Docker中部署ElasticSearch 和Kibana,用脚本实现对数据库资源的未授权访问
2023-12-13 03:53:47
图未保存,不过文章当中的某一步骤可能会帮助到您,那么:感恩!
1、docker中拉取镜像
#拉取镜像
docker pull elasticsearch:7.7.0
#启动镜像
docker run --name elasticsearch -d -e ES_JAVA_OPTS="-Xms512m -Xmx512m" -e "discovery.type=single-node" -p 9200:9200 -p 9300:9300 elasticsearch:7.7.0
2、熟悉目录
bin 启动文件
config 配置文件
log4j2 日志配置文件
jvm.options JAVA 虚拟机相关配置文件
ElasticSearch 的配置文件 !默认端口为9200 跨域
lib 相关jar包
modules 功能模块
3、启动,访问9200
4、访问测试
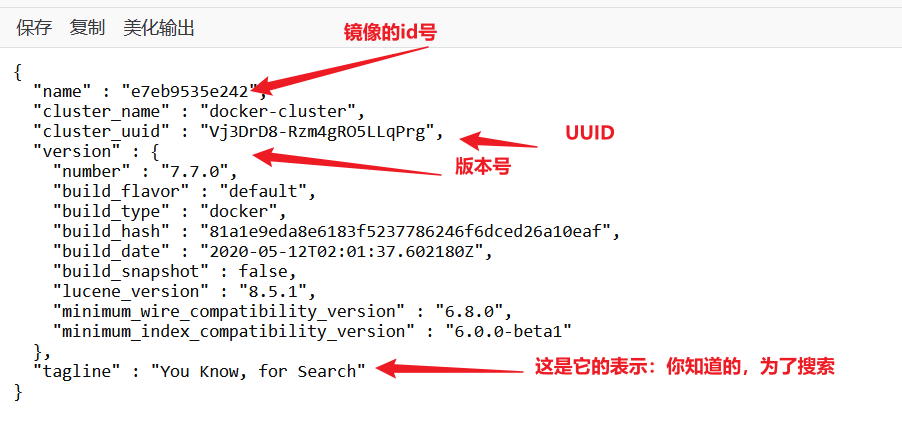
安装可视化页面es head
1、下载(同样使用docker环境)
#拉取镜像
docker pull mobz/elasticsearch-head:5
#创建容器
docker create --name elasticsearch-head -p 9100:9100 mobz/elasticsearch-head:5
#启动容器
docker start 容器id (docker ps -a 查看容器id )
2、启动
http://ip:9100
3、连接测试easticsearch发现失败,是前后端分离开发存在跨域问题,需要在服务端做CORS的配置
(1)进入docker当中
docker exec -it id /bin/bash
(2) 进入 elasticsearch.yml文件中
vi config/elasticsearch.yml
文末添加数据
http.cors.enabled:true
http.cors.allow-orgin:"*"
退出重启es服务器
exit
docker restart 容器id
4、重启es服务器后,然后在此连接集群(先前的截图没有截,这里边的地址是你部署es的地址)

()初学时把es当作数据库!(可以建立索引(库),文档(库中的数据!))
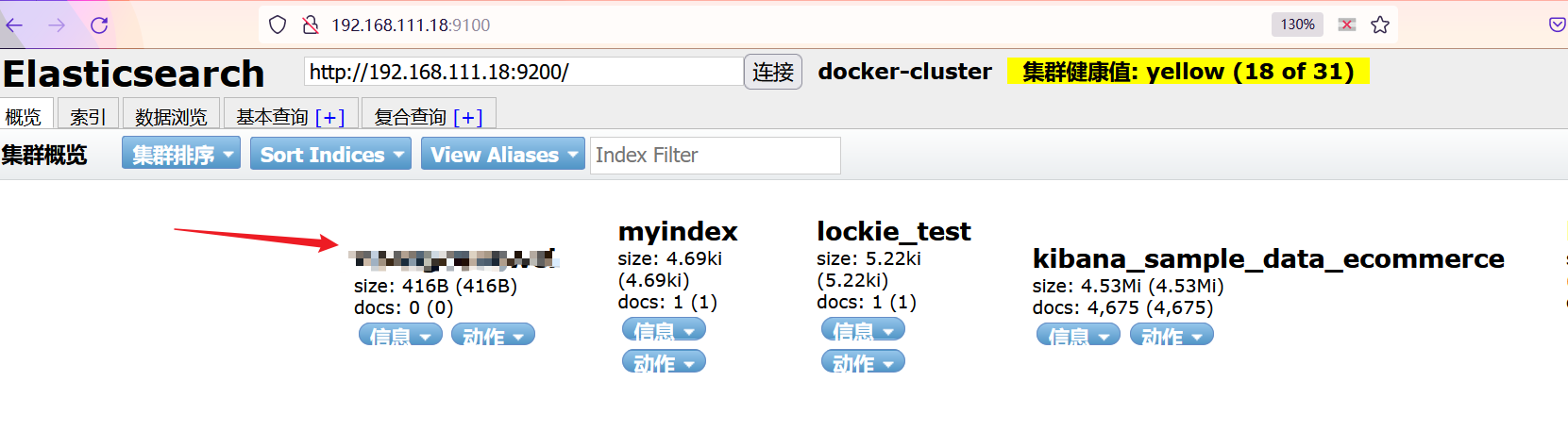
图中的数字代表集群的分辨信息
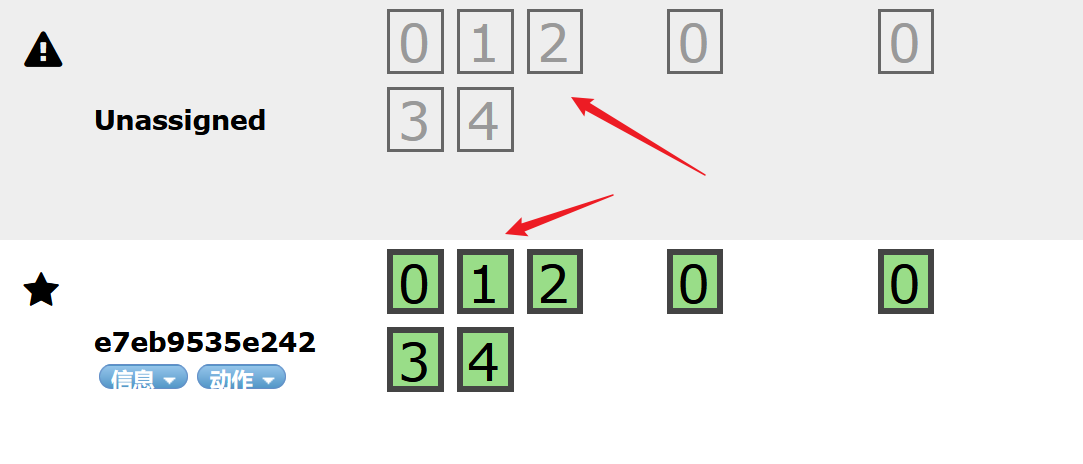
这个head就把它当作一个数据展示工具 !想要查询数据,使用kibana
使用docker安装部署kibana
介绍:
Kibana 是为 Elasticsearch设计的开源分析和可视化平台。
你可以使用 Kibana 来搜索,查看存储在 Elasticsearch 索引中的数据并与之交互。
你可以很容易实现高级的数据分析和可视化,以图标的形式展现出来。
1、拉取镜像
#拉去Kibana
docker pull kibana:7.7.0
2.启动容器:
docker run --name kibana -e ELASTICSEARCH_HOSTS=http://搭建elasticsearch IP地址:9200 -p 5601:5601 -d kibana:7.6.2
3、进入容器
docker exec -it 容器ID /bin/sh
修改配置文件
vi /usr/share/kibana/config/kibana.yml
将内容添加进去
server.name: kibana
server.host: "0"
#elasticsearch.hosts: [ "http://elasticsearch的IP:9200" ]
elasticsearch.hosts: [ "http://自己的elasticsearch的IP:9200" ]
xpack.monitoring.ui.container.elasticsearch.enabled: true
#设置kibana中文显示
i18n.locale: zh-CN
4、访问5601端口后,最终呈现页面
简单操作
ES基本操作
1、PUT增加数据
格式:
PUT /索引名/类型名/文档id(数据)
{
请求体
}
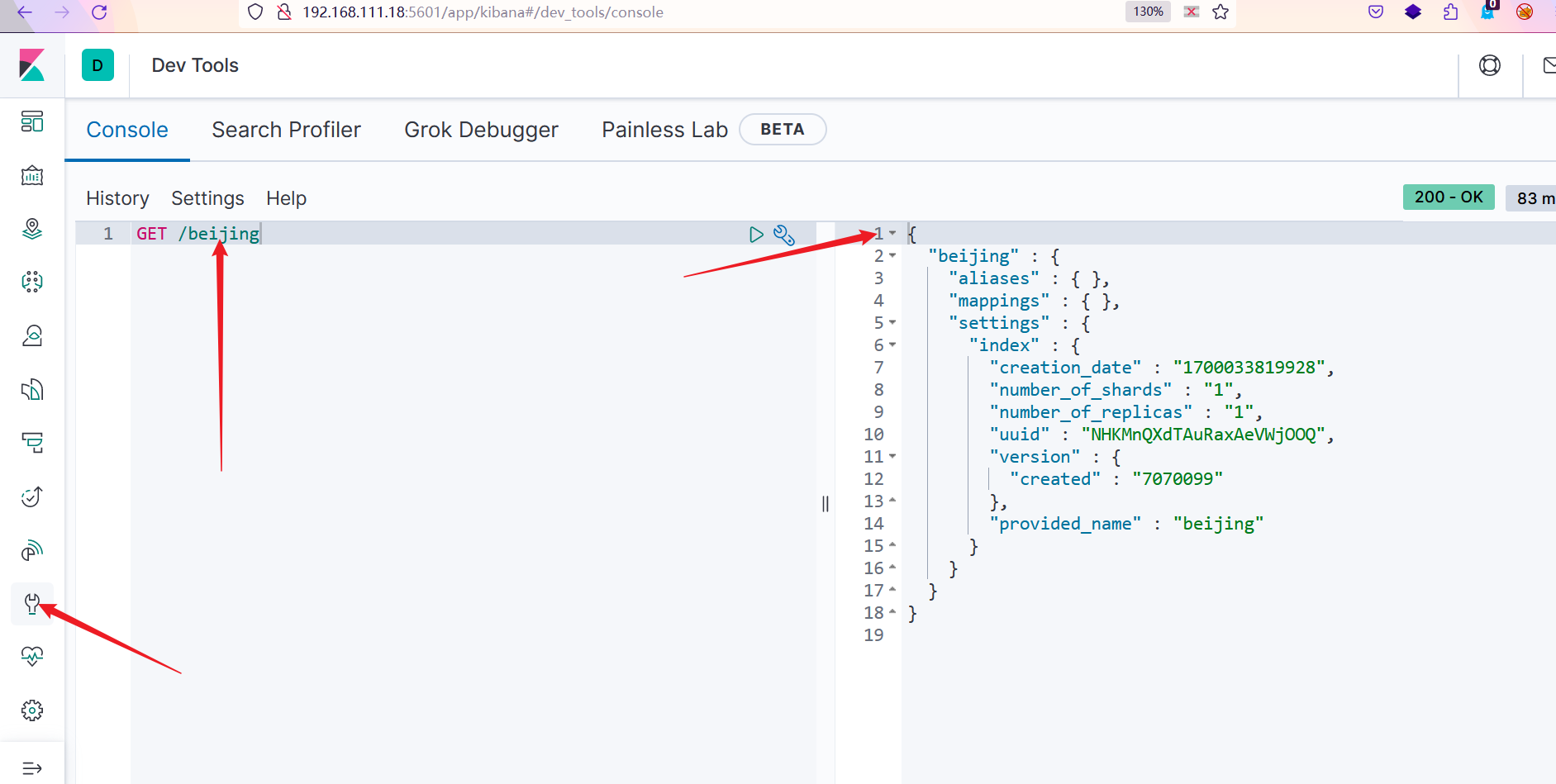
PUT /test1/type1/1
{
"name":"云山",
"age":999
}
执行完后的格式
_index:索引名
_type:类型名
_id:文档id
(1)插入索引
回到header 点击数据浏览——》选择索引
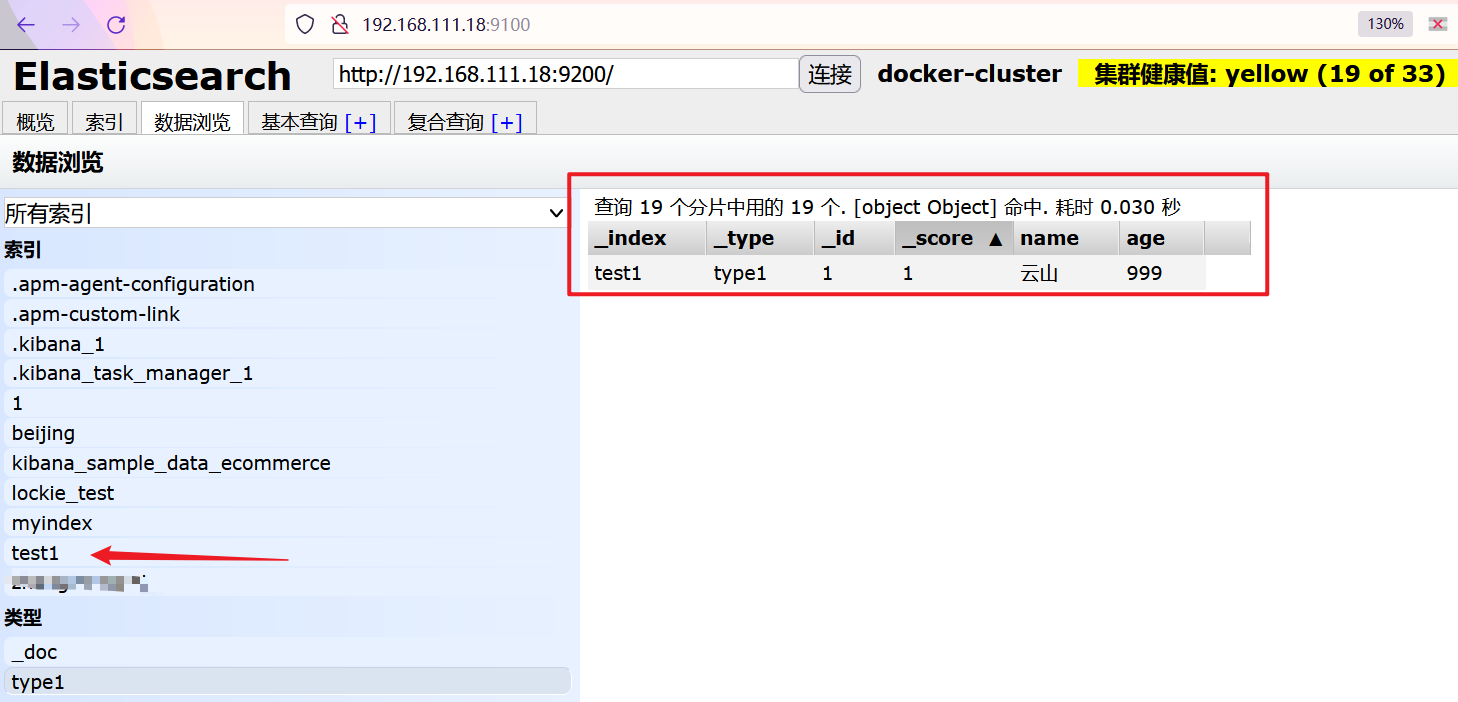
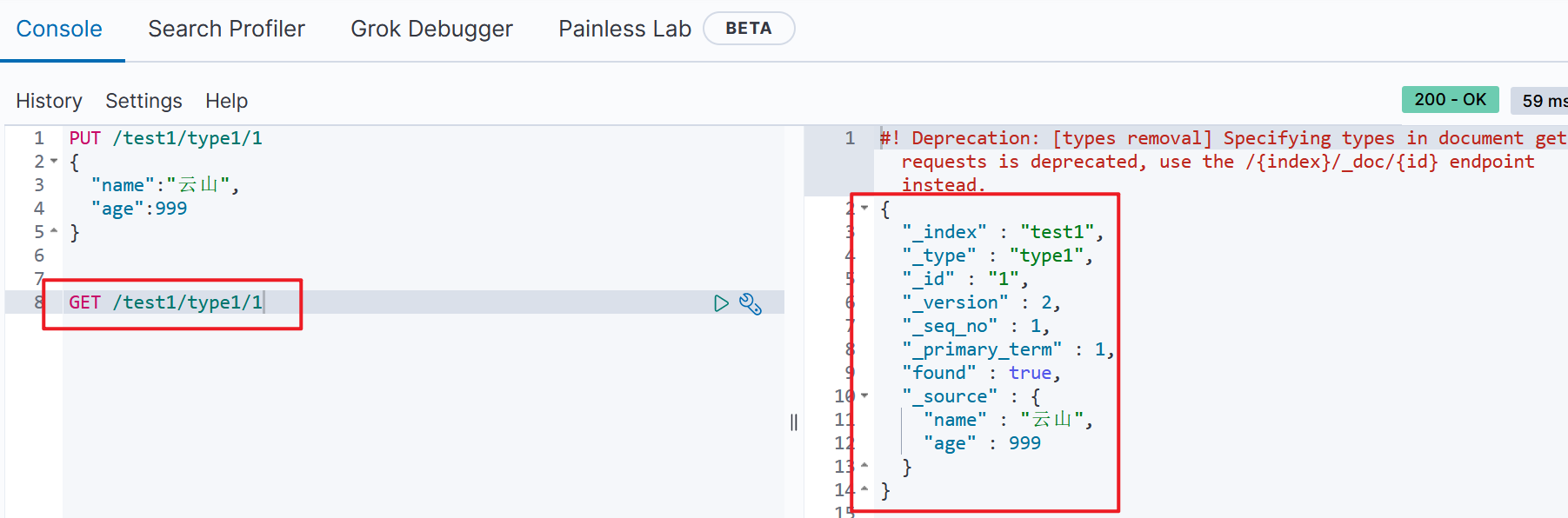
(2)获取索引库中的某条文档数据
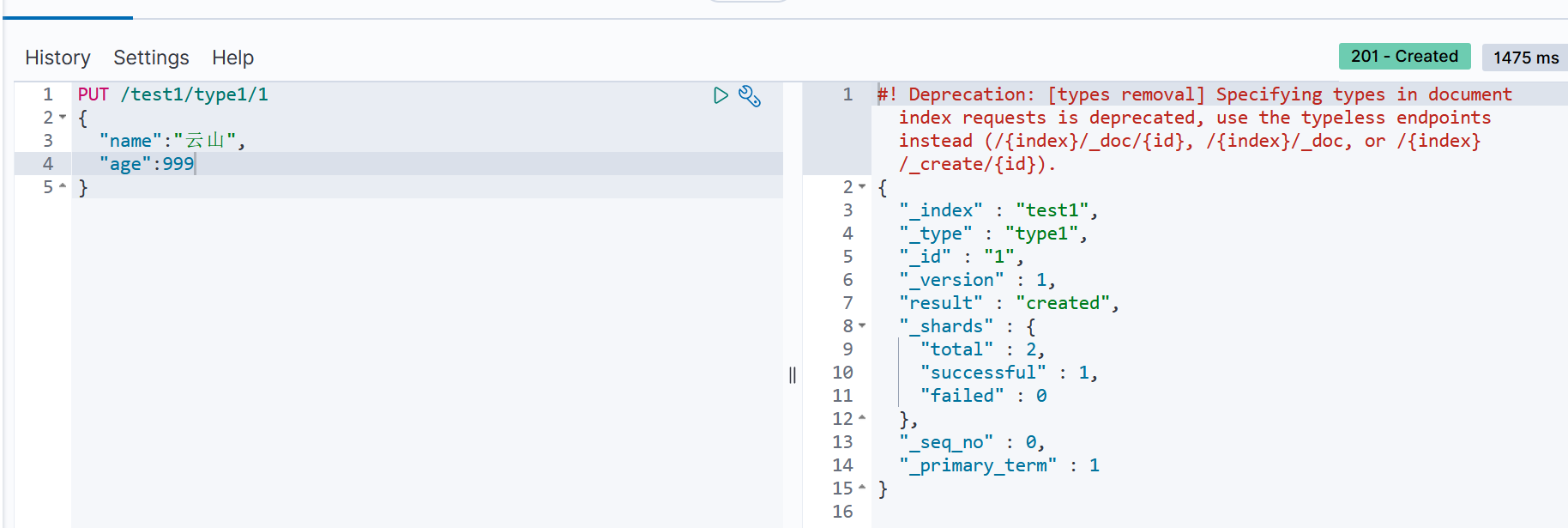
(3)更新数据
PUT /test1/type/1
{
"name": "萧炎"
}
(4)post修改
POST /ceshi/user/1/_update
{
"doc": { //这块需要指定为doc
"name" : "美杜莎"
}
}
完整版脚本
import argparse #
from elasticsearch import Elasticsearch
def main():
parser = argparse.ArgumentParser(description="Process some integers")
parser.add_argument("--host", required=True, help="Elasticsearch地址")
parser.add_argument("--port", required=True, type=int, help="Elasticsearch端口")
parser.add_argument("--size", type=int, default=5, help="文档数量为5")
args = parser.parse_args()
try:
es = Elasticsearch([{'host': args.host, 'port': args.port}])
indices = es.indices.get_alias("*")
index_names = list(indices.keys())
if len(index_names) > 0:
first_index = index_names[0]
print("选择的索引:", first_index)
result = es.search(index=first_index, body={"query": {"match_all": {}}}, size=args.size)
print("查询结果:", result)
else:
print("没有找到索引")
except Exception as e:
print(f"发生错误:{e}")
if __name__ == "__main__":
main()
脚本报错报错解决参考
https://blog.csdn.net/yuan2019035055/article/details/126487852
文章来源:https://blog.csdn.net/Continuejww/article/details/134806756
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!