深度解析ShardingJDBC:Java开发者的分库分表利器
一、ShardingSphere

????????ShardingSphere?是一款起源于当当网内部的应用框架。2015年在当当网内部诞?生,最初就叫ShardingJDBC?。2016年的时候,由其中一个主要的开发人员张亮, 带入到京东数科,组件团队继续开发。在国内历经了当当网、电信翼支付、京东数?科等多家大型互联网企业的考验,在2017年开始开源。并逐渐由原本只关注于关系?型数据库增强工具的ShardingJDBC?升级成为一整套以数据分片为基础的数据生态??圈,更名为ShardingSphere?。到2020年4月,已经成为了Apache软件基金会的顶级项目。
????????ShardingSphere包含三个重要的产品,ShardingJDBC、ShardingProxy和ShardingSidecar。其中sidecar是针对service?mesh定位的一个分库分表插件,目?前在规划中。而我们今天学习的重点是ShardingSphere?的JDBC?和Proxy这两个组??件。
????????其中,?ShardingJDBC??是用来做客户端分库分表的产品,而ShardingProxy??是?用?来做服务端分库分表的产品。这两者定位有什么区别呢?我们看下官方资料中给出的两个重要的图:
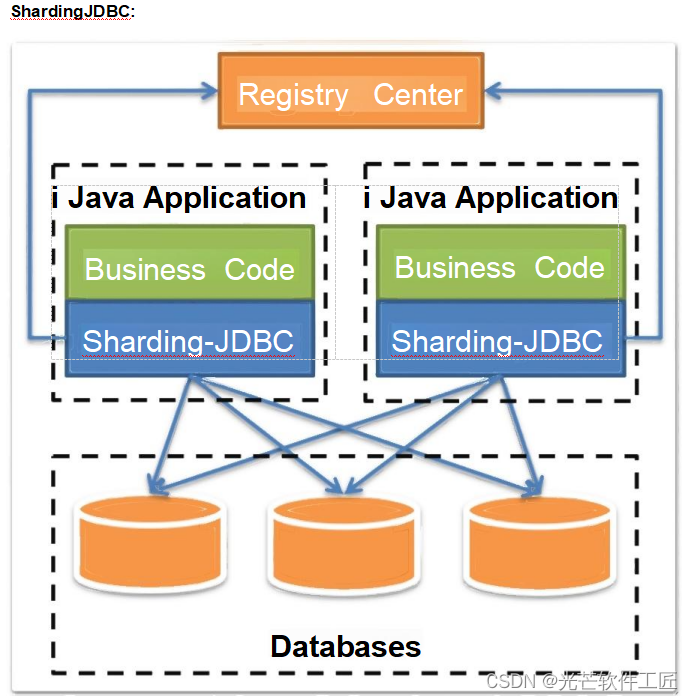
????????shardingJDBC?定位为轻量级?Java?框架,在?Java?的 JDBC?层提供的额外服务。它使用客户端直连数据库,以jar?包形式提供服务,无需额外部署和依赖,可理解为增强版的?JDBC?驱动,完全兼容?JDBC?和各种?ORM??框架。
ShardingProxy

????????ShardingProxy?定位为透明化的数据库代理端,提供封装了数据库二进制协议的服?务端版本,用于完成对异构语言的支持。目前提供?MySQL??和 PostgreSQL??版本,它可以使用任何兼容?MySQL/PostgreSQL???协议的访问客户端。
????????那这两种方式有什么区别呢?

????????很显然, ShardingJDBC??只是客户端的一个工具包,可以理解为一个特殊的JDBC驱动包,所有分库分表逻辑均由业务方自己控制,所以他的功能相对灵活,支持的?数据库也非常多,但是对业务侵入大,需要业务方自己定制所有的分库分表逻辑。??而ShardingProxy?是一个独立部署的服务,对业务方无侵入,业务方可以像用一个?普通的MySQL??服务一样进行数据交互,基本上感觉不到后端分库分表逻辑的存在,
????????但是这也意味着功能会比较固定,能够支持的数据库也比较少。这两者各有优劣。
二、ShardingJDBC实战
????????shardingjdbc的核心功能是数据分片和读写分离,通过ShardingJDBC,应用可以 ?透明的使用JDBC访问已经分库分表、读写分离的多个数据源,而不用关心数据源的数量以及数据如何分布。
1、核心概念:
- 逻辑表:水平拆分的数据库的相同逻辑和数据结构表的总称
- 真实表:在分片的数据库中真实存在的物理表。
- 数据节点:数据分片的最小单元。由数据源名称和数据表组成
- 绑定表:分片规则一致的主表和子表。
- 广播表:也叫公共表,指素有的分片数据源中都存在的表,表结构和表中的数据在每个数据库中都完全一致。例如字典表。
- 分片键:用于分片的数据库字段,是将数据库(表)进行水平拆分的关键字段。SQL中若没有分片字段,将会执行全路由,性能会很差。
- 分片算法:通过分片算法将数据进行分片,支持通过=、BETWEEN和IN分片。分片算法需要由应用开发者自行实现,可实现的灵活度非常高。
- 分片策略:真正用于进行分片操作的是分片键+分片算法,也就是分片策略。在 ShardingJDBC中一般采用基于Groovy表达式的inline分片策略,通过一个包含?分片键的算法表达式来制定分片策略,如t_user_$->{u_id%8}标识根据u_id模???8,分成8张表,表名称为t_user_0到t_user_7。
-
2、测试项目介绍
-
????????测试项目参见配套的ShardingDemo项。首先我们对测试项目的结构做下简单的梳理:

-
注:1、引入MyBatisPlus依赖,简化JDBC操作,这样我们就不需要在代
码中写SQL语句了。
2、entity中的实体对象就对应数据库中的表结构。而mapper 中的接口 则对应JDBC操作。
3、所有操作均使用JUnit的测试案例执行。后续所有测试操作都会配合 application.properties 中的配置以及JUnit测试案例进行。
4、关于ShardingSphere版本,由于目前最新的5.0版本还在孵化当中, 所以我们使用已发布的4.1.1版本来进行学习。 -
3、快速实战
-
我们先运行一个简单的实例,来看下ShardingJDBC是如何工作的。
在application.properties配置文件中写入application01.properties文件的内容:
-
#垂直分表策略 # 配置真实数据源 spring.shardingsphere.datasource.names=m1 # 配置第 1 个数据源 spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSo urce spring.shardingsphere.datasource.m1.driver-class- name=com.mysql.cj.jdbc.Driver spring.shardingsphere.datasource.m1.url=jdbc:mysql://localhost:3306/coursed b?serverTimezone=GMT%2B8 spring.shardingsphere.datasource.m1.username=root spring.shardingsphere.datasource.m1.password=root # 指定表的分布情况 配置表在哪个数据库里,表名是什么。水平分表,分两个表: m1.course_1,m1.course_2 spring.shardingsphere.sharding.tables.course.actual-data-nodes=m1.course_$- >{1..2} # 指定表的主键生成策略 spring.shardingsphere.sharding.tables.course.key-generator.column=cid spring.shardingsphere.sharding.tables.course.key-generator.type=SNOWFLAKE #雪花算法的一个可选参数 spring.shardingsphere.sharding.tables.course.key- generator.props.worker.id=1 #使用自定义的主键生成策略 #spring.shardingsphere.sharding.tables.course.key-generator.type=MYKEY #spring.shardingsphere.sharding.tables.course.key-generator.props.mykey- offset=88 #指定分片策略 约定cid值为偶数添加到course_1表。如果是奇数添加到course_2表。 # 选定计算的字段 spring.shardingsphere.sharding.tables.course.table- strategy.inline.sharding-column= cid # 根据计算的字段算出对应的表名。 spring.shardingsphere.sharding.tables.course.table- strategy.inline.algorithm-expression=course_$->{cid%2+1} # 打开sql日志输出。 spring.shardingsphere.props.sql.show=true spring.main.allow-bean-definition-overriding=true然后我们执行测试案例中的addcourse?案例。
-

-
执行后,我们可以在控制台看到很多条这样的日志:
-

-
????????从这个日志中我们可以看到,程序中执行的Logic SQL经过ShardingJDBC处理后, 被转换成了Actual SQL往数据库里执行。执行的结果可以在MySQL中看到,course_1和course_2两个表中各插入了五条消息。这就是ShardingJDBC帮我们进 行的数据库的分库分表操作。
-

-
然后,其他的几个配置文件依次对应了其他几种分库分表策略,我们可以——演示一下。
·application02.properties: 分库分表示例配置。内置分片算法示例,?inline、standard、complex、hint。?广播表配置示例。
·application03.properties:? ?绑定表示例配置
·application04.properties:??读写分离示例配置
-
4、ShardingJDBC??的分片算法
- ????????ShardingJDBC 的整个实战完成后,可以看到,整个分库分表的核心就是在于配 ?置的分片算法。我们的这些实战都是使用的inline分片算法,即提供一个分片键和一 个分片表达式来制定分片算法。这种方式配置简单,功能灵活,是分库分表最佳的 ?配置方式,并且对于绝大多数的分库分片场景来说,都已经非常好用了。但是,如 ?果针对一些更为复杂的分片策略,例如多分片键、按范围分片等场景,inline ? 分片算 法就有点力不从心了。所以,我们还需要学习下ShardingSphere 提供的其他几种分片策略。
-
NoneShardingStrategy - 无分片。此配置实际上不涉及数据分片,但ShardingSphere提供此选项以应对不需分片的场景。
-
InlineShardingStrategy - 常用分片方式。配置包括:
inline.shardingColumn:分片键。inline.algorithmExpression:分片表达式。 实现:根据分片表达式执行数据分片。
-
StandardShardingStrategy - 仅支持单分片键的标准分片策略。配置涉及:
standard.sharding-column:分片键。standard.precise-algorithm-class-name:精确分片算法类名,必须实现io.shardingsphere.api.algorithm.sharding.standard.PreciseShardingAlgorithm接口。例如:com.roy.shardingDemo.algorithm.MyPreciseShardingAlgorithm。standard.range-algorithm-class-name:范围分片算法类名,实现io.shardingsphere.api.algorithm.sharding.standard.RangeShardingAlgorithm接口。例如:com.roy.shardingDemo.algorithm.MyRangeShardingAlgorithm。 实现:使用shardingColumn指定的分片键和提供的算法进行分片。其中精确分片算法是必需的,范围分片算法则是可选的。
-
ComplexShardingStrategy - 支持多分片键的复杂分片策略。配置包括:
complex.sharding-columns:多个分片键。complex.algorithm-class-name:分片算法实现类。 实现:综合多个分片列进行分片,使用org.apache.shardingsphere.api.sharding.complex.ComplexKeysShardingAlgorithm接口的实现类。例如:com.roy.shardingDemo.algorithm.MyComplexKeysShardingAlgorithm。
-
HintShardingStrategy - 不基于SQL分片键的强制分片策略。此策略允许程序指定分片键,适用于复杂的SQL情况。配置包括:
hint.algorithm-class-name:分片算法实现类,实现org.apache.shardingsphere.api.sharding.hint.HintShardingAlgorithm接口。例如:com.roy.shardingDemo.algorithm.MyHintShardingAlgorithm。 实现:通过HintManager.addDatabaseShardingValue和HintManager.addTableShardingValue方法指定分片键。注意,此分片键仅在当前线程有效,应在使用后立即关闭。
-
Hint分片策略不依赖SQL解析树,可能在处理复杂语句时性能更佳。但需注意其在使用上的限制,如不支持UNION和多层子查询,也不能用于函数计算。这些限制导致即使使用ShardingSphere框架,分库分表后对SQL语句的支持仍然脆弱。
-
????????而Hint分片策略并没有完全按照SQL解析树来构建分片策略,是绕开 了SQL解析的,所有对某些比较复杂的语句,Hint分片策略性能有可能会比较好(情况太多了,无法一一分析)。
但是要注意,Hint强制路由在使用时有非常多的限制: -
-- 不支持UNION SELECT * FROM t_order1 UNION SELECT * FROM t_order2 INSERT INTO tbl_name (col1, col2, … ) SELECT col1, col2, … FROM tbl_name WHERE col3 = ? -- 不支持多层子查询 SELECT COUNT (*) FROM (SELECT * FROM t_order o WHERE o.id IN (SELECT id FROM t_order WHERE status = ?)) -- 不支持函数计算。ShardingSphere只能通过SQL字面提取用于分片的值 SELECT * FROM t_order WHERE to_date(create_time, 'yyyy-mm-dd ') = '2019-01-01 ';
-
-
-
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!