkedElements = this.checkedElements;
Collection<InjectedElement> elementsToIterate =
(checkedElements != null ? checkedElements : this.injectedElements);
if (!elementsToIterate.isEmpty()) {
// 遍历每个注入点进行依赖注入
for (InjectedElement element : elementsToIterate) {
element.inject(target, beanName, pvs);
}
}
}
上面代码最核心的就是遍历InjectionMetadata中的this.checkedElements,也就是注入点集合。然后针对不同的element类型会调用不同的注入方法(在注册注入点时已经说到了这两种类型,分别是AutowiredFieldElement和AutowiredMethodElement)。具体实现注入的逻辑是调用的这段代码element.inject(target, beanName, pvs);。然后对于不同的注入类型(属性注入和方法注入,它们是有不同的实现类的)

1. 属性注入逻辑
首先我们看字段注入的inject源码:
//PropertyValues 对象,封装了要应用到目标对象的属性值
@Override
protected void inject(Object bean, @Nullable String beanName, @Nullable PropertyValues pvs) throws Throwable {
//获得当前要处理类的字段
Field field = (Field) this.member;
Object value;
//检查是否启用了缓存。如果启用了缓存,会尝试从缓存中获取已解析的字段值。如果缓存中不存在,会捕获 NoSuchBeanDefinitionException 异常,然后重新解析字段值。
if (this.cached) {
// 对于原型Bean,第一次创建的时候,也找注入点,然后进行注入,此时cached为false,注入完了之后cached为true
// 第二次创建的时候,先找注入点(此时会拿到缓存好的注入点),也就是AutowiredFieldElement对象,此时cache为true,也就进到此处了
// 注入点内并没有缓存被注入的具体Bean对象,而是beanName,这样就能保证注入到不同的原型Bean对象
try {
//尝试从缓存中获取已解析的字段值。如果缓存中存在,则使用该值。否则,会重新调用 resolveFieldValue 方法解析字段值。
value = resolvedCachedArgument(beanName, this.cachedFieldValue);
}
catch (NoSuchBeanDefinitionException ex) {
//如果没有启用缓存,或者缓存中没有有效的值,将调用 resolveFieldValue 方法从 BeanFactory 中解析字段值。
value = resolveFieldValue(field, bean, beanName);
}
}
else {
// 根据filed从BeanFactory中查到的匹配的Bean对象
value = resolveFieldValue(field, bean, beanName);
}
// 反射给filed赋值
if (value != null) {
ReflectionUtils.makeAccessible(field);
field.set(bean, value);
}
}
这段代码主要处理了字段注入的逻辑,包括缓存的使用、字段值的解析和反射赋值。这是 Spring 框架实现自动装配的一部分,确保依赖关系得到正确地建立。当我们缓存中没有我们要注入的有效值,或者是压根就没有缓存时,会调用 resolveFieldValue(field, bean, beanName);从BeanFactory中解析字段。
@Nullable
private Object resolveFieldValue(Field field, Object bean, @Nullable String beanName) {
//创建一个 DependencyDescriptor 对象,该对象包含有关要注入的字段的信息。设置字段所属的类以及是否为必需的标志
DependencyDescriptor desc = new DependencyDescriptor(field, this.required);
desc.setContainingClass(bean.getClass());
//初始化用于存储自动装配的Bean名称的集合 autowiredBeanNames,检查 beanFactory 是否为null,并获取 TypeConverter 对象。
Set<String> autowiredBeanNames = new LinkedHashSet<>(1);
Assert.state(beanFactory != null, "No BeanFactory available");
TypeConverter typeConverter = beanFactory.getTypeConverter();
Object value;
try {
//使用 beanFactory 的 resolveDependency 方法解析字段值。如果解析失败,抛出 UnsatisfiedDependencyException 异常,其中包含相关的信息,如字段信息、目标Bean名称和异常原因。
value = beanFactory.resolveDependency(desc, beanName, autowiredBeanNames, typeConverter);
}
catch (BeansException ex) {
throw new UnsatisfiedDependencyException(null, beanName, new InjectionPoint(field), ex);
}
synchronized (this) {
if (!this.cached) {
Object cachedFieldValue = null;
if (value != null || this.required) {
cachedFieldValue = desc;
// 注册一下beanName依赖了autowiredBeanNames,
registerDependentBeans(beanName, autowiredBeanNames);
if (autowiredBeanNames.size() == 1) {
String autowiredBeanName = autowiredBeanNames.iterator().next();
if (beanFactory.containsBean(autowiredBeanName) &&
beanFactory.isTypeMatch(autowiredBeanName, field.getType())) {
// 构造一个ShortcutDependencyDescriptor作为缓存,保存了当前filed所匹配的autowiredBeanName,而不是对应的bean对象(考虑原型bean)
cachedFieldValue = new ShortcutDependencyDescriptor(
desc, autowiredBeanName, field.getType());
}
}
}
this.cachedFieldValue = cachedFieldValue;
this.cached = true;
}
}
return value;
}
}
上面代码主要是解析字段的值和处理自动装配的逻辑。首先它调用了beanFactory.resolveDependency来解析字段值。
@Override
@Nullable
/**
descriptor:要解析的依赖项的描述符
requestingBeanName: 请求解析依赖项的 Bean 的名称(可能为null)
autowiredBeanNames: 自动装配的Bean名称的集合(可能为null)。
typeConverter: 用于类型转换的 TypeConverter 对象(可能为null)
**/
public Object resolveDependency(DependencyDescriptor descriptor, @Nullable String requestingBeanName,
@Nullable Set<String> autowiredBeanNames, @Nullable TypeConverter typeConverter) throws BeansException {
// 用来获取方法入参名字的
descriptor.initParameterNameDiscovery(getParameterNameDiscoverer());
// 所需要的类型是Optional
if (Optional.class == descriptor.getDependencyType()) {
return createOptionalDependency(descriptor, requestingBeanName);
}
// 所需要的的类型是ObjectFactory,或ObjectProvider
else if (ObjectFactory.class == descriptor.getDependencyType() ||
ObjectProvider.class == descriptor.getDependencyType()) {
return new DependencyObjectProvider(descriptor, requestingBeanName);
}
else if (javaxInjectProviderClass == descriptor.getDependencyType()) {
return new Jsr330Factory().createDependencyProvider(descriptor, requestingBeanName);
}
else {
// 在属性或set方法上使用了@Lazy注解,那么则构造一个代理对象并返回,真正使用该代理对象时才进行类型筛选Bean
Object result = getAutowireCandidateResolver().getLazyResolutionProxyIfNecessary(
descriptor, requestingBeanName);
if (result == null) {
// descriptor表示某个属性或某个set方法
// requestingBeanName表示正在进行依赖注入的Bean
result = doResolveDependency(descriptor, requestingBeanName, autowiredBeanNames, typeConverter);
}
return result;
}
}
bject result = getAutowireCandidateResolver().getLazyResolutionProxyIfNecessary(descriptor, requestingBeanName); 代码段的目的是在实际进行依赖项解析之前,检查是否需要懒加载。如果需要懒加载,会通过调用 getLazyResolutionProxyIfNecessary 方法获取懒加载的代理对象,然后将该代理对象用作最终的依赖项。
在 Spring 中,懒加载是一种策略,用于延迟对象的实际创建和初始化,直到第一次被真正需要时。这有助于提高性能,特别是在应用程序启动时,不会立即创建所有可能不会被使用的 Bean。懒加载通常通过代理对象来实现,代理对象会在真正需要时触发目标 Bean 的创建和初始化。这在大型应用程序中可以显著减少启动时间。
上面代码的逻辑主要是首先处理了两种特殊类型的依赖,然后判断所依赖的对象是否是懒加载,如果是懒加载我们就会返回所依赖对象的代理对象返回(只有当我们真正使用到这个对象时,才会加载该对象),如果不是懒加载对象,就调用doResolveDependency开始真正解析要注入的bean。
@Nullable
/*
descriptor: 要解析的依赖项的描述符。
beanName: 当前正在进行依赖注入的 Bean 的名称(可能为null)。
autowiredBeanNames: 自动装配的Bean名称的集合(可能为null)。
typeConverter: 用于类型转换的 TypeConverter 对象(可能为null)。
*/
public Object doResolveDependency(DependencyDescriptor descriptor, @Nullable String beanName,
@Nullable Set<String> autowiredBeanNames, @Nullable TypeConverter typeConverter) throws BeansException {
//在进行依赖项解析之前,通过调用setCurrentInjectionPoint方法设置当前的注入点,以便后续的解析可以获取到相关的上下文信息
InjectionPoint previousInjectionPoint = ConstructorResolver.setCurrentInjectionPoint(descriptor);
try {
// 如果当前descriptor之前做过依赖注入了,则可以直接取shortcut了,相当于缓存,尝试获取缓存的快捷方式,如果存在的话直接返回。这是为了提高性能,避免重复解析相同的依赖项。
Object shortcut = descriptor.resolveShortcut(this);
if (shortcut != null) {
return shortcut;
}
Class<?> type = descriptor.getDependencyType();
// 获取@Value所指定的值
Object value = getAutowireCandidateResolver().getSuggestedValue(descriptor);
if (value != null) {
if (value instanceof String) {
// 占位符填充(${})
String strVal = resolveEmbeddedValue((String) value);
BeanDefinition bd = (beanName != null && containsBean(beanName) ?
getMergedBeanDefinition(beanName) : null);
// 解析Spring表达式(#{})
value = evaluateBeanDefinitionString(strVal, bd);
}
// 将value转化为descriptor所对应的类型
TypeConverter converter = (typeConverter != null ? typeConverter : getTypeConverter());
try {
return converter.convertIfNecessary(value, type, descriptor.getTypeDescriptor());
}
catch (UnsupportedOperationException ex) {
// A custom TypeConverter which does not support TypeDescriptor resolution...
return (descriptor.getField() != null ?
converter.convertIfNecessary(value, type, descriptor.getField()) :
converter.convertIfNecessary(value, type, descriptor.getMethodParameter()));
}
}
// 如果descriptor所对应的类型是数组、Map这些,就将descriptor对应的类型所匹配的所有bean方法,不用进一步做筛选了
Object multipleBeans = resolveMultipleBeans(descriptor, beanName, autowiredBeanNames, typeConverter);
if (multipleBeans != null) {
return multipleBeans;
}
// 找到所有Bean,key是beanName, value有可能是bean对象,有可能是beanClass
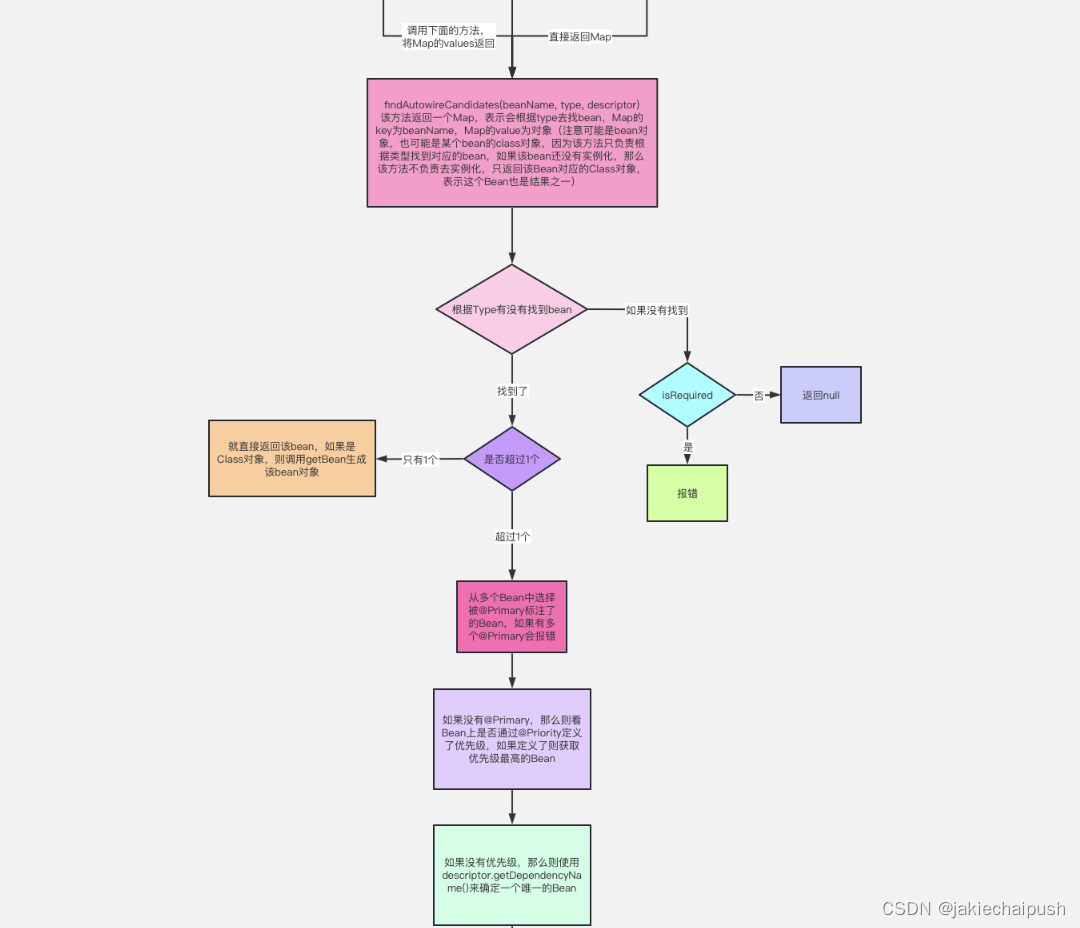
Map<String, Object> matchingBeans = findAutowireCandidates(beanName, type, descriptor);
if (matchingBeans.isEmpty()) {
// required为true,抛异常
if (isRequired(descriptor)) {
raiseNoMatchingBeanFound(type, descriptor.getResolvableType(), descriptor);
}
return null;
}
String autowiredBeanName;
Object instanceCandidate;
if (matchingBeans.size() > 1) {
// 根据类型找到了多个Bean,进一步筛选出某一个, @Primary-->优先级最高--->name
autowiredBeanName = determineAutowireCandidate(matchingBeans, descriptor);
if (autowiredBeanName == null) {
if (isRequired(descriptor) || !indicatesMultipleBeans(type)) {
return descriptor.resolveNotUnique(descriptor.getResolvableType(), matchingBeans);
}
else {
return null;
}
}
instanceCandidate = matchingBeans.get(autowiredBeanName);
}
else {
// We have exactly one match.
Map.Entry<String, Object> entry = matchingBeans.entrySet().iterator().next();
autowiredBeanName = entry.getKey();
instanceCandidate = entry.getValue();
}
// 记录匹配过的beanName
if (autowiredBeanNames != null) {
autowiredBeanNames.add(autowiredBeanName);
}
// 有可能筛选出来的是某个bean的类型,此处就进行实例化,调用getBean
if (instanceCandidate instanceof Class) {
instanceCandidate = descriptor.resolveCandidate(autowiredBeanName, type, this);
}
Object result = instanceCandidate;
if (result instanceof NullBean) {
if (isRequired(descriptor)) {
raiseNoMatchingBeanFound(type, descriptor.getResolvableType(), descriptor);
}
result = null;
}
if (!ClassUtils.isAssignableValue(type, result)) {
throw new BeanNotOfRequiredTypeException(autowiredBeanName, type, instanceCandidate.getClass());
}
return result;
}
finally {
ConstructorResolver.setCurrentInjectionPoint(previousInjectionPoint);
}
}
上面代码涵盖了对不同情况的处理,包括通过注解、类型、名称等方式进行 Bean 的筛选和解析。同时,支持了类型转换、@Value 注解、Spring 表达式的解析等功能,以满足复杂的依赖项解析需求。
首先处理了@Value注解,调用的是Object value = getAutowireCandidateResolver().getSuggestedValue(descriptor);。
@Override
@Nullable
public Object getSuggestedValue(DependencyDescriptor descriptor) {
//从 DependencyDescriptor 中获取注解(annotations),并通过 findValue 方法寻找与注解相关联的值。
Object value = findValue(descriptor.getAnnotations());
if (value == null) {
MethodParameter methodParam = descriptor.getMethodParameter();
if (methodParam != null) {
value = findValue(methodParam.getMethodAnnotations());
}
}
return value;
}
整个方法的目的是根据依赖项的描述符,尝试从相关的注解中获取建议值。这可以用于处理一些特殊情况,例如通过注解指定的默认值等。在 Spring 中,@Value 注解就是一个常见的用例,通过它可以在字段或方法参数上指定默认值。(其实这里就会获得我们在@Value中写入的值)。
然后继续回到doResolveDependency方法。
//判断@Value注解是否指定了默认值
if (value != null) {
//如果值的类型是String(一般情况下都是String)
if (value instanceof String) {
// 占位符填充(${})
//resolveEmbeddedValue 方法会尝试解析这个占位符,替换成实际的属性值。
String strVal = resolveEmbeddedValue((String) value);
BeanDefinition bd = (beanName != null && containsBean(beanName) ?
getMergedBeanDefinition(beanName) : null);
// 解析Spring表达式(#{})
value = evaluateBeanDefinitionString(strVal, bd);
}
// 将value转化为descriptor所对应的类型
TypeConverter converter = (typeConverter != null ? typeConverter : getTypeConverter());
try {
return converter.convertIfNecessary(value, type, descriptor.getTypeDescriptor());
}
catch (UnsupportedOperationException ex) {
// A custom TypeConverter which does not support TypeDescriptor resolution...
return (descriptor.getField() != null ?
converter.convertIfNecessary(value, type, descriptor.getField()) :
converter.convertIfNecessary(value, type, descriptor.getMethodParameter()));
}
}
上面代码首先如果value是String类型它会首先处理占位符#{}和${}填充,假设有一个Spring Bean的配置如下:
@Configuration
public class AppConfig {
@Value("${app.message}")
private String appMessage;
@Bean
public MyBean myBean() {
return new MyBean(appMessage);
}
}
在这个配置中,MyBean 类的实例化依赖于一个名为 app.message 的属性值。这个属性值从Spring的Enviroment中获取(Environment 接口是一个核心接口,用于表示应用程序运行环境的抽象。它提供了一种方式来访问应用程序配置的属性以及配置文件中的属性值,或者是操作系统相关配置。Environment 接口的实现类通常是 StandardEnvironment 或其子类。)
在 Spring 中,#{} 是用于表示 SpEL(Spring Expression Language)表达式的语法。SpEL 是一种强大的表达式语言,支持在运行时对属性进行计算和操作。让我们通过一个简单的案例来演示如何使用 #{} 进行 SpEL 表达式的解析
@Configuration
public class DataSourceConfig {
@Value("#{environment['max.connections'] ?: 10}")
private int maxConnections;
@Bean
public DataSource dataSource() {
// 创建并配置数据源
HikariConfig config = new HikariConfig();
config.setMaximumPoolSize(maxConnections);
// 其他配置...
return new HikariDataSource(config);
}
}
这个配置类中,我们使用了 @Value 注解和 #{} 表达式,从环境属性中获取 max.connections 的值,如果该属性不存在则使用默认值 10。这个值将用于设置 HikariCP 连接池的最大活动连接数。
继续回到doResolveDependency,处理完@Value的占位符的信息,下面就可以开始类型转换了,主要目的是将Value值转换为我们所需要注入的属性类型值。处理完Value注解后,就开始处理数组和Map类型了。
// 如果descriptor所对应的类型是数组、Map这些,就将descriptor对应的类型所匹配的所有bean方法,不用进一步做筛选了
Object multipleBeans = resolveMultipleBeans(descriptor, beanName, autowiredBeanNames, typeConverter);
if (multipleBeans != null) {
return multipleBeans;
}
如果依赖项的类型是数组、Map等,直接解析所有匹配的 Bean 方法,不进行进一步筛选。调用resolveMultipleBeans函数。
@Nullable
private Object resolveMultipleBeans(DependencyDescriptor descriptor, @Nullable String beanName,
@Nullable Set<String> autowiredBeanNames, @Nullable TypeConverter typeConverter) {
Class<?> type = descriptor.getDependencyType();
//如果依赖项的类型是 Stream,则会找到所有与类型匹配的 Bean,构造成一个 Stream,并进行排序(如果有序)。这种情况下,返回的是 Stream 对象。
if (descriptor instanceof StreamDependencyDescriptor) {
// 找到type所匹配的所有bean
Map<String, Object> matchingBeans = findAutowireCandidates(beanName, type, descriptor);
if (autowiredBeanNames != null) {
autowiredBeanNames.addAll(matchingBeans.keySet());
}
// 构造成一个stream
Stream<Object> stream = matchingBeans.keySet().stream()
.map(name -> descriptor.resolveCandidate(name, type, this))
.filter(bean -> !(bean instanceof NullBean));
// 排序
if (((StreamDependencyDescriptor) descriptor).isOrdered()) {
stream = stream.sorted(adaptOrderComparator(matchingBeans));
}
return stream;
}
//如果依赖项的类型是数组,首先获取数组元素的类型,然后找到所有与数组元素类型匹配的 Bean。最后,将匹配到的 Bean 转化为数组,并进行排序(如果有序)。
else if (type.isArray()) {
// 得到数组元素的类型
Class<?> componentType = type.getComponentType();
ResolvableType resolvableType = descriptor.getResolvableType();
Class<?> resolvedArrayType = resolvableType.resolve(type);
if (resolvedArrayType != type) {
componentType = resolvableType.getComponentType().resolve();
}
if (componentType == null) {
return null;
}
// 根据数组元素类型找到所匹配的所有Bean
Map<String, Object> matchingBeans = findAutowireCandidates(beanName, componentType,
new MultiElementDescriptor(descriptor));
if (matchingBeans.isEmpty()) {
return null;
}
if (autowiredBeanNames != null) {
autowiredBeanNames.addAll(matchingBeans.keySet());
}
// 进行类型转化
TypeConverter converter = (typeConverter != null ? typeConverter : getTypeConverter());
Object result = converter.convertIfNecessary(matchingBeans.values(), resolvedArrayType);
if (result instanceof Object[]) {
Comparator<Object> comparator = adaptDependencyComparator(matchingBeans);
if (comparator != null) {
Arrays.sort((Object[]) result, comparator);
}
}
return result;
}
//如果依赖项的类型是集合(实现了 Collection 接口),则获取集合元素的类型,找到所有与集合元素类型匹配的 Bean。最后,将匹配到的 Bean 转化为集合,并进行排序(如果有序)。
else if (Collection.class.isAssignableFrom(type) && type.isInterface()) {
Class<?> elementType = descriptor.getResolvableType().asCollection().resolveGeneric();
if (elementType == null) {
return null;
}
Map<String, Object> matchingBeans = findAutowireCandidates(beanName, elementType,
new MultiElementDescriptor(descriptor));
if (matchingBeans.isEmpty()) {
return null;
}
if (autowiredBeanNames != null) {
autowiredBeanNames.addAll(matchingBeans.keySet());
}
TypeConverter converter = (typeConverter != null ? typeConverter : getTypeConverter());
Object result = converter.convertIfNecessary(matchingBeans.values(), type);
if (result instanceof List) {
if (((List<?>) result).size() > 1) {
Comparator<Object> comparator = adaptDependencyComparator(matchingBeans);
if (comparator != null) {
((List<?>) result).sort(comparator);
}
}
}
return result;
}
//如果依赖项的类型是 Map,则获取 Map 的键和值的类型,如果键的类型不是 String,返回 null。然后,找到所有与值的类型匹配的 Bean,最后返回匹配到的 Bean 的 Map。
else if (Map.class == type) {
ResolvableType mapType = descriptor.getResolvableType().asMap();
Class<?> keyType = mapType.resolveGeneric(0);
// 如果Map的key不是String
if (String.class != keyType) {
return null;
}
Class<?> valueType = mapType.resolveGeneric(1);
if (valueType == null) {
return null;
}
Map<String, Object> matchingBeans = findAutowireCandidates(beanName, valueType,
new MultiElementDescriptor(descriptor));
if (matchingBeans.isEmpty()) {
return null;
}
if (autowiredBeanNames != null) {
autowiredBeanNames.addAll(matchingBeans.keySet());
}
return matchingBeans;
}
//对于其他类型的依赖项,返回 null,表示当前方法无法处理。
else {
return null;
}
}
这段代码是 Spring 框架中用于解析多个匹配的 Bean 的方法,具体来说是对数组、集合(Collection)、Map、以及 Stream 类型的依赖项进行解析。我们可以发现 每一种类型都调用findAutowireCandidates函数来获得一个匹配bean的map集合
protected Map<String, Object> findAutowireCandidates(
@Nullable String beanName, Class<?> requiredType, DependencyDescriptor descriptor) {
// 从BeanFactory中找出和requiredType所匹配的beanName,仅仅是beanName,这些bean不一定经过了实例化,只有到最终确定某个Bean了,如果这个Bean还没有实例化才会真正进行实例化
String[] candidateNames = BeanFactoryUtils.beanNamesForTypeIncludingAncestors(
this, requiredType, true, descriptor.isEager());
Map<String, Object> result = CollectionUtils.newLinkedHashMap(candidateNames.length);
// 根据类型从resolvableDependencies中匹配Bean,resolvableDependencies中存放的是类型:Bean对象,比如BeanFactory.class:BeanFactory对象,在Spring启动时设置
for (Map.Entry<Class<?>, Object> classObjectEntry : this.resolvableDependencies.entrySet()) {
//获取class对象
Class<?> autowiringType = classObjectEntry.getKey();
//判断是否与当前所需要的class类型匹配
if (autowiringType.isAssignableFrom(requiredType)) {
Object autowiringValue = classObjectEntry.getValue();
autowiringValue = AutowireUtils.resolveAutowiringValue(autowiringValue, requiredType);
if (requiredType.isInstance(autowiringValue)) {
result.put(ObjectUtils.identityToString(autowiringValue), autowiringValue);
break;
}
}
}
for (String candidate : candidateNames) {
// 如果不是自己,则判断该candidate到底能不能用来进行自动注入
if (!isSelfReference(beanName, candidate) && isAutowireCandidate(candidate, descriptor)) {
addCandidateEntry(result, candidate, descriptor, requiredType);
}
}
// 为空要么是真的没有匹配的,要么是匹配的自己
if (result.isEmpty()) {
// 需要匹配的类型是不是Map、数组之类的
boolean multiple = indicatesMultipleBeans(requiredType);
// Consider fallback matches if the first pass failed to find anything...
DependencyDescriptor fallbackDescriptor = descriptor.forFallbackMatch();
for (String candidate : candidateNames) {
if (!isSelfReference(beanName, candidate) && isAutowireCandidate(candidate, fallbackDescriptor) &&
(!multiple || getAutowireCandidateResolver().hasQualifier(descriptor))) {
addCandidateEntry(result, candidate, descriptor, requiredType);
}
}
// 匹配的是自己,被自己添加到result中
if (result.isEmpty() && !multiple) {
// Consider self references as a final pass...
// but in the case of a dependency collection, not the very same bean itself.
for (String candidate : candidateNames) {
if (isSelfReference(beanName, candidate) &&
(!(descriptor instanceof MultiElementDescriptor) || !beanName.equals(candidate)) &&
isAutowireCandidate(candidate, fallbackDescriptor)) {
addCandidateEntry(result, candidate, descriptor, requiredType);
}
}
}
}
return result;
}
上面代码首先是获取指定类型所有bean的名字String[] candidateNames = BeanFactoryUtils.beanNamesForTypeIncludingAncestors(this, requiredType, true, descriptor.isEager());
public static String[] beanNamesForTypeIncludingAncestors(
ListableBeanFactory lbf, Class<?> type, boolean includeNonSingletons, boolean allowEagerInit) {
Assert.notNull(lbf, "ListableBeanFactory must not be null");
// 从本容器中找
String[] result = lbf.getBeanNamesForType(type, includeNonSingletons, allowEagerInit);
// 从父容器找并放入result
if (lbf instanceof HierarchicalBeanFactory) {
HierarchicalBeanFactory hbf = (HierarchicalBeanFactory) lbf;
if (hbf.getParentBeanFactory() instanceof ListableBeanFactory) {
String[] parentResult = beanNamesForTypeIncludingAncestors(
(ListableBeanFactory) hbf.getParentBeanFactory(), type, includeNonSingletons, allowEagerInit);
result = mergeNamesWithParent(result, parentResult, hbf);
}
}
return result;
}
上面代码的逻辑就是根据类型在本工厂和父工厂中找,如果都找到了然后合并两个结果并返回,那么bean 工厂是怎么根据类型来找名字的lbf.getBeanNamesForType
//includeNonSingletons表示是否包括原型bean
@Override
public String[] getBeanNamesForType(@Nullable Class<?> type, boolean includeNonSingletons, boolean allowEagerInit) {
// 如果没有冻结,就根据类型去BeanFactory找,如果冻结了,可能就跳过这个if然后去缓存中去拿了
if (!isConfigurationFrozen() || type == null || !allowEagerInit) {
return doGetBeanNamesForType(ResolvableType.forRawClass(type), includeNonSingletons, allowEagerInit);
}
// 把当前类型所匹配的beanName缓存起来(includeNonSingletons来判断具体保持到哪个集合)
Map<Class<?>, String[]> cache =
(includeNonSingletons ? this.allBeanNamesByType : this.singletonBeanNamesByType);
String[] resolvedBeanNames = cache.get(type);
if (resolvedBeanNames != null) {
return resolvedBeanNames;
}
resolvedBeanNames = doGetBeanNamesForType(ResolvableType.forRawClass(type), includeNonSingletons, true);
if (ClassUtils.isCacheSafe(type, getBeanClassLoader())) {
cache.put(type, resolvedBeanNames);
}
return resolvedBeanNames;
}
然后上面代码最终调用的是doGetBeanNamesForType来找的
private String[] doGetBeanNamesForType(ResolvableType type, boolean includeNonSingletons, boolean allowEagerInit) {
List<String> result = new ArrayList<>();
// Check all bean definitions.
// 遍历所有的BeanDefinitions的name
for (String beanName : this.beanDefinitionNames) {
// Only consider bean as eligible if the bean name is not defined as alias for some other bean.
if (!isAlias(beanName)) {
try {
//根据名字拿到对应的BeanDefinition
RootBeanDefinition mbd = getMergedLocalBeanDefinition(beanName);
// Only check bean definition if it is complete.
// 判断mbd允不允许获取对应类型
// 首先mdb不能是抽象的,然后allowEagerInit为true,则直接去推测mdb的类型,并进行匹配
// 如果allowEagerInit为false,那就继续判断,如果mdb还没有加载类并且是懒加载的并且不允许提前加载类,那mbd不能用来进行匹配(因为不允许提前加载类,只能在此mdb自己去创建bean对象时才能去创建类)
// 如果allowEagerInit为false,并且mbd已经加载类了,或者是非懒加载的,或者允许提前加载类,并且不用必须提前初始化才能获取类型,那么就可以去进行匹配了
// 这个条件有点复杂,但是如果只考虑大部分流程,则可以忽略这个判断,因为allowEagerInit传进来的基本上都是true
if (!mbd.isAbstract() && (allowEagerInit ||
(mbd.hasBeanClass() || !mbd.isLazyInit() || isAllowEagerClassLoading()) &&
!requiresEagerInitForType(mbd.getFactoryBeanName()))) {
boolean isFactoryBean = isFactoryBean(beanName, mbd);
BeanDefinitionHolder dbd = mbd.getDecoratedDefinition();
boolean matchFound = false;
boolean allowFactoryBeanInit = (allowEagerInit || containsSingleton(beanName));
boolean isNonLazyDecorated = (dbd != null && !mbd.isLazyInit());
// 当前BeanDefinition不是FactoryBean,就是普通Bean
if (!isFactoryBean) {
// 在筛选Bean时,如果仅仅只包括单例,但是beanName对应的又不是单例,则忽略
if (includeNonSingletons || isSingleton(beanName, mbd, dbd)) {
matchFound = isTypeMatch(beanName, type, allowFactoryBeanInit);
}
}
else {
if (includeNonSingletons || isNonLazyDecorated ||
(allowFactoryBeanInit && isSingleton(beanName, mbd, dbd))) {
matchFound = isTypeMatch(beanName, type, allowFactoryBeanInit);
}
if (!matchFound) {
// In case of FactoryBean, try to match FactoryBean instance itself next.
beanName = FACTORY_BEAN_PREFIX + beanName;
matchFound = isTypeMatch(beanName, type, allowFactoryBeanInit);
}
}
if (matchFound) {
result.add(beanName);
}
}
}
catch (CannotLoadBeanClassException | BeanDefinitionStoreException ex) {
if (allowEagerInit) {
throw ex;
}
// Probably a placeholder: let's ignore it for type matching purposes.
LogMessage message = (ex instanceof CannotLoadBeanClassException ?
LogMessage.format("Ignoring bean class loading failure for bean '%s'", beanName) :
LogMessage.format("Ignoring unresolvable metadata in bean definition '%s'", beanName));
logger.trace(message, ex);
// Register exception, in case the bean was accidentally unresolvable.
onSuppressedException(ex);
}
catch (NoSuchBeanDefinitionException ex) {
// Bean definition got removed while we were iterating -> ignore.
}
}
}
// Check manually registered singletons too.
for (String beanName : this.manualSingletonNames) {
try {
// In case of FactoryBean, match object created by FactoryBean.
if (isFactoryBean(beanName)) {
if ((includeNonSingletons || isSingleton(beanName)) && isTypeMatch(beanName, type)) {
result.add(beanName);
// Match found for this bean: do not match FactoryBean itself anymore.
continue;
}
// In case of FactoryBean, try to match FactoryBean itself next.
beanName = FACTORY_BEAN_PREFIX + beanName;
}
// Match raw bean instance (might be raw FactoryBean).
if (isTypeMatch(beanName, type)) {
result.add(beanName);
}
}
catch (NoSuchBeanDefinitionException ex) {
// Shouldn't happen - probably a result of circular reference resolution...
logger.trace(LogMessage.format(
"Failed to check manually registered singleton with name '%s'", beanName), ex);
}
}
return StringUtils.toStringArray(result);
}
上面代码核心逻辑就是遍历所有的beanname,然后调用isTypeMatch方法判断指定的bean是否和你需要的类型匹配。 isTypeMatch的主要思路是它首先从单例池中获取指定名称的bean比较类型,如果单例池中没有获取到,那就获取beanDefitniiton加载然后对比。然后返回匹配到的bean的beanname。回到findAutowireCandidates方法
protected Map<String, Object> findAutowireCandidates(
@Nullable String beanName, Class<?> requiredType, DependencyDescriptor descriptor) {
// 从BeanFactory中找出和requiredType所匹配的beanName,仅仅是beanName,这些bean不一定经过了实例化,只有到最终确定某个Bean了,如果这个Bean还没有实例化才会真正进行实例化
String[] candidateNames = BeanFactoryUtils.beanNamesForTypeIncludingAncestors(
this, requiredType, true, descriptor.isEager());
Map<String, Object> result = CollectionUtils.newLinkedHashMap(candidateNames.length);
// 根据类型从resolvableDependencies中匹配Bean,resolvableDependencies中存放的是类型:Bean对象,比如BeanFactory.class:BeanFactory对象,在Spring启动时设置
for (Map.Entry<Class<?>, Object> classObjectEntry : this.resolvableDependencies.entrySet()) {
//获取class对象
Class<?> autowiringType = classObjectEntry.getKey();
//判断是否与当前所需要的class类型匹配
if (autowiringType.isAssignableFrom(requiredType)) {
Object autowiringValue = classObjectEntry.getValue();
autowiringValue = AutowireUtils.resolveAutowiringValue(autowiringValue, requiredType);
if (requiredType.isInstance(autowiringValue)) {
result.put(ObjectUtils.identityToString(autowiringValue), autowiringValue);
break;
}
}
}
//遍历bean的名称
for (String candidate : candidateNames) {
// 如果不是自己,则判断该candidate到底能不能用来进行自动注入
if (!isSelfReference(beanName, candidate) && isAutowireCandidate(candidate, descriptor)) {
addCandidateEntry(result, candidate, descriptor, requiredType);
}
}
// 为空要么是真的没有匹配的,要么是匹配的自己v
if (result.isEmpty()) {
// 需要匹配的类型是不是Map、数组之类的
boolean multiple = indicatesMultipleBeans(requiredType);
// Consider fallback matches if the first pass failed to find anything...
DependencyDescriptor fallbackDescriptor = descriptor.forFallbackMatch();
for (String candidate : candidateNames) {
if (!isSelfReference(beanName, candidate) && isAutowireCandidate(candidate, fallbackDescriptor) &&
(!multiple || getAutowireCandidateResolver().hasQualifier(descriptor))) {
addCandidateEntry(result, candidate, descriptor, requiredType);
}
}
// 匹配的是自己,被自己添加到result中
if (result.isEmpty() && !multiple) {
// Consider self references as a final pass...
// but in the case of a dependency collection, not the very same bean itself.
for (String candidate : candidateNames) {
if (isSelfReference(beanName, candidate) &&
(!(descriptor instanceof MultiElementDescriptor) || !beanName.equals(candidate)) &&
isAutowireCandidate(candidate, fallbackDescriptor)) {
addCandidateEntry(result, candidate, descriptor, requiredType);
}
}
}
}
return result;
}
找到所有匹配的Beanname后,后面代码就会对beanname进行遍历,首先过滤掉自己作为匹配对象的bean,然后调用isAutowireCandidate判断其它匹配的bean是否可以进行依赖注入。例如下面bean利用autowireCandidate = false表示不能进行依赖注入的。
public class AppConfig {
@Bean(autowireCandidate = false)
public OrderService orderService(){
return new OrderService();
}
}
到这里数组、Map就解析完了,回到doResolveDependency方法继续执行后面逻辑。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!