爬取猫咪交易网
爬取猫咪品种,价格等在售数据
代码展现: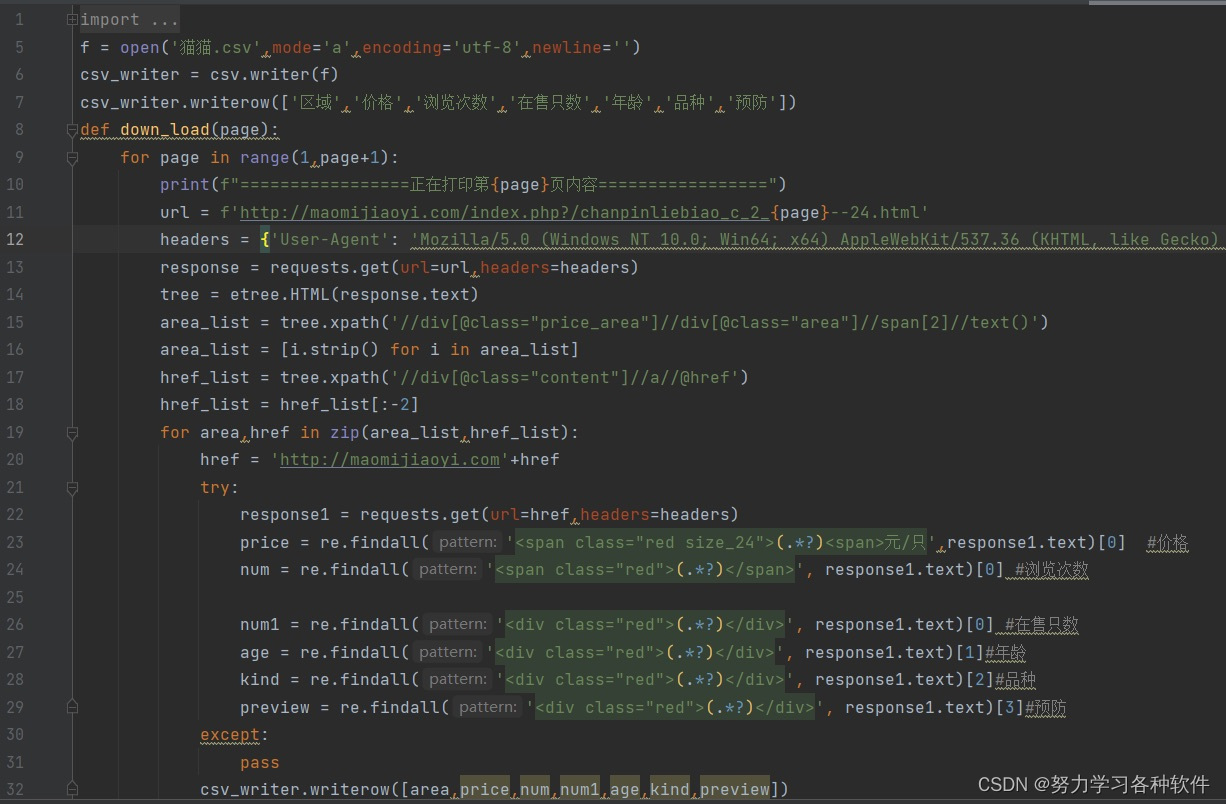
 ?
?
具体代码:
import requests
import re
import os
filename = '声音//'
if not os.path.exists(filename):
? ? os.mkdir(filename)
def down_load(page):
? ? for page in range(page):
? ? ? ? page = page+1
? ? ? ? url = 'https://www.tosound.com/search/word-/page-'+str(page)
? ? ? ? headers = {'User-Agent':
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36',
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?}
? ? ? ? response = requests.get(url=url,headers=headers)
? ? ? ? # print(response.text)
? ? ? ? href = re.findall('<div class="ui360 ui360-vis"><a href="(.*?)"></a></div>',response.text)
? ? ? ? title = re.findall('<a class="h6 text-white font-weight-bold" target="_blank" href=".*?" title="(.*?)">.*?',response.text)
? ? ? ? for href,title in zip(href,title):
? ? ? ? ? ? print(title,href)
? ? ? ? ? ? content = requests.get(url=href,headers=headers).content
? ? ? ? ? ? with open(filename+title+'.mp4',mode='wb') as f:
? ? ? ? ? ? ? ? f.write(content)
down_load(4)
结果展现: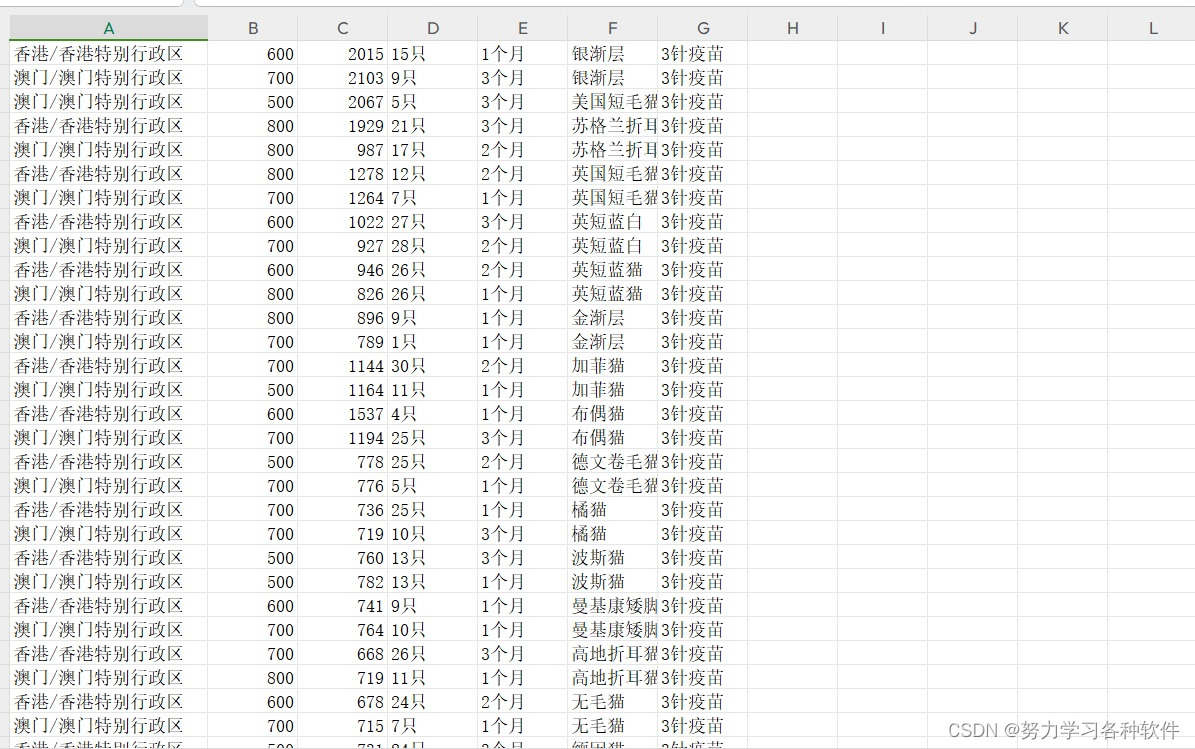
反思与总结:1.如何用正则匹配html中换行的数据,如 ?
?
我想要匹配电话,却总是空,把上面的连在一起匹配,也是一样,是换行符的问题吗?
?2.像这种抓爬静态页面,零碎的信息,用css选择器更好!
3.这一案例属于两静态?页面抓取,信息都在页面代码中,抓包容易,难点在于如何解析数据。
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!