ElasticSearch
全文搜索、结构化搜索、分析以及将这三者混合使用
- 全文检索:
支持模糊查询全文,速度快,而MySQL也能模糊查询,但此时的 %content%不走索引;
基本概念
与MySQL对比:
| ElasticSearch | MySQL数据库 |
|---|---|
索引(indices) index | 数据库 |
类型(type) 已废除一个索引包含多个类型 | Table 数据表 |
| 文档(Document) | Row 行 |
| 字段(Field) | Column 列 |
| Mapping | Schema |
| DSL (API) | SQL |
- 索引类似于数据库,包括多个文档或类型,
- 类型:索引中的逻辑分类,可定义自己的映射和设置。
- 文档:类似于行,被查询搜索的对象。
- 映射:定义文档的字段(field)及数据类型,类似于表结构的定义。
- 字段:文档中的属性;(键值对)包括 文本、数字、日期。类似于列。
- 映射:定义文档的字段(field)及数据类型,类似于表结构的定义。
倒排索引:
Elasticsearch 底层数据结构 - TechLee - 博客园
将文章分词,统计不同词汇 的出现次数及对应的位置:倒排索引。
- 即根据 分词找到对应的记录(位置、次数)
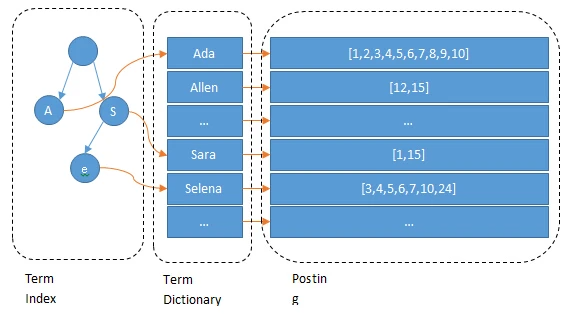
常见名词:
Term Dictionary词字典- 通常 **词条(Term) **的数量巨大,故对词条进行排序,之后使用二分查询。快速查找
Term - 一般不会存于内存中。(太多了)
Term Index部分词的前缀。 由 byte数组组成。(一般是字母或其他字符)- 目的:快速找到
Term Dictionary的大致位置,以提高对词条的查询效率 - 使用
FST结构存储于内存中,减少容量大小,查询速度快 PostingListint数组。存储符合 词条Term的文档id- 优化:使用
FOR编码对其压缩,以保证查询效率的同时节约磁盘空间。 - 通常情况下,需要对文档ID进行
并集、交集操作(多条件查询时),PostingList使用Roaring Bitmaps操作并交集,可以节省空间并快速计算并交集。Roaring Bitmaps详见:Elasticsearch 底层数据结构 - TechLee - 博客园 Roaring bitmaps 部分
什么是 Elasticsearch?一篇搞懂-腾讯云开发者社区-腾讯云
FST结构
ElasticSearch : FST 数据结构 - 掘金
Elasticsearch中的FST(Finite State Transducer)是一种有限状态转换器,用于高效地存储和检索大量的字符串数据。FST是一种基于有向图的数据结构,可实现高效的前缀匹配、模糊搜索和自动完成等功能。
- 在
Elasticsearch中被广泛应用于搜索引擎的内部工作机制中,特别是在倒排索引(Inverted Index)的构建和词条(Term)的检索过程中。倒排索引是一种将文档中的词条映射到文档ID的数据结构,而FST则可以用于快速检索和匹配这些词条。 - 主要优势: 高效性和紧凑性。它使用了一种特殊的压缩算法,能够以非常紧凑的方式存储大量的字符串数据,并支持快速的前缀匹配和模糊搜索。这使得
Elasticsearch能够在大规模数据集上快速地进行搜索和匹配操作。 - 其他领域: 比如自然语言处理、数据压缩和字典匹配等。它的高效性和紧凑性使得它成为许多字符串处理任务的理想选择。
FOR编码
Elasticsearch 底层数据结构 - TechLee - 博客园 的FOR模块
在倒排索引中,posting list用于存储每个词项出现的文档ID列表。通常情况下,posting list中的文档ID是按照递增顺序存储的。
- 当文档ID在posting list中具有较大的间隔时,使用递增的方式存储会导致posting list的长度变长,占用更多的存储空间。这也会对查询性能产生一定的影响。
- 为了解决这个问题,Elasticsearch引入了
Frame of Reference(FoR)技术。FoR可以将posting list中的文档ID转换为相对于一个参考点的差值,然后使用压缩算法对这些差值进行存储。这样可以大大减少存储空间的占用,并且不会对查询性能造成明显的影响。
使用Frame of Reference技术的好处是可以在保持查询性能的同时,减少了倒排索引的存储空间,从而提高了整体的索引效率。
CRUD
- PUT 覆盖
PUT test/doc/2
{
"name":"wangfei",
"age":27,
"desc":"热天还不让后人不认同"
}
- GET查询
-- 查询索引信息
GET test
-- 查询指定文档信息
GET test/doc/1
--查询对应索引下全部数据
GET test/doc/_search
{
"query": {
"match_all": {}
}
}
- DELETE 删除
-- 删除指定文档
DELETE test/doc/3
-- 删除整个索引
DELETE test
- POST 修改/新增
-- 修改指定属性:
POST test/doc/1/_update
{
"doc":{
"desc":"生活就像 茫茫海上"
}
}
查询
在Elasticsearch中,查询(query)是用于搜索和过滤文档的一种机制。通过查询,您可以指定要搜索的字段、搜索的条件以及其他参数来获取匹配的文档。
Elasticsearch提供了多种类型的查询,以下是一些常用的查询类型:
- Match查询:用于在文本字段中搜索包含指定词语的文档,默认会对查询的文本进行分词处理。相当于模糊匹配,只包含其中一部分关键词就行
分词:例如,如果你使用match查询搜索"Hello World",它会将文本分成两个词"hello"和"world",然后在索引中搜索包含这两个词的文档。
- Term查询:用于搜索精确匹配某个字段的词语,不会进行分词。例如,搜索
"status": "published"将返回status字段值为"published"的文档。 - Range查询:用于搜索某个字段的范围内的值。可以指定一个范围,如
"age": { "gte": 18, "lte": 30 }表示搜索age字段在18到30之间的文档。 - Bool查询:用于组合多个查询条件,包括must、must_not、should和filter等子查询。可以通过布尔逻辑(与、或、非)来组合多个查询条件。
- Wildcard查询:用于在文本字段中进行通配符匹配,如
"name": "Joh?n"将匹配"name"字段为"John"或"Joan"的文档。 - Exists查询:用于搜索包含某个字段的文档,如
"exists": { "field": "name" }将返回包含"name"字段的文档。
以上只是一些常见的查询类型,Elasticsearch还提供了更多的查询类型和功能,如全文搜索、聚合查询、地理位置查询等。
elasticsearch 常见几种查询方式
常见的查询:
term
term查询:精确查询,不分词,只能查单个词
{
"query":{
"term":{
"title":"love china",
}
}
}
- 用
term匹配多个词:使用terms数组,多个词之间是或的关系。
{
"query": {
"terms": {
"title": ["love", "China"]
}
}
}
- 也可以使用 多个 term:与
terms数组结果一样。
{
"query": {
"bool": {
"should": [
{
"term": {
"age":27
}
},{
"term":{
"age":28
}
}
]
}
}
}
match
使用match查询,会对文本进行分析器分析,模糊查询;而 term查询不会有分析器分析的过程。
match查询可以用于全文搜索(full text search)和精确匹配(exact value match)。
- 当应用于文本字段时,"match"查询会对查询字符串进行分词处理,并与字段中的词项进行匹配。它会考虑词项的顺序、重复和相似性等因素来计算匹配度,并返回匹配度最高的文档。
- 当应用于非字符串字段或者"
**not_analyzed**"类型的字段时,"match"查询会进行精确匹配。它会将查询字符串与字段的原始值进行比较,只有在完全匹配的情况下才会返回匹配的文档。
{
"query":{
"match":{
"title":"中国"
}
}
}
- 全文查询:
match_all返回所有匹配的结果。
{
"query":{
"match_all": {
}
}
}
- 短语查询 :
match_phrase
不懂可以看:Elasticsearch使用:Match_phrase查询-腾讯云开发者社区-腾讯云
- 词汇匹配 且词的相对位置一致
- 词汇匹配: 查询分词的词项必须完全匹配到索引分词的词项中
- 相对位置也需一致。默认
slop=0,即顺序必须相同且必须都是连续的。
{
"query":{
"match_phrase": {
"title": "中国风"
}
}
}
-- 匹配的结果: 中国、国风;
-- 不会匹配的结果:美国,中风,国中
slop:
{
"query":{
"match_phrase": {
"title": {
"query": "中国世界",
"slop":2
}
}
}
}
-- 中国是世界上人口最多的国家
- 最左前缀查询:
match_phrase_prefix- : 搜索特定字符、短语 开头的数据
max_expansions:最多返回的匹配项。默认为50。以对查询结果进行限制,前缀查询会非常的影响性能
{
"query": {
"match_phrase_prefix": {
"desc": "bea" 或:"desc": "you are bea",
"max_expansions":1
}
}
}
-- 匹配到以文本开头的数据
- 多字段查询:
multi_match- 要在多个不同字段(不同属性下)中匹配同一个关键字。
- 当设置属性
type:phrase时 等同于 短语查询 - 当设置属性
type:phrase_prefix时 等同于 最左前缀查询
GET test2/doc/_search
{
"query": {
"multi_match": {
"query": "beautiful",
"fields": ["title","desc"],
"type": ""
}
}
}
-- 只要包含beautiful,即返回。
"_source1" : {
"title" : "prefix1",
"desc" : "beautiful girl you are beautiful so"
}
"_source2" : {
"title" : "beautiful",
"desc" : "I like basking on the beach"
}
小总结
match_phrase ,match与term的区别:
es中的term和match的区别
- term属于精确匹配,只能查单个词。
terms里的[]多个是或者的关系,只要满足其中一个词就可以。想要通知满足两个词的话,就得使用bool的must
match默认分词,进行模糊查询,只要包含关键词则查询。- 若字段属性是
keyword类型,match也不分词。
- 若字段属性是
- match_phrase 称为短语搜索,要求所有的分词必须同时出现在文档中,同时位置必须紧邻一致。
bool查询(多条件查询)
包含四种操作符,分别是must,should,must_not,query。它们均是一种数组,数组里面是对应的判断条件
1.must:
必须匹配,与and等价。贡献算分
#### 多条件组合查询
GET test/doc/_search
{
"query": {
"bool": {
"must": [
{ "match": { "name": "wanggfei" } },
{ "match": { "age": 25 } }
]
}
}
}
2.must_not:
必须不匹配,与not等价,所有的must_not子句都不能匹配,但不贡献算分
3.should:
选择性匹配,至少满足一条,与 OR 等价。贡献算分
4.filter:
过滤子句,必须匹配,但不贡献算分
过滤器,会查询对结果进行缓存,不会计算相关度,避免计算分值,执行速度非常快。
filter也常和range范围查询一起结合使用,range范围可供组合的选项
gt : 大于
lt : 小于
gte : 大于等于
lte :小于等于
排序查询
需要分词的字段无法直接排序 eg:text 类型 。
es的text类型的排序问题
- 若需要对该类型进行排序,需要对字段索引两次:
- 索引分词(用于搜索)
- 索引不分词(进行排序)
es 默认生成的
text类型 是通过该方式实现排序
准备索引:
## mapping创建
PUT test_text_sort
{
"mappings": {
"doc": {
"properties": {
"name": {
"type": "text",
"fields":{
"row":{
"type":"keyword"
}
},
"fielddata":true
}
}
}
},
"settings": {
"number_of_replicas": 0,
"number_of_shards": 1
}
}
使用name的子字段:row 排序:
name.row
GET test_text_sort/doc/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"name.row": {
"order": "desc"
}
}
]
}
分页查询
from :开始位置; size 查询条数。
GET test/doc/_search
{
"query": {
"match_phrase_prefix": {
"name": "wang"
}
},
"from": 0,
"size": 1
}
查询结果过滤
对查询的结果指定返回某些属性:
GET test/doc/_search
{
"query":{
"match":{
"name":"wang"
}
},
"_source":["name","id"]
}
-- 指定属性返回 name、id
高亮显示
GET test/doc/_search
{
"query":{
"match":{
"name":"wang"
}
},
"highlight":{
"fields":{
"name": {} -- 默认高亮
}
}
自定义高亮:
pre_tags定义标签前部分post_tags定义标签后部分
{
"query": {
"match": {
"desc": "性格直"
}
},
"highlight": {
"pre_tags": "<b class='key' style='color:red'>",
"post_tags": "</b>",
"fields": {
"desc": {}
}
}
}
聚合查询
group 分组、avg 平均数、max、min、sum
Elasticsearch的聚合查询是一种用于对数据进行统计、分析和计算的功能强大的工具。
聚合函数的使用,一定是先查出结果,然后对结果使用聚合函数做处理!
avg、max、min、sum
eg:求平均年龄:
GET zhifou/doc/_search
{
"query": {
"match": {
"from": "gu"
}
},
"aggs": {
"my_avg": {
"avg": {
"field": "age"
}
}
},
"size":0,
"_source": ["name", "age"]
}
-- 查询 from字段包含 gu 的 年龄平均值
解释:
aggs:做聚合操作my_avg:自定义的返回结果名称avg对指定字段field求 平均数**"size":0**设置不返回具体查询结果,只返回聚合结果
查询结果:
{
"took" : 35,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 3,
"max_score" : 0.0,
"hits" : [{...},{...}... ]
},
"aggregations" : {
"my_avg" : {
"value" : 27.0
}
}
}
{
"_index" : "zhifou",
"_type" : "doc",
"_id" : "4",
"_score" : 0.6931472,
"_source" : {
"name" : "石头",
"age" : 29
}
}
返回结果键的解释:
- “took”:查询所花费的时间(以毫秒为单位)。
- “timed_out”:指示查询是否超时。
- “_shards”:关于查询涉及的分片的统计信息。
- “total”:总分片数。
- “successful”:成功执行的分片数。
- “skipped”:跳过的分片数。
- “failed”:执行失败的分片数。
- “hits”:与查询条件匹配的文档的结果。
- “total”:总匹配文档数。
- “max_score”:最相关的文档分数。
- “hits”:匹配的文档列表。
- “_index”:文档所在的索引。
- “_type”:文档的类型。
- “_id”:文档的唯一标识符。
- “_score”:文档的得分。
- “_source”:文档的原始内容。
- “
aggregations”:关于聚合操作的结果。
- “my_avg”:聚合操作的名称。
- “value”:聚合结果的值。
下面是一个示例的聚合查询请求体,展示了几种常用的聚合操作:
{
"size": 0,
"aggs": {
"group_by_age": {
"terms": {
"field": "age",
"size": 10
}
},
"average_age": {
"avg": {
"field": "age"
}
},
"sum_age": {
"sum": {
"field": "age"
}
},
"min_age": {
"min": {
"field": "age"
}
},
"max_age": {
"max": {
"field": "age"
}
}
}
}
在这个示例中,使用了以下几种聚合操作:
terms聚合:按照"age"字段进行分组,并指定返回的分组数量为10。avg聚合:计算"age"字段的平均值。sum聚合:计算"age"字段的总和。min聚合:计算"age"字段的最小值。max聚合:计算"age"字段的最大值。
这些聚合操作可以根据你的需求进行组合和嵌套,以获得更复杂的聚合结果。你还可以通过filter、range、date_histogram等子聚合来进一步细化聚合结果。
请注意,在上述示例中的查询请求体中,size参数设置为0,表示不返回任何文档,只返回聚合结果。如果你需要同时返回文档和聚合结果,请将size参数设置为大于0的数值。
分组查询
- 需求: 要查询所有人的年龄段,并且按照1520,2025,25~30分组,并且算出每组的平均年龄。
GET zhifou/doc/_search
{
"size": 0,
"query": {
"match": {
"name": "text"
}
},
"aggs": {
"range_age": {
"range": {
"field": "age", -- 根据什么属性分组
"ranges": [
{"from": 15, "to": 20},
{"from": 20, "to": 25},
{"from": 25, "to": 30}
]
},
"aggs": {
"range_avg_age": { -- 对不同的分组进行计算年龄的平均值
"avg": {
"field": "age"
}
}
}
}
}
}
查询结果:
"aggregations": {
"age_ranges": {
"buckets": [
{
"key": "15-20",
"from": 15,
"to": 20,
"doc_count": 20,
"average_age": {
"value": 18.5
}
},
{
"key": "20-25",
"from": 20,
"to": 25,
"doc_count": 30,
"average_age": {
"value": 22.3
}
},
{
"key": "25-30",
"from": 25,
"to": 30,
"doc_count": 50,
"average_age": {
"value": 27.8
}
}
]
}
}
映射Mapping
定义文档字段和据类型;
Mapping参数详解文档:
ES mapping 详解_ZhaoYingChao88的博客-CSDN博客
Elasticsearch 5.4 Mapping详解_esc_ai的博客-CSDN博客
字段数据类型:
文本(text)、关键字(keyword)、日期(data)、整形(long)、双精度(double)、布尔(boolean)或ip、对象(Object)、数组(Array)、地理位置(geo_point & geo_shape/percolator)等。
创建索引:
注意:默认情况下,创建的索引分片数量是 5 个,副本数量是 1 个。
您可以通过如下参数来指定分片数、副本数量:
# PUT http://127.0.0.1:9200/user -- 创建索引
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 2
}
}
-- 返回结果
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "user"
}
- “number_of_replicas”: 设置每个分片的副本数量。默认为1个。
- “number_of_shards”: 设置索引的主分片数量。 每个索引默认5个主分片。
- 分片是将索引的数据分布在集群中的不同节点上的方式,它可以提高搜索和并行处理的性能。
- 分片是将索引的数据分布在集群中的不同节点上的方式,它可以提高搜索和并行处理的性能。
设置mapping:
# PUT http://127.0.0.1:9200/user/_mapping
{
"properties": {
"name":{ "type": "text", "index": true },
"sex":{ "type": "keyword", "index": true },
"tel":{ "type": "keyword", "index": false }
}
}
查询映射:
#GET http://127.0.0.1:9200/user/_mapping
完整操作
使用PUT请求定义一个索引
PUT /test_index
{
"mappings": {
"doc": {
"dynamic" : true,
"properties": {
"name": {
"type": "text",
"fields": {
"row": {
"type": "keyword"
}
},
"fielddata": true
},
"age": {
"type": "integer"
}
}
}
}
}
创建了索引 test_index。在索引的"mappings"部分中,定义类型:doc,两段:“name"和"age”。
- “name"字段的类型是"text”,定义子字段"row",其类型是"keyword"。这样做是为了在排序时可使用**"raw"子字段,以便于进行精确匹配、聚合操作和排序。**
- “age"字段的类型是"integer”,表示它是一个整数类型的字段。
fielddata详见:fielddata
Mapping常见参数
fields
为字段定义子字段,使得同一个字段可以有多个不同的索引方式。
- "fields"属性使用范围:
- 主字段的类型必须是支持多个类型的主字段类型,
"text"、"keyword"或"completion"等。这样才能为字段定义多个子字段。
- eg:String类型的字段,可以 text 全文索引,也可 keyword 聚合和排序
PUT my_index
{
"mappings": {
"properties": {
"title": {
"type": "text",
"fields": {
"accurateSearch": {
"type": "keyword"
},
"suggest": {
"type": "completion"
}
}
}
}
}
}
在上面的示例中,我们定义了一个名为"title"的字段,它的主字段类型为"text"。同时,我们还为"title"字段定义了两个子字段:“keyword"和"suggest”。
- “accurateSearch"子字段的类型为"keyword”,这意味着它将被索引为一个精确值,适合进行精确匹配和聚合操作。
- “suggest"子字段的类型为"completion”,这意味着它将被用于自动补全和建议功能。
通过这样的设置,我们可以在搜索时同时对"title"字段进行全文搜索、对"keyword"字段进行精确匹配搜索,以及使用"suggest"字段进行自动补全和建议。
dynamic动态字段映射

在Elasticsearch中,"dynamic"是一个用于控制字段映射行为的设置。它有三种状态:
- “dynamic”: true - 默认状态。当索引文档时,如果遇到未定义的字段, 这个字段可以被索引(ES根据内容自动识别字段类型),mapping会自动更新。
- “dynamic”: false - 当索引文档时,如果遇到未定义的字段,Elasticsearch会忽略该字段而不创建映射。这种状态下,字段的映射是静态的,mapping不会被更新,该字段不会被索引。
- “dynamic”: “strict” - 当索引文档时,如果遇到未定义的字段,Elasticsearch会抛出异常,表示字段未定义。这种状态下,字段的映射严格,会强制要求所有字段都必须在映射中定义。
index
设置该字段是否被索引。
index属性默认为true。
- 如果该属性设置为false,elasticsearch不会为该属性创建索引,也就是说无法当做主查询条件。
index_options
控制索引时存储哪些信息到倒排索引。
- doc:只记录 doc id
- freqs:记录 doc id 和 term frequencies (词项频率)
- positions:记录 doc id、term frequencies (词项频率) 和 term position (词项位置)
- offsets:记录 doc id、term frequencies、term position 和 character offects(词项偏移量)
text 类型默认配置为 positions,其他类型默认为 doc,记录内容越多,占用存储空间越大。
"properties": {
"user_name":{
"index": false,
"type": "text"
},
"info":{
"index_options": "positions",
"type": "text"
}
}
null_value
值为null的字段不能被索引和搜索。使用null_value参数可以让值为null的字段显式的可索引。GET users/_search?q=mobile:NULL
"mobile":{
"type":"keyword",
"null_value":"NULL"
}
copy_to
copy_to属性用于配置自定义的_all字段。换言之,就是将多个字段可以合并成一个超级字段。比如,first_name和last_name可以合并为full_name字段。
PUT my_index
{
"mappings": {
"my_type": {
"properties": {
"first_name": {
"type": "text",
"copy_to": "full_name"
},
"last_name": {
"type": "text",
"copy_to": "full_name"
},
"full_name": {
"type": "text"
}
}
}
}
}
- 多条件查询:
GET test8/doc/_search
{
"query": {
"match": {
"full_name": {
"query": "tom smith",
"operator": "or"
}
}
}
}
----- 法2
GET test8/doc/_search
{
"query": {
"match": {
"full_name": "tom smith"
}
}
}
- 将一个字段值复制到多个不同的字段:
"first_name":{
"type": "text",
"copy_to": ["full_name1","full_name2"]
},
ignore_above
仅使用于 **keyword** 类型。 设置字段索引存储最大值;若超过最大值会被忽略。
"name": {
"type": "keyword",
"ignore_above":5
}
fielddata
用于 将指定字段加载到内存中,以便于 进行聚合、排序、脚本等操作。
- 使用范围: 支持被索引的字段类型:
text、keyword、numeric等。 若字段类型不支持被索引,则设置失效。 - 默认禁用。缺点:占用大量内存资源; 可使用
doc_values代替 之,
PUT my_index
{
"mappings": {
"properties": {
"age": {
"type": "integer",
"fielddata": true
}
}
}
}
doc_values
doc_values是为了加快排序、聚合操作,在建立倒排索引的时候,额外增加一个列式存储映射,是一个空间换时间的做法。默认是开启的,对于确定不需要聚合或者排序的字段可以关闭。
对于某些字段类型,如"text"和"keyword",“doc_values"属性并不适用。这些字段类型通常用于全文搜索和过滤,而不需要进行聚合、排序或脚本操作。对于这些字段类型,默认情况下不会启用"doc_values”。
注:text类型不支持doc_values。
PUT my_index
{
"mappings": {
"my_type": {
"properties": {
"status_code": {
"type": "keyword"
},
"session_id": {
"type": "keyword",
"doc_values": false
}
}
}
}
}
整合
尚硅谷笔记:
Elasticsearch学习笔记_巨輪的博客-CSDN博客
黑马:
Elasticsearch分布式引擎7.x,2021黑马详细课程笔记_2021年 最新版 传智黑马搜索引擎elasticsearch_努力学习编程Sakura的博客-CSDN博客
ElasticSearch (ES)万字黑马学习笔记(超详细)搜索引擎ElasticSearch7.x笔记_elasticsearch黑马笔记_努力学习编程Sakura的博客-CSDN博客
系统学习
系统学习ElasticSearch
一起读ElasticSearch官方文档
一些特殊的类型
- “_index”:用于表示索引的名称。
- “type”:用于表示文档的类型。在Elasticsearch 7.x及以上的版本中_,"_type"已经不被推荐使用,因为Elasticsearch团队将在未来的版本中移除这个概念。
- “_id”:每个文档在索引中都有一个唯一的标识符,称为文档ID。"_id"字段用于表示文档的ID。
- “_source”: 指定要返回的字段
- “_score”:表示文档与查询匹配的相关性分数。
_doc:表示文档类型
需要注意的是,Elasticsearch 7.x及以上的版本中,默认只支持单一的类型"_doc",这是为了简化数据模型并提高性能。因此,推荐在创建索引时使用"_doc"作为文档类型。
涉及原理
什么是 Elasticsearch?一篇搞懂-腾讯云开发者社区-腾讯云

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!