Linux环境编程基础
静态库和动态库
静态库和动态库
在实际开发中,我们把通用的函数和类分文件编写,称之为库。在其它的程序中,可以使用库中的函数和类。
一般来说,通用的函数和类不提供源代码文件(安全性、商业机密),而是编译成二进制文件。
库的二进制文件有两种:静态库和动态库。
静态库和静态链接
程序在编译时会把库文件的二进制代码链接到目标程序中,这种方式称为静态链接。
如果多个程序中用到了同一静态库中的函数或类,就会存在多份拷贝。
- 静态库的链接是在编译时期完成的,执行的时候代码加载速度快。
- 目标程序的可执行文件比较大,浪费空间
- 程序的更新和发布不方便,如果某一个静态库更新了,所有使用它的程序都需要重新编译。
举个例子

public 实现通用函数和类,在demo01 中调用
1 一起编译

2 先静态库(二进制文件)

使用方式1(不推荐)
![]()
使用方式2 (L目录 l库名)

动态库和动态链接
程序在编译时不会把库文件的二进制代码链接到目标程序中,而是在运行时候才被载入。
如果多个进程中用到了同一动态库中的函数或类,那么在内存中只有一份,避免了空间浪费问题。
- 程序在运行的过程中,需要用到动态库的时候才把动态库的二进制代码载入内存。
- 可以实现进程之间的代码共享,因此动态库也称为共享库。
- 程序升级比较简单,不需要重新编译程序,只需要更新动态库就行了。
制作

使用
动态库 + 源代码 一起编译

规范方法

对比
如果动态库和静态库同时存在,编译器将优先使用动态库。
makefile
总体说明
tab键

1 使用 make 增量编译 tools 目录下


2 分别在tool 和 api make 然后一起编译(添加api到环境遍历)
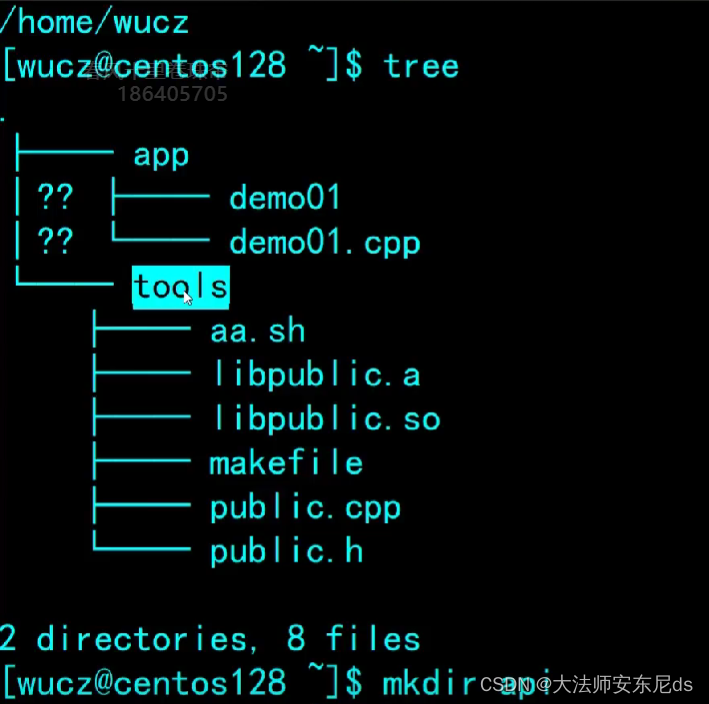
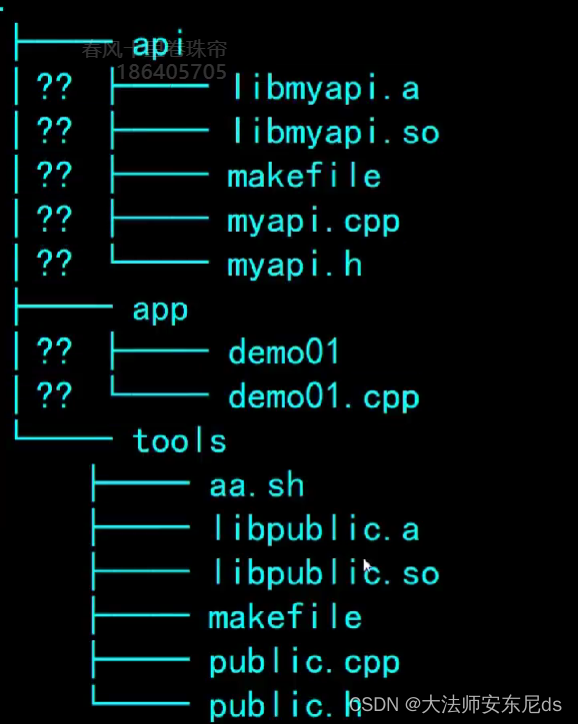

指定头文件路径

app 下 makefile 文件

如何优化?
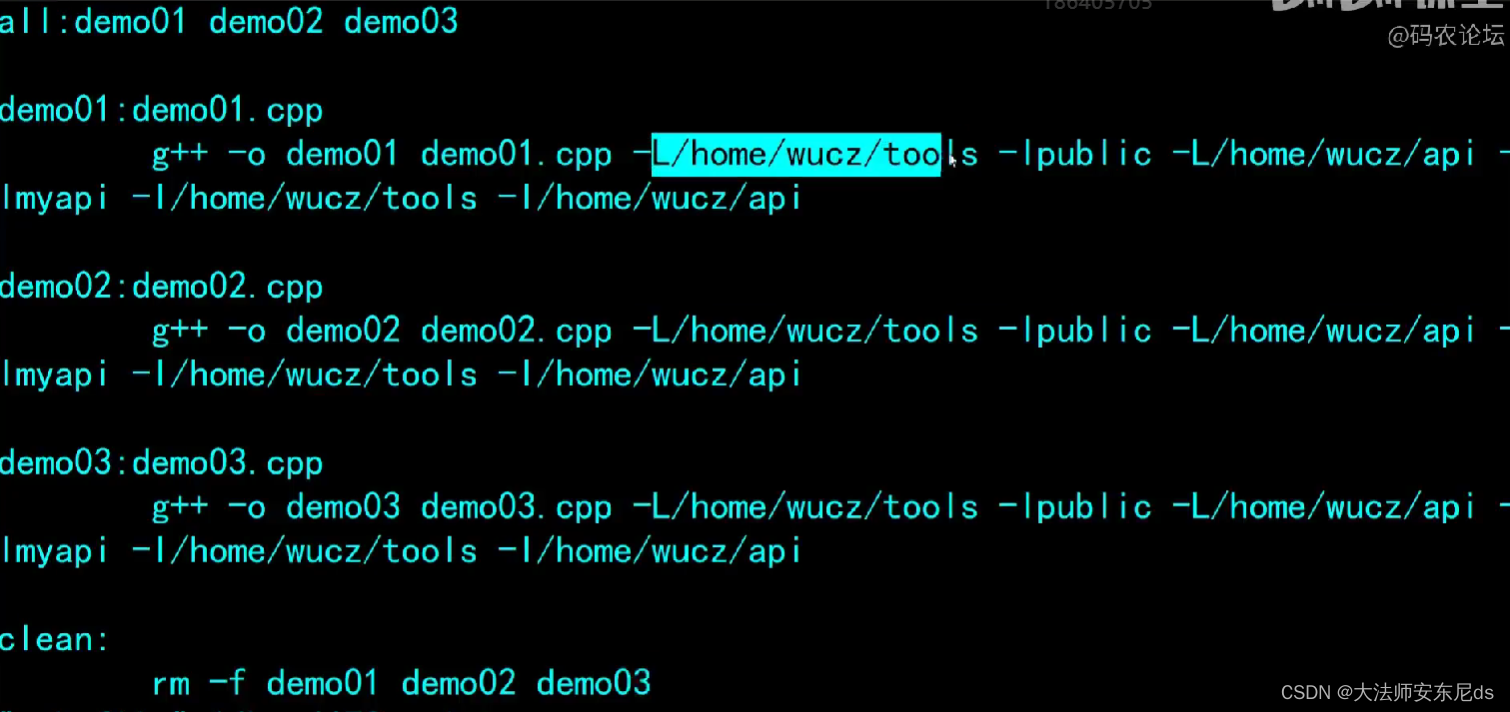
使用变量

main 函数
如何传入参数
#include <iostream>
using namespace std;
int main(int argc,char *argv[],char *envp[])
{
if (argc!=4)
{
cout << "表白神器程序的使用方法:./demo 追求者姓名 被追求者姓名 表白内容\n";
return -1;
}
cout << argv[1] << "开始向" << argv[2] << "表白。\n";
cout << argv[3] << endl;
cout << argv[1] << "表白完成。\n";
return 0;
cout << "一共有" << argc << "个参数。\n";
// 显示全部的参数。
for (int ii=0;ii<argc;ii++)
{
cout << "第" << ii << "个参数:" << argv[ii] << endl;
}
// 显示全部的环境变量。
for (int ii=0;envp[ii]!=0;ii++) // 环境变量数组最后一个元素是0。
{
cout << envp[ii] << endl;
}
// 设置环境变量AA。
setenv("AA","aaaa",0);
// 显示环境变量AA的值。
cout << "AA=" << getenv("AA") << endl;
return 0;
}
gdb 调试
运行到 line 17 停止
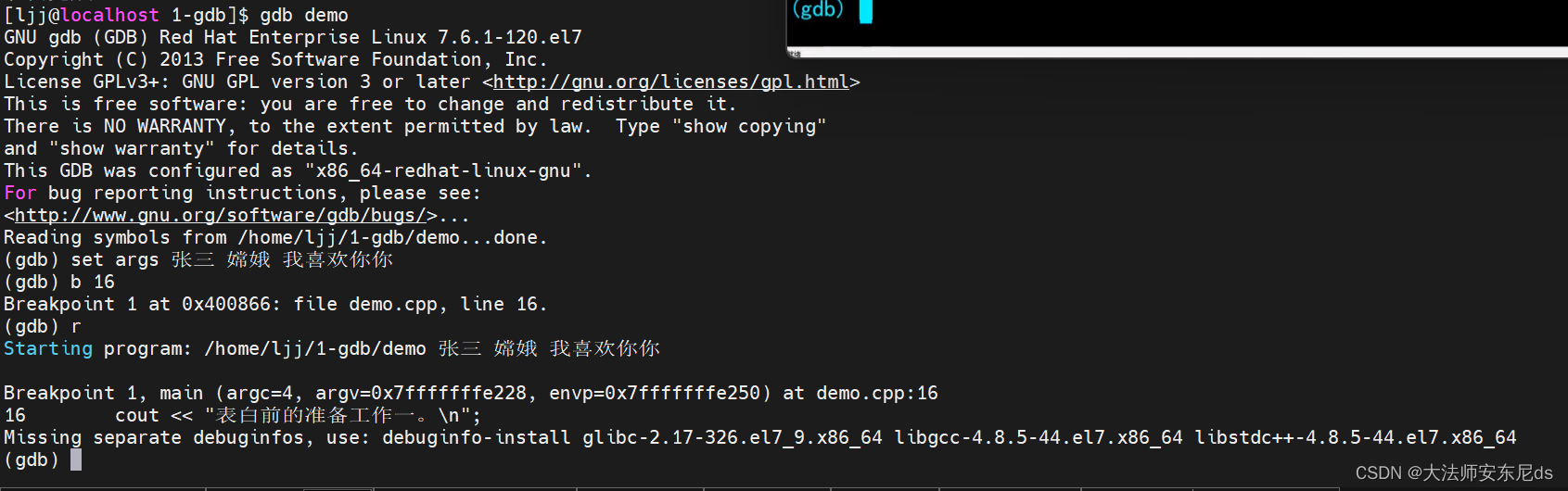
到第二个断点停止
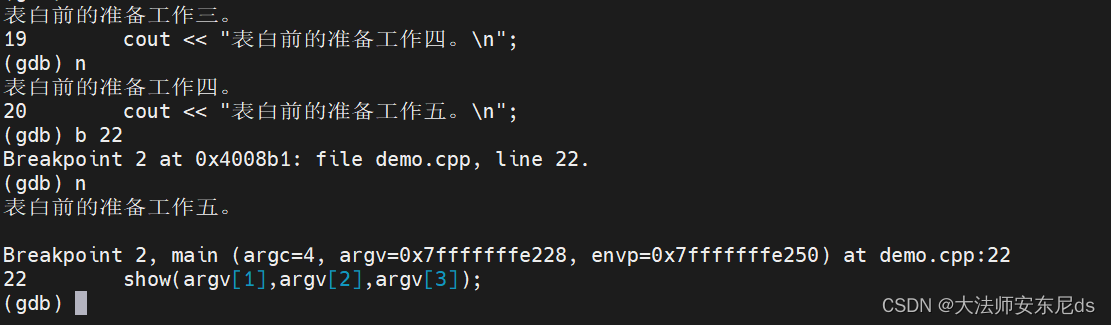
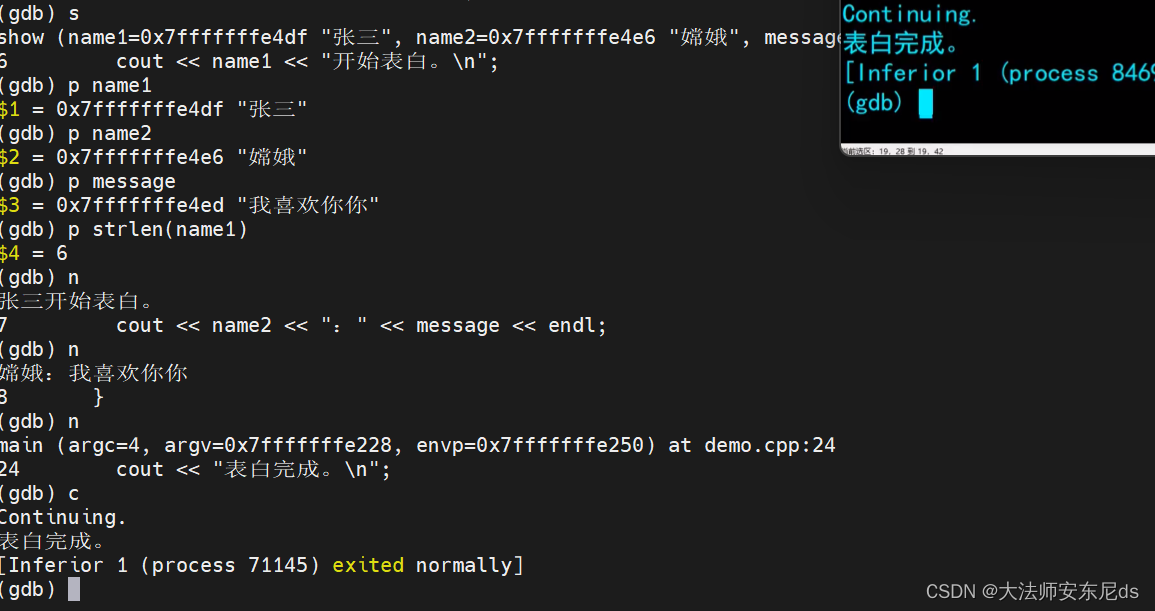
手动改 ii 的值

core dump
段错误

运行core文件,显示在第八行挂了

函数调用栈


调试运行程序
找到进程 进行调试

Linux 时间操作
创建进程
一、Linux的0、1和2号进程
整个Linux系统的进程形成了一颗树形结构。以下是一些重要的进程:
- 0号进程(系统进程): 所有进程的祖先,创建了1号和2号进程。
- 1号进程(systemd): 负责执行内核的初始化工作和进行系统配置。
- 2号进程(kthreadd): 负责所有内核线程的调度和管理。
可以使用 pstree -p 进程编号 命令查看进程树。
二、进程标识
每个进程都有一个唯一的非负整数表示的进程ID。重要的系统调用包括:
pid_t getpid(void);:获取当前进程的ID。pid_t getppid(void);:获取父进程的ID。
什么是系统调用?
系统调用是操作系统提供给用户程序的接口,用于访问操作系统的核心功能和资源。通过系统调用,用户程序可以请求执行特权操作,如文件操作、进程控制、内存管理、网络通信等。它是用户程序与操作系统内核之间的通信方式,允许应用程序利用操作系统提供的服务完成各种任务。
它会产生什么开销?程序员在编码时是否需要考虑它?
系统调用会引入一定的开销,因为它涉及从用户空间切换到内核空间,执行特权操作,并最终返回结果。这个过程需要上下文切换、参数传递、权限检查等步骤,因此相比于用户空间的普通函数调用,系统调用通常较为耗时。
程序员在编码时需要考虑系统调用的开销,尤其是在编写性能关键的应用程序时。以下是一些建议:
减少系统调用次数: 尽量减少不必要的系统调用,可以通过优化算法、缓存数据、合并文件操作等方式来减少系统调用的频率。
批量操作: 将多个操作合并为一个系统调用,而不是多次单独调用。例如,通过一次读取或写入大块数据,而不是多次读取或写入小块数据,以减少系统调用的开销。
异步和事件驱动: 使用异步操作或事件驱动模型,以充分利用系统资源,减少等待系统调用完成的时间。
合理使用缓存: 缓存可以减少对文件或数据的重复读取,从而减少对系统调用的依赖。
三、fork()函数
一个现有的进程可以调用fork()函数创建一个新的进程。pid_t fork(void);
由fork()创建的新进程被称为子进程。子进是父进程的副本,父进程和子进程都从调用fork()之后的代码开始执行。
fork()函数被调用一次,但返回两次。两次返回的区别是子进程的返回值是0,而父进程的返回值则是子进程的进程ID。所以可以根据返回值的不同,让两个进程执行不同的代码。
子进程获得了父进程数据空间、堆和栈的副本(注意:子进程拥有的是副本,不是和父进程共享)。
*多线程中共享数据空间、堆和栈。
*那变量地址为什么相同?

虚拟地址相同,物理地址不同
理论上来说,父进程和子进程的变量地址是相同的,但实际上,这个地址是虚拟地址,而不是物理地址。虚拟地址是由操作系统管理的,它对应着真正的物理地址。
在 fork() 的写时复制机制下,当父进程或子进程尝试修改这个共享的变量时,操作系统会复制相应的数据页,确保父子进程各自有一份独立的数据,从而避免相互干扰。
所以,虽然变量的虚拟地址看起来是相同的,但实际上它们对应的物理地址可能是不同的,因为操作系统在必要时会进行复制,保证了进程间的独立性。这种机制确保了在写入数据时才会发生实际的数据复制,避免了不必要的性能开销。
fork()之后,父进程和子进程的执行顺序是不确定的。
在 fork() 之后,父进程和子进程的执行顺序是不确定的,因为操作系统的调度机制决定了哪个进程首先被执行。这是由于父子进程是独立的进程,它们在执行时互相不受影响,操作系统可以在任何时刻切换执行权。
在多线程编程中,同样存在执行顺序不确定的问题。不同于进程的独立地址空间,线程共享同一地址空间,因此它们能够直接访问共享的数据。线程调度由操作系统内核负责,而线程之间的调度是非确定性的。
多线程编程中的线程调度可能受到很多因素的影响,比如操作系统的调度策略、线程的优先级等。因此,多线程程序中,各个线程的执行顺序是不确定的。
在多线程和多进程编程中,如果涉及到共享资源,需要使用同步机制来确保数据的一致性和正确性,比如互斥锁、信号量等。
#include <iostream>
#include <unistd.h>
using namespace std;
int main()
{
int bh = 8;
string message = "我是一只傻傻鸟。";
pid_t pid = fork();
if (pid > 0)
{
// 父进程将执行这段代码。
sleep(1);
cout << "父:pid=" << pid << endl;
cout << "父:亲爱的" << bh << "号:" << message << endl;
}
else
{
// 子进程将执行这段代码。
bh = 3; message = "你是一只傻傻鸟。";
cout << "子:pid=" << pid << endl;
cout << "子:亲爱的" << bh << "号:" << message << endl;
}
return 0;
}
四、fork()的两种用法
1)父子进程执行不同代码: 在网络服务程序中常见,父进程等待客户端连接请求,当请求到达时,父进程调用fork(),让子进程处理请求,而父进程继续等待下一个连接请求。
2)执行另一个程序: 子进程从fork()返回后调用exec。在Shell中常见。
exec函数族提供了一种在进程中调用程序(二进制文件或Shell脚本)的方法。
#include <iostream>
#include <unistd.h>
using namespace std;
int main()
{
if (fork() > 0)
{
// 父进程将执行这段代码。
while (true)
{
sleep(1);
cout << "父进程运行中...\n";
}
}
else
{
// 子进程将执行这段代码。
sleep(10);
cout << "子进程开始执行任务...\n";
execl("/bin/ls", "/bin/ls", "-lt", "/tmp", 0);
cout << "子进程执行任务结束,退出。\n";
}
return 0;
}
五、共享文件
父进程和子进程通过fork()共享打开的文件描述符,包括文件偏移量。如果同时写入同一描述符指向的文件,输出可能相互混合。
示例代码:
#include <iostream>
#include <fstream>
#include <unistd.h>
using namespace std;
int main()
{
ofstream fout;
fout.open("/tmp/tmp.txt");
fork();
for (int ii = 0; ii < 10000000; ii++)
{
fout << "进程" << getpid() << "西施" << ii << "极漂亮" << "\n";
}
fout.close();
return 0;
}
六、vfork()函数
vfork()函数用于创建一个新进程,该新进程的目的是执行exec一个新程序。与fork()不同,vfork()不复制父进程的地址空间。子进程会立即调用exec,因此不使用父进程的地址空间。
vfork()保证子进程先运行,在子进程调用exec或exit()之后,父进程才恢复运行。
僵尸进程
如果父进程比子进程先退出,子进程将被1号进程托管(这也是一种让程序在后台运行的方法)。
如果子进程比父进程先退出,而父进程没有处理子进程退出的信息,那么,子进程将成为僵尸进程。
僵尸进程有什么危害?内核为每个子进程保留了一个数据结构,包括进程编号、终止状态、使用CPU时间等。父进程如果处理了子进程退出的信息,内核就会释放这个数据结构,父进程如果没有处理子进程退出的信息,内核就不会释放这个数据结构,子进程的进程编号将一直被占用。系统可用的进程编号是有限的,如果产生了大量的僵尸进程,将因为没有可用的进程编号而导致系统不能产生新的进程。
如何避免?
1)子进程退出的时候,内核会向父进程发头SIGCHLD信号,如果父进程用signal(SIGCHLD,SIG_IGN)通知内核,表示自己对子进程的退出不感兴趣,那么子进程退出后会立即释放数据结构。
2)父进程通过wait()/waitpid()等函数等待子进程结束,在子进程退出之前,父进程将被阻塞待。
情况1
#include <iostream>
#include <unistd.h>
using namespace std;
int main()
{
if (fork()>0)
{ // 父进程将执行这段代码。
while (true)
{
sleep(20);
cout << "父进程运行中...\n";
return 0;
}
}
else
{ // 子进程将执行这段代码。
for (int ii = 0; ii < 100; ++ii) {
cout << "子进程继续运行中。" << endl;
sleep(1);
}
// sleep(10);
// cout << "子进程开始执行任务...\n";
// execl("/bin/ls","/bin/ls","-lt","/tmp",0);
// cout << "子进程执行任务结束,退出。\n";
}
}
20s后

情况2
获取子进程的退出信息
#include <iostream>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
using namespace std;
void func(int sig) // 子进程退出的信号处理函数。
{
int sts;
pid_t pid = wait(&sts);
cout << "已终止的子进程编号是:" << pid << endl;
if (WIFEXITED(sts)) { cout << "子进程是正常退出的,退出状态是:" << WEXITSTATUS(sts) << endl; }
else { cout << "子进程是异常退出的,终止它的信号是:" << WTERMSIG(sts) << endl; }
}
int main()
{
signal(SIGCHLD,func); // 捕获子进程退出的信号。
if (fork() > 0)
{ // 父进程的流程。
while (true)
{
cout << "父进程忙着执行任务。\n";
sleep(1);
}
}
else
{ // 子进程的流程。
sleep(5);
// int *p=0; *p=10;
exit(0);
}
}产生内存泄露的情况


#include <iostream>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
using namespace std;
void func(int sig) // 子进程退出的信号处理函数。
{
int sts;
pid_t pid = wait(&sts); // 调用子进程退出的信息
cout << "已终止的子进程编号是:" << pid << endl;
if (WIFEXITED(sts)) { cout << "子进程是正常退出的,退出状态是:" << WEXITSTATUS(sts) << endl; }
else { cout << "子进程是异常退出的,终止它的信号是:" << WTERMSIG(sts) << endl; }
}
int main()
{
signal(SIGCHLD,func); // 捕获子进程退出的信号。
if (fork() > 0)
{ // 父进程的流程。
while (true)
{
cout << "父进程忙着执行任务。\n";
sleep(1);
}
}
else
{ // 子进程的流程。
//sleep(5);
int *p=0; *p=10;
exit(0);
}
}多进程和信号
Linux操作系统提供了kill和killall命令向进程发送信号,在程序中,可以用kill()函数向其它进程发送信号。
函数声明:
int kill(pid_t pid, int sig);
kill()函数将参数sig指定的信号给参数pid?指定的进程。
参数pid?有几种情况:
1)pid>0 将信号传给进程号为pid 的进程。
2)pid=0 将信号传给和当前进程相同进程组的所有进程,常用于父进程给子进程发送信号,注意,发送信号者进程也会收到自己发出的信号。
3)pid=-1 将信号广播传送给系统内所有的进程,例如系统关机时,会向所有的登录窗口广播关机信息。
sig:准备发送的信号代码,假如其值为0则没有任何信号送出,但是系统会执行错误检查,通常会利用sig值为零来检验某个进程是否仍在运行。
返回值说明: 成功执行时,返回0;失败返回-1,errno被设置。
在多进程的服务程序中,如果子进程收到退出信号,子进程自行退出,
如果父进程收到退出信号,则应该先向全部的子进程发送退出信号,然后自己再退出。
- 在循环中使用
signal(SIGTERM, FathEXIT);和signal(SIGINT, FathEXIT);设置了父进程的信号处理函数。这表示当父进程接收到SIGTERM或SIGINT信号时,将执行FathEXIT函数。 - 在父进程和子进程中,使用
signal(SIGTERM, ChldEXIT);设置了子进程的信号处理函数。这表示当子进程接收到SIGTERM信号时,将执行ChldEXIT函数。 - 在子进程中,使用
signal(SIGINT, SIG_IGN);忽略了SIGINT信号,即子进程不处理SIGINT信号。 - 通过
kill(0, SIGTERM);向全部子进程发送SIGTERM信号,通知它们退出。
#include <iostream>
#include <unistd.h>
#include <signal.h>
using namespace std;
void FathEXIT(int sig); // 父进程的信号处理函数。
void ChldEXIT(int sig); // 子进程的信号处理函数。
int main()
{
// 忽略全部的信号,不希望被打扰。
for (int ii=1;ii<=64;ii++) signal(ii,SIG_IGN);
// 设置信号,在shell状态下可用 "kill 进程号" 或 "Ctrl+c" 正常终止些进程
// 但请不要用 "kill -9 +进程号" 强行终止
// SIGTERM 15 SIGINT 2
signal(SIGTERM,FathEXIT); signal(SIGINT,FathEXIT);
while (true)
{
// 每五秒创建一个子进程
if (fork()>0) // 父进程的流程。
{
sleep(5); continue;
}
else // 子进程的流程。
{
// 子进程需要重新设置信号。
signal(SIGTERM,ChldEXIT); // 子进程的退出函数与父进程不一样。
signal(SIGINT ,SIG_IGN); // 子进程不需要捕获SIGINT信号。
while (true)
{
cout << "子进程" << getpid() << "正在运行中。\n"; sleep(3); continue;
}
}
}
}
// 父进程的信号处理函数。
void FathEXIT(int sig)
{
// 以下代码是为了防止信号处理函数在执行的过程中再次被信号中断。
signal(SIGINT,SIG_IGN); signal(SIGTERM,SIG_IGN);
cout << "父进程退出,sig=" << sig << endl;
// 向全部的子进程发送15的信号,通知它们退出。
// 可能会发给自己
kill(0,SIGTERM);
// 在这里增加释放资源的代码(全局的资源)。
exit(0);
}
// 子进程的信号处理函数。
void ChldEXIT(int sig)
{
// 以下代码是为了防止信号处理函数在执行的过程中再次被信号中断。
signal(SIGINT,SIG_IGN); signal(SIGTERM,SIG_IGN);
cout << "子进程" << getpid() << "退出,sig=" << sig << endl;
// 在这里增加释放资源的代码(只释放子进程的资源)。
exit(0);
}共享内存
常用操作
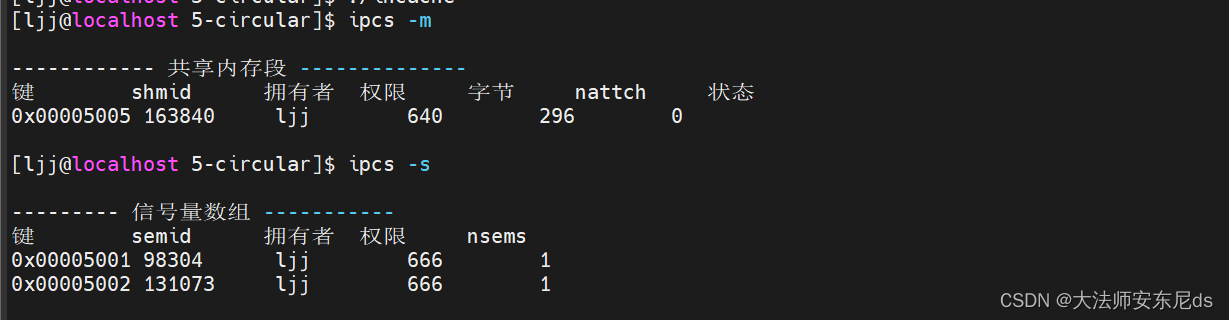
在 Linux 中,共享内存相关的操作通常通过 System V IPC(Inter-Process Communication,进程间通信)机制实现。以下是一些与共享内存相关的常用命令:
-
ipcs命令:
ipcs -m:显示当前系统上的共享内存信息。ipcs -ma:以更详细的格式显示共享内存信息。
-
ipcrm命令:
ipcrm -m <shmid>:删除指定的共享内存段。
多线程共享进程的地址空间,如果多个线程需要访问同一块内存,用全局变量就可以了。
在多进程中,每个进程的地址空间是独立的,不共享的,如果多个进程需要访问同一块内存,不能用全局变量,只能用共享内存。
共享内存(Shared Memory)允许多个进程(不要求进程之间有血缘关系)访问同一块内存空间,是多个进程之间共享和传递数据最高效的方式。进程可以将共享内存连接到它们自己的地址空间中,如果某个进程修改了共享内存中的数据,其它的进程读到的数据也会改变。
共享内存没有提供锁机制,也就是说,在某一个进程对共享内存进行读/写的时候,不会阻止其它进程对它的读/写。如果要对共享内存的读/写加锁,可以使用信号量。
Linux中提供了一组函数用于操作共享内存。
shmget函数
该函数用于创建/获取共享内存。
int?shmget(key_t key, size_t size, int shmflg);
key ? 共享内存的键值,是一个整数(typedef unsigned int key_t),一般采用十六进制,例如0x5005,不同共享内存的key不能相同。
size? 共享内存的大小,以字节为单位。
shmflg 共享内存的访问权限,与文件的权限一样,例如0666|IPC_CREAT,0666表示全部用户对它可读写,IPC_CREAT表示如果共享内存不存在,就创建它。
返回值:成功返回共享内存的id(一个非负的整数),失败返回-1(系统内存不足、没有权限)
用ipcs -m可以查看系统的共享内存,包括:键值(key),共享内存id(shmid),拥有者(owner),权限(perms),大小(bytes)。

shmat函数
该函数用于把共享内存连接到当前进程的地址空间。
void *shmat(int shmid, const void *shmaddr, int shmflg);
shmid 由shmget()函数返回的共享内存标识。
shmaddr? 指定共享内存连接到当前进程中的地址位置,通常填0,表示让系统来选择共享内存的地址。
shmflg 标志位,通常填0。
调用成功时返回共享内存起始地址,失败返回(void*)-1。
shmdt函数
该函数用于将共享内存从当前进程中分离,相当于shmat()函数的反操作。
int?shmdt(const void *shmaddr);
shmaddr shmat()函数返回的地址。
调用成功时返回0,失败时返回-1。
shmctl函数
该函数用于操作共享内存,最常用的操作是删除共享内存。
int?shmctl(int shmid, int command, struct shmid_ds *buf);
shmid shmget()函数返回的共享内存id。
command 操作共享内存的指令,如果要删除共享内存,填IPC_RMID。
buf 操作共享内存的数据结构的地址,如果要删除共享内存,填0。
调用成功时返回0,失败时返回-1。
注意,用root创建的共享内存,不管创建的权限是什么,普通用户无法删除。

删除
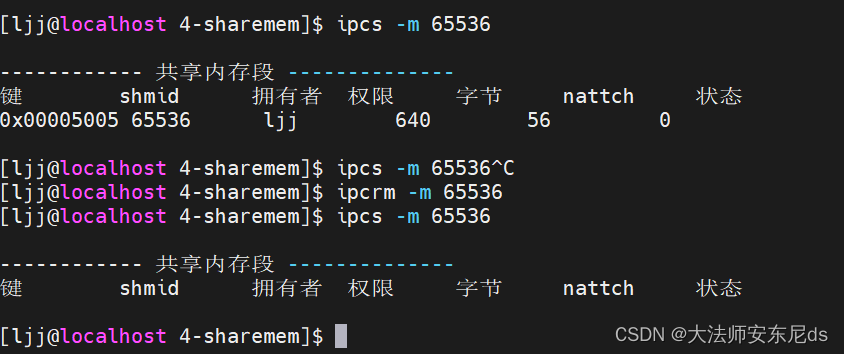
不能用容器!因为栈堆区内存不属于共享内存!
生产消费者模型
循环队列和信号量
生产者程序
// 多进程的生产消费者模型的生产者程序
#include "_public.h"
int main()
{
struct stgirl // 循环队列的数据元素是超女结构体。
{
int no;
char name[51];
};
using ElemType=stgirl;
// 初始化共享内存。
int shmid=shmget(0x5005, sizeof(squeue<ElemType,5>), 0640|IPC_CREAT);
if ( shmid ==-1 )
{
cout << "shmget(0x5005) failed.\n"; return -1;
}
// 把共享内存连接到当前进程的地址空间。
squeue<ElemType,5> *QQ=(squeue<ElemType,5> *)shmat(shmid,0,0);
if ( QQ==(void *)-1 )
{
cout << "shmat() failed\n"; return -1;
}
QQ->init(); // 初始化循环队列。
ElemType ee; // 创建一个数据元素。
csemp mutex; mutex.init(0x5001); // 用于给共享内存加锁。
csemp cond; cond.init(0x5002,0,0); // 信号量的值用于表示队列中数据元素的个数。
mutex.wait(); // 加锁。
// 生产3个数据。
ee.no=3; strcpy(ee.name,"西施"); QQ->push(ee);
ee.no=7; strcpy(ee.name,"冰冰"); QQ->push(ee);
ee.no=8; strcpy(ee.name,"幂幂"); QQ->push(ee);
mutex.post(); // 解锁。
cond.post(3); // 实参是3,表示生产了3个数据。
shmdt(QQ); // 把共享内存从当前进程中分离。
}?消费者程序

// 多进程的生产消费者模型的消费者程序
#include "_public.h"
int main()
{
struct stgirl // 循环队列的数据元素是超女结构体。
{
int no;
char name[51];
};
using ElemType=stgirl;
// 初始化共享内存。
int shmid=shmget(0x5005, sizeof(squeue<ElemType,5>), 0640|IPC_CREAT);
if ( shmid ==-1 )
{
cout << "shmget(0x5005) failed.\n"; return -1;
}
// 把共享内存连接到当前进程的地址空间。
squeue<ElemType,5> *QQ=(squeue<ElemType,5> *)shmat(shmid,0,0);
if ( QQ==(void *)-1 )
{
cout << "shmat() failed\n"; return -1;
}
QQ->init(); // 初始化循环队列。
ElemType ee; // 创建一个数据元素。
csemp mutex; mutex.init(0x5001); // 用于给共享内存加锁。
csemp cond; cond.init(0x5002,0,0); // 信号量的值用于表示队列中数据元素的个数。
while (true)
{
mutex.wait(); // 加锁。
while (QQ->empty()) // 如果队列空,进入循环,否则直接处理数据。必须用循环,不能用if
{
mutex.post(); // 解锁。
cond.wait(); // 等待生产者的唤醒信号。
mutex.wait(); // 加锁。
}
// 数据元素出队。
ee = QQ->front(); QQ->pop();
mutex.post(); // 解锁。
// 处理出队的数据(把数据消费掉)。
cout << "no=" << ee.no << ",name=" << ee.name << endl;
usleep(100); // 假设处理数据需要时间,方便演示。
}
shmdt(QQ);
}循环队列
_public.h
#ifndef __PUBLIC_HH
#define __PUBLIC_HH 1
#include <iostream>
#include <cstdio>
#include <cstdlib>
#include <cstring>
#include <unistd.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <sys/types.h>
#include <sys/sem.h>
using namespace std;
// 循环队列。
template <class TT, int MaxLength>
class squeue
{
private:
bool m_inited; // 队列被初始化标志,true-已初始化;false-未初始化。
TT m_data[MaxLength]; // 用数组存储循环队列中的元素。
int m_head; // 队列的头指针。
int m_tail; // 队列的尾指针,指向队尾元素。
int m_length; // 队列的实际长度。
squeue(const squeue &) = delete; // 禁用拷贝构造函数。
squeue &operator=(const squeue &) = delete; // 禁用赋值函数。
public:
squeue() { init(); } // 构造函数。
// 循环队列的初始化操作。
// 注意:如果用于共享内存的队列,不会调用构造函数,必须调用此函数初始化。
void init()
{
if (m_inited!=true) // 循环队列的初始化只能执行一次。
{
m_head=0; // 头指针。指向第一个元素
m_tail=MaxLength-1; // 为了方便写代码,初始化时,尾指针指向队列的最后一个位置。
m_length=0; // 队列的实际长度。
memset(m_data,0,sizeof(m_data)); // 数组元素清零。
m_inited=true;
}
}
// 元素入队,返回值:false-失败;true-成功。
bool push(const TT &ee)
{
if (full() == true)
{
cout << "循环队列已满,入队失败。\n"; return false;
}
// 先移动队尾指针,然后再拷贝数据。
m_tail=(m_tail+1)%MaxLength; // 队尾指针后移。
m_data[m_tail]=ee;
m_length++;
return true;
}
// 求循环队列的长度,返回值:>=0-队列中元素的个数。
int size()
{
return m_length;
}
// 判断循环队列是否为空,返回值:true-空,false-非空。
bool empty()
{
if (m_length == 0) return true;
return false;
}
// 判断循环队列是否已满,返回值:true-已满,false-未满。
bool full()
{
if (m_length == MaxLength) return true;
return false;
}
// 查看队头元素的值,元素不出队。
TT& front()
{
return m_data[m_head];
}
// 元素出队,返回值:false-失败;true-成功。
bool pop()
{
if (empty() == true) return false;
m_head=(m_head+1)%MaxLength; // 队列头指针后移。
m_length--;
return true;
}
// 显示循环队列中全部的元素。
// 这是一个临时的用于调试的函数,队列中元素的数据类型支持cout输出才可用。
void printqueue()
{
for (int ii = 0; ii < size(); ii++)
{
cout << "m_data[" << (m_head+ii)%MaxLength << "],value=" \
<< m_data[(m_head+ii)%MaxLength] << endl;
}
}
};
// 信号量。
class csemp
{
private:
union semun // 用于信号量操作的共同体。
{
int val;
struct semid_ds *buf;
unsigned short *arry;
};
int m_semid; // 信号量id(描述符)。
// 如果把sem_flg设置为SEM_UNDO,操作系统将跟踪进程对信号量的修改情况,
// 在全部修改过信号量的进程(正常或异常)终止后,操作系统将把信号量恢复为初始值。
// 如果信号量用于互斥锁,设置为SEM_UNDO。
// 如果信号量用于生产消费者模型,设置为0。
short m_sem_flg;
csemp(const csemp &) = delete; // 禁用拷贝构造函数。
csemp &operator=(const csemp &) = delete; // 禁用赋值函数。
public:
csemp():m_semid(-1){}
// 如果信号量已存在,获取信号量;如果信号量不存在,则创建它并初始化为value。
// 如果用于互斥锁,value填1,sem_flg填SEM_UNDO。
// 如果用于生产消费者模型,value填0,sem_flg填0。
bool init(key_t key,unsigned short value=1,short sem_flg=SEM_UNDO);
bool wait(short value=-1);// 信号量的P操作,如果信号量的值是0,将阻塞等待,直到信号量的值大于0。
bool post(short value=1); // 信号量的V操作。
int getvalue(); // 获取信号量的值,成功返回信号量的值,失败返回-1。
bool destroy(); // 销毁信号量。
~csemp();
};
#endif_public.cpp
#include "_public.h"
// 如果信号量已存在,获取信号量;如果信号量不存在,则创建它并初始化为value。
// 如果用于互斥锁,value填1,sem_flg填SEM_UNDO。
// 如果用于生产消费者模型,value填0,sem_flg填0。
bool csemp::init(key_t key,unsigned short value,short sem_flg)
{
if (m_semid!=-1) return false; // 如果已经初始化了,不必再次初始化。
m_sem_flg=sem_flg;
// 信号量的初始化不能直接用semget(key,1,0666|IPC_CREAT)
// 因为信号量创建后,初始值是0,如果用于互斥锁,需要把它的初始值设置为1,
// 而获取信号量则不需要设置初始值,所以,创建信号量和获取信号量的流程不同。
// 信号量的初始化分三个步骤:
// 1)获取信号量,如果成功,函数返回。
// 2)如果失败,则创建信号量。
// 3) 设置信号量的初始值。
// 获取信号量。
if ( (m_semid=semget(key,1,0666)) == -1)
{
// 如果信号量不存在,创建它。
if (errno==ENOENT)
{
// 用IPC_EXCL标志确保只有一个进程创建并初始化信号量,其它进程只能获取。
if ( (m_semid=semget(key,1,0666|IPC_CREAT|IPC_EXCL)) == -1)
{
if (errno==EEXIST) // 如果错误代码是信号量已存在,则再次获取信号量。
{
if ( (m_semid=semget(key,1,0666)) == -1)
{
perror("init 1 semget()"); return false;
}
return true;
}
else // 如果是其它错误,返回失败。
{
perror("init 2 semget()"); return false;
}
}
// 信号量创建成功后,还需要把它初始化成value。
union semun sem_union;
sem_union.val = value; // 设置信号量的初始值。
if (semctl(m_semid,0,SETVAL,sem_union) < 0)
{
perror("init semctl()"); return false;
}
}
else
{ perror("init 3 semget()"); return false; }
}
return true;
}
// 信号量的P操作(把信号量的值减value),如果信号量的值是0,将阻塞等待,直到信号量的值大于0。
bool csemp::wait(short value)
{
if (m_semid==-1) return false;
struct sembuf sem_b;
sem_b.sem_num = 0; // 信号量编号,0代表第一个信号量。
sem_b.sem_op = value; // P操作的value必须小于0。
sem_b.sem_flg = m_sem_flg;
if (semop(m_semid,&sem_b,1) == -1) { perror("p semop()"); return false; }
return true;
}
// 信号量的V操作(把信号量的值减value)。
bool csemp::post(short value)
{
if (m_semid==-1) return false;
struct sembuf sem_b;
sem_b.sem_num = 0; // 信号量编号,0代表第一个信号量。
sem_b.sem_op = value; // V操作的value必须大于0。
sem_b.sem_flg = m_sem_flg;
if (semop(m_semid,&sem_b,1) == -1) { perror("V semop()"); return false; }
return true;
}
// 获取信号量的值,成功返回信号量的值,失败返回-1。
int csemp::getvalue()
{
return semctl(m_semid,0,GETVAL);
}
// 销毁信号量。
bool csemp::destroy()
{
if (m_semid==-1) return false;
if (semctl(m_semid,0,IPC_RMID) == -1) { perror("destroy semctl()"); return false; }
return true;
}
csemp::~csemp()
{
}demo2.cpp
// demo2.cpp,本程序演示基于共享内存的循环队列。
#include "_public.h"
int main()
{
using ElemType=int;
// 初始化共享内存。
int shmid=shmget(0x5005, sizeof(squeue<ElemType,5>), 0640|IPC_CREAT);
if ( shmid ==-1 )
{
cout << "shmget(0x5005) failed.\n"; return -1;
}
// 把共享内存连接到当前进程的地址空间。
// 模板类指针指向共享内存的首地址。不调用构造函数。
squeue<ElemType,5> *QQ=(squeue<ElemType,5> *)shmat(shmid,0,0);
if ( QQ==(void *)-1 )
{
cout << "shmat() failed\n"; return -1;
}
QQ->init(); // 初始化循环队列。
ElemType ee; // 创建一个数据元素。
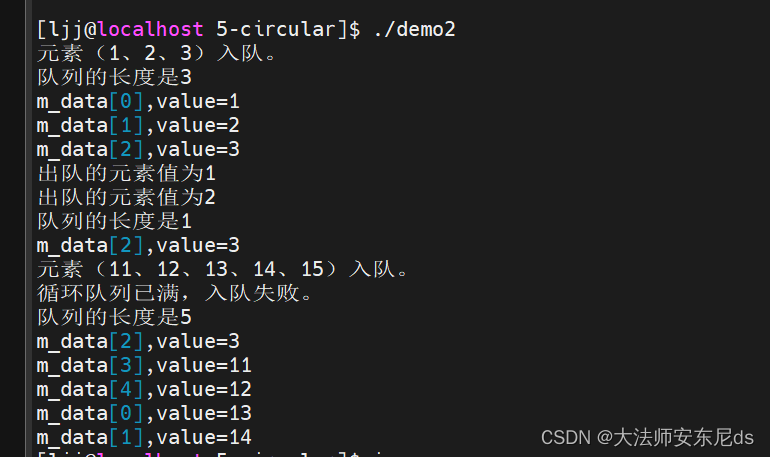
cout << "元素(1、2、3)入队。\n";
ee=1; QQ->push(ee);
ee=2; QQ->push(ee);
ee=3; QQ->push(ee);
cout << "队列的长度是" << QQ->size() << endl;
QQ->printqueue();
ee=QQ->front(); QQ->pop(); cout << "出队的元素值为" << ee << endl;
ee=QQ->front(); QQ->pop(); cout << "出队的元素值为" << ee << endl;
cout << "队列的长度是" << QQ->size() << endl;
QQ->printqueue();
cout << "元素(11、12、13、14、15)入队。\n";
ee=11; QQ->push(ee);
ee=12; QQ->push(ee);
ee=13; QQ->push(ee);
ee=14; QQ->push(ee);
ee=15; QQ->push(ee);
cout << "队列的长度是" << QQ->size() << endl;
QQ->printqueue();
shmdt(QQ); // 把共享内存从当前进程中分离。
}第一次运行:共享内存为空
第二次运行
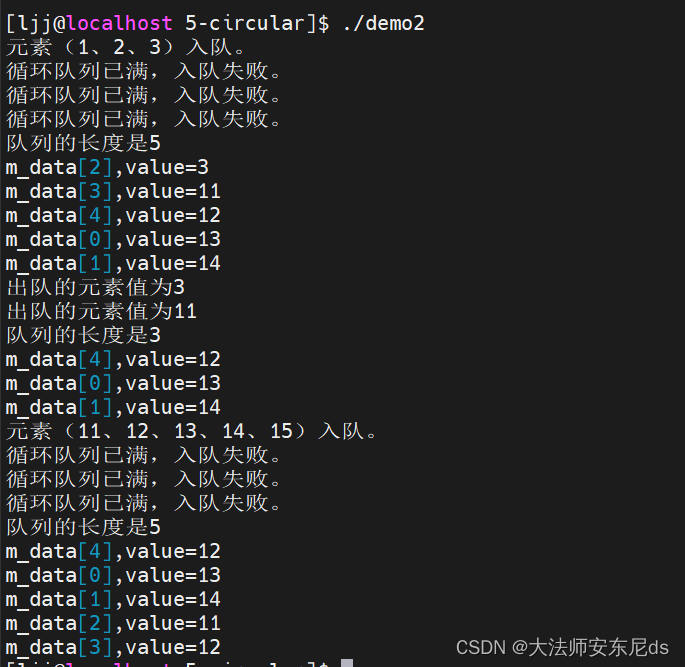
没有锁机制,会存在竞争关系
demo3.cpp 用信号量给共享内存加锁
// demo3.cpp,本程序演示用信号量给共享内存加锁。
#include "_public.h"
struct stgirl // 超女结构体。
{
int no; // 编号。
char name[51]; // 姓名,注意,不能用string。
};
int main(int argc,char *argv[])
{
if (argc!=3) { cout << "Using:./demo no name\n"; return -1; }
// 第1步:创建/获取共享内存,键值key为0x5005,也可以用其它的值。
int shmid=shmget(0x5005, sizeof(stgirl), 0640|IPC_CREAT);
if ( shmid ==-1 )
{
cout << "shmget(0x5005) failed.\n"; return -1;
}
cout << "shmid=" << shmid << endl;
// 第2步:把共享内存连接到当前进程的地址空间。
stgirl *ptr=(stgirl *)shmat(shmid,0,0);
if ( ptr==(void *)-1 )
{
cout << "shmat() failed\n"; return -1;
}
// 创建、初始化二元信号量。
csemp mutex;
if (mutex.init(0x5005)==false)
{
cout << "mutex.init(0x5005) failed.\n"; return -1;
}
cout << "申请加锁...\n";
mutex.wait(); // 申请加锁。
cout << "申请加锁成功。\n";
// 第3步:使用共享内存,对共享内存进行读/写。
cout << "原值:no=" << ptr->no << ",name=" << ptr->name << endl; // 显示共享内存中的原值。
ptr->no=atoi(argv[1]); // 对超女结构体的no成员赋值。
strcpy(ptr->name,argv[2]); // 对超女结构体的name成员赋值。
cout << "新值:no=" << ptr->no << ",name=" << ptr->name << endl; // 显示共享内存中的当前值。
sleep(10);
mutex.post(); // 解锁。
cout << "解锁。\n";
// 查看信号量 :ipcs -s // 删除信号量 :ipcrm sem 信号量id
// 查看共享内存:ipcs -m // 删除共享内存:ipcrm -m 共享内存id
// 第4步:把共享内存从当前进程中分离。
shmdt(ptr);
// 第5步:删除共享内存。
//if (shmctl(shmid,IPC_RMID,0)==-1)
//{
// cout << "shmctl failed\n"; return -1;
//}
}本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!