【AI】Transformer中的概念理解
1.Embedding
Embedding的概念理解
Embedding,直译是词嵌入、嵌入层。
计算机无法直接处理一个单词或者一个汉字,需要把一个token转化成计算机可以识别的向量,这也就是Embedding过程。
Embedding就是用一个低维稠密的向量表示一个对象,这里的对象可以是一个词(Word2vec),也可以是一个物品(Item2vec),亦或是网络关系中的节点(Graph Embedding)。Embedding向量能够表达对象的某些特征,两个向量之间的距离反映了对象之间的相似性。简单的说,Embedding就是把一个东西映射到一个向量X。如果这个东西很像,那么得到的向量x1和x2的欧式距离很小。
Embedding操作的由来
例如在处理自然语言时,我们把句子转换成矩阵表示,也就是one-hot编码,如果是100w行的大文本,简繁体字有10w个,表示出来就是100w10w的大矩阵,而这个矩阵还是稀疏矩阵,容量爆炸,信息量反而很小,所以我们要考虑给它降维,给它乘上一个10w20的矩阵就可以把大矩阵转换成100w*20的矩阵,容量直接缩小5000倍。
Embedding的作用
-
降维
Embedding层实现了降维的作用,降维的原理是根据矩阵乘法。
例如一个210的二维矩阵与一个103的二维矩阵相乘,得到一个2*3的二维矩阵,从效果上来看是实现了10->3维度上的降维 -
升维
对低维数据进行升维时,可以把一些其他特征放大,或者把笼统的特征给分开。
因此它就是作为这个桥梁的存在,让我们手头的东西可伸可缩,变成我们希望的样子。
Transformer中Embedding的实现
transformer的输入是Word Embedding + Position Embedding
Word Embedding
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
super(Embeddings, self).__init__()
self.lut = nn.Embedding(vocab, d_model)
self.d_model = d_model #表示embedding的维度
def forward(self, x):
return self.lut(x) * math.sqrt(self.d_model)
Position Embedding
# Positional Encoding
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0., max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0., d_model, 2) *
-(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term) # 偶数列
pe[:, 1::2] = torch.cos(position * div_term) # 奇数列
pe = pe.unsqueeze(0) # [1, max_len, d_model]
self.register_buffer('pe', pe)
def forward(self, x):
x = x + Variable(self.pe[:, :x.size(1)], requires_grad=False)
return self.dropout(x)
2.Attention
Attention机制可以简单的认为是相似度的计算。
2.1 Attention的由来
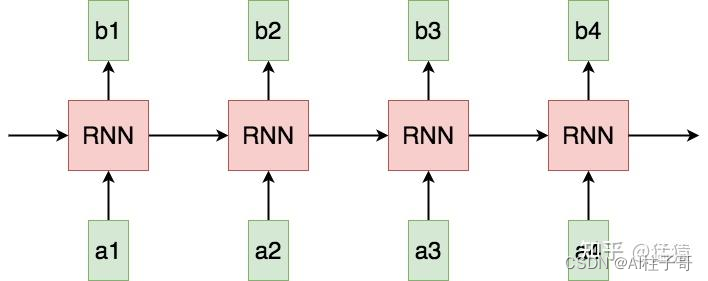
在RNN的网络计算中,token是串行的喂给模型的,并且token之间是相互独立的,这就导致存在以下问题
(1) Sequential operations的复杂度随着序列长度的增加而增加。
这是指模型下一步计算的等待时间,在RNN中为O(N)。该复杂度越大,模型并行计算的能力越差,反之则反。
(2) Maximum Path length的复杂度随着序列长度的增加而增加。
这是指信息从一个数据点传送到另一个数据点所需要的距离,在RNN中同样为O(N),距离越大,则在传送的过程中越容易出现信息缺失的情况,即数据点对于远距离处的信息,是很难“看见”的。
所以Attention机制就来了,它是在计算每个token的时候,都将它和其他token计算一个相似度,这样每个token在喂给模型时不需要依赖前端的输出,提高了并行的能力,同时不会因为计算深度的加深,导致信息丢失。
2.2 Self-Attention
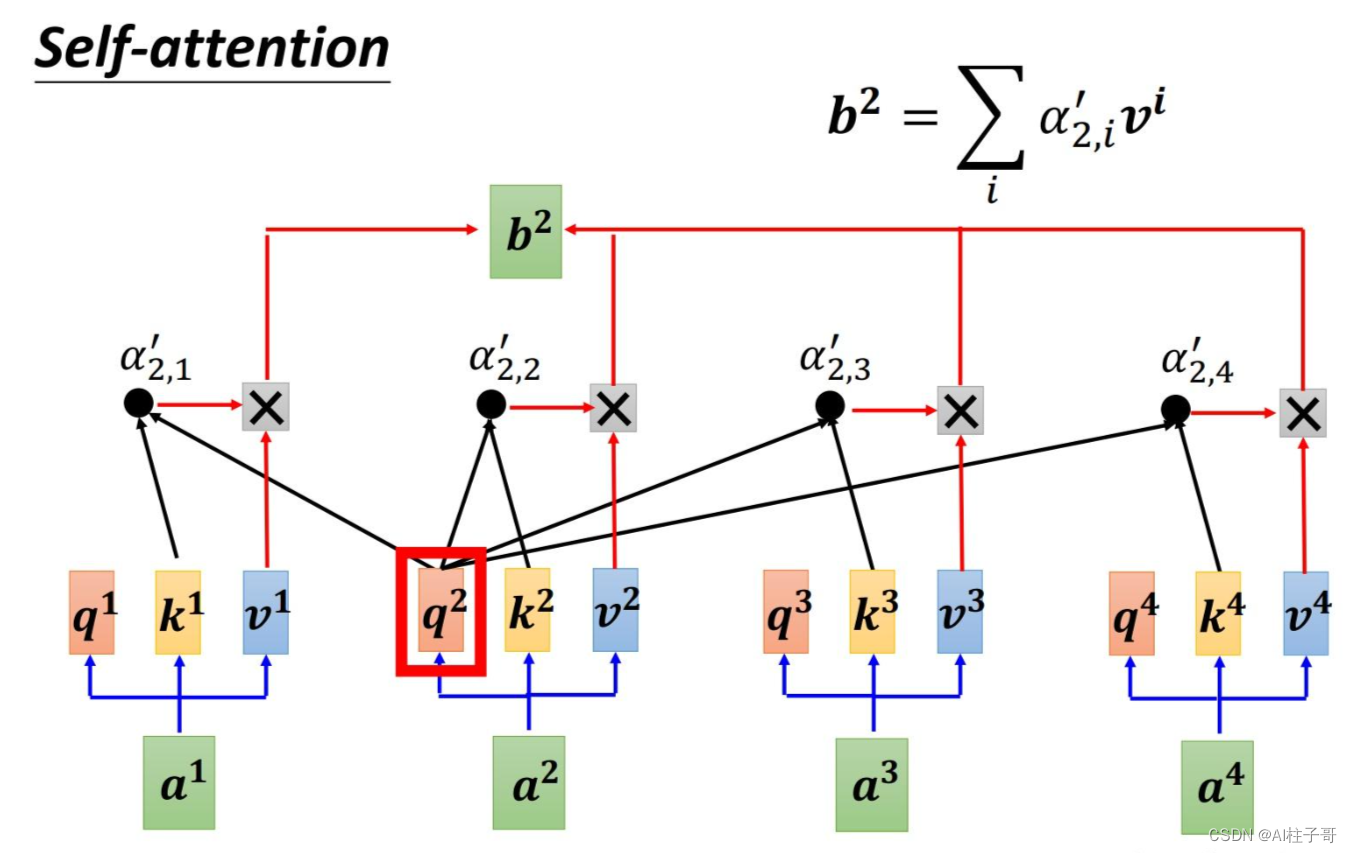
以图中的token a2为例:
它产生一个query,每个query都去和别的token的key做“某种方式”的计算,得到的结果我们称为attention score。则一共得到四个attention score。(attention score又可以被称为attention weight)。
将这四个score分别乘上每个token的value,我们会得到四个抽取信息完毕的向量。
将这四个向量相加,就是最终a2过attention模型后所产生的结果b2。
VIT论文中Self Attention的计算公式:
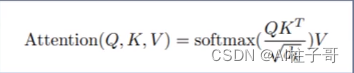
q:Query 查询词
k:Key 键值,关键词
v:Value 价值,数值
计算每个q和k的相识度。实现是使用点积的形式。
dk是维度,vit中是64;除以dk是为了避免较大的值,较大的值会导致softmax之后值更极端,softmax的极端值会导致梯度消失。
softmax处理使结果均值为0,方差为1;保证相加后为1.
2.3 Multihead Attention
本质上,就是训练num_heads个 wq,wk,wv权重矩阵,用于生成num_heads个结果。每个结果的计算方式和单头的attention的计算方式一致。最终将生成的b连接起来生成最后的结果。
流程如下:
1.图像切分重排
2.图像编码Embedding
3.混合位置编码Position Embedding
0位为class token,继承自nlp,表示类别
4.Transformer Encoder
参考文章
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!