大数据技术之Storm的安装与配置
大数据技术之Storm的安装与配置
这篇文章深入研究了大数据技术中实时计算系统 Apache Storm 的安装与配置过程。首先,文章介绍了 Apache Storm 在大数据处理中的重要性,强调其在实时数据处理领域的关键作用。随后,详细阐述了如何在系统中进行 Storm 的安装,包括必要的依赖项和配置要点。
在安装步骤中,文章提供了清晰的指导,涵盖了从下载 Storm 到解压缩、配置环境变量以及启动服务的全过程。读者将能够轻松地按照这些步骤完成 Storm 的安装,为后续的实时计算任务做好准备。
进一步,文章讨论了 Storm 的配置过程,包括集群配置、节点设置和相关参数的调整。这些配置方面的详细说明有助于读者根据实际需求进行定制,以达到最佳性能和可靠性。
通过本文,读者将获得在大数据环境中安装和配置 Apache Storm 的实用指南,为利用 Storm 进行实时计算提供了基础。文章以其详实的内容为读者提供了操作步骤和配置细节,使其能够快速而顺利地建立起一个可用的 Storm 环境。
前言知识
Apache Storm作为大数据处理的实时计算系统,在大数据技术领域扮演着重要的角色,其意义主要体现在以下几个方面:
实时数据处理: Storm专注于实时流数据处理,具有低延迟和高吞吐量的特性。它能够在数据流中进行实时计算和分析,使得用户能够即时获取和处理数据,满足了许多场景下对于实时性的需求,如金融交易监控、实时报警系统等。
可伸缩性和高性能: Storm具备良好的横向扩展能力,能够轻松地扩展到大规模集群,以处理大量数据和并发计算任务。其高性能和可伸缩性使得它适用于处理高负载和高并发的实时数据流。
容错性和可靠性: Storm设计具备容错机制,能够在节点故障时保证数据处理的可靠性和连续性。它采用了数据流的可重放性和任务的透明恢复机制,确保即使在出现故障时也能保持数据处理的完整性。
灵活性和可编程性: Storm提供了丰富的编程接口,支持多种编程语言,如Java、Python等,同时也支持开发自定义的数据处理逻辑。这种灵活性使得开发人员能够根据实际需求进行定制化开发,适应不同的应用场景。
生态系统和整合性: Storm作为开源项目,拥有丰富的生态系统,与其他大数据技术(如Hadoop、Kafka等)良好整合,可以作为一个实时计算引擎与其他系统配合使用,构建更全面的大数据处理解决方案。
总体而言,Storm在实时数据处理领域的重要性体现在其能够高效地处理实时数据流、保证计算的低延迟性和高可靠性、支持横向扩展、灵活定制等方面,为大数据处理提供了强大的实时计算能力。
1.准备阶段
1.1 虚拟机
2台虚拟机,ip地址分别为192.168.95.20、192.168.95.21。第1台作为主节点;具体ip地址和普通用户名视自己情况对应处理。(ip地址根据自己实际情况更改!)
本文章所用的全部资料都在网盘,网盘链接:
链接:https://pan.baidu.com/s/1MrzDAGUxqduU0HFNuTebdA?pwd=1234
需要的小伙伴可以自行下载。
master 192.168.95.20
node1 192.168.95.22
node2 192.168.95.23
1.1创建普通用户
在所有节点上进行。
都创建名为iot(具体视自己情况)的普通用户,并以iot登录。
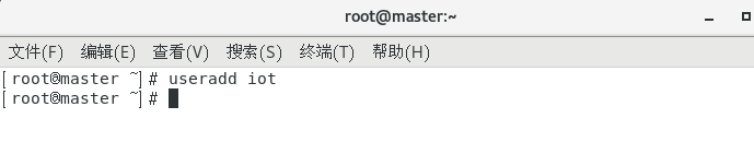
创建用户iot
useradd iot

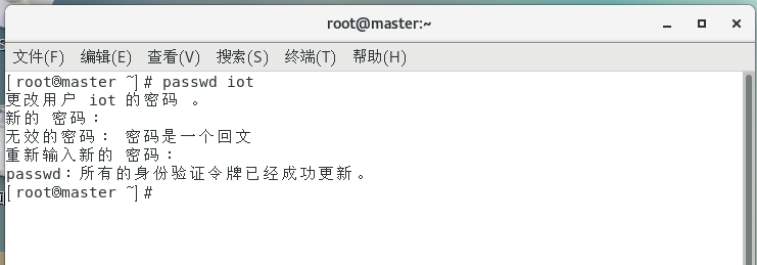
各节点分别设置iot用户密码
passwd iot

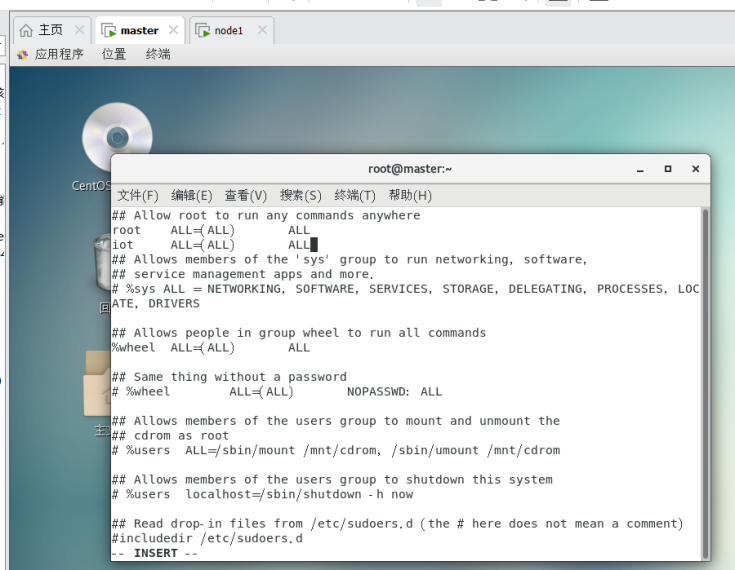
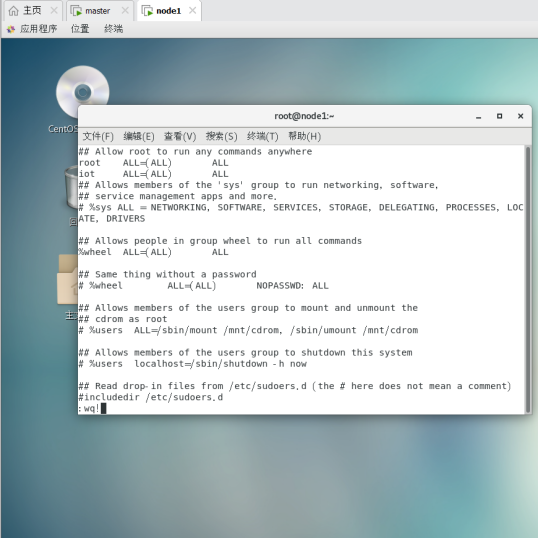
在master和node1节点分别设置iot用户权限
chmod -v u+w /etc/sudoers
vi /etc/sudoers
添加iot ALL=(ALL) ALL
然后wq!保存退出。
设置完成后,reboot重启,选择iot用户登录。
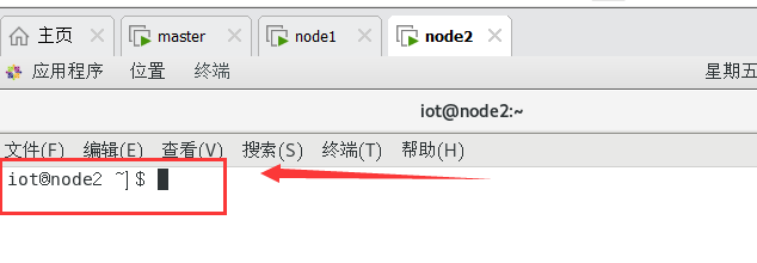
Node2
1.2创建目录
在所有节点上进行。
$mkdir -p /opt/softwares //用于存放软件包
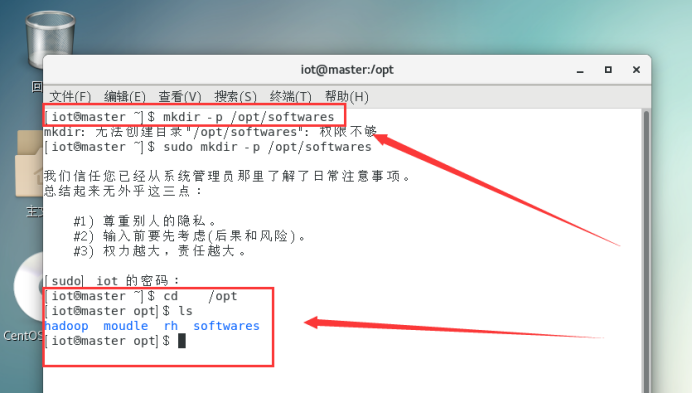
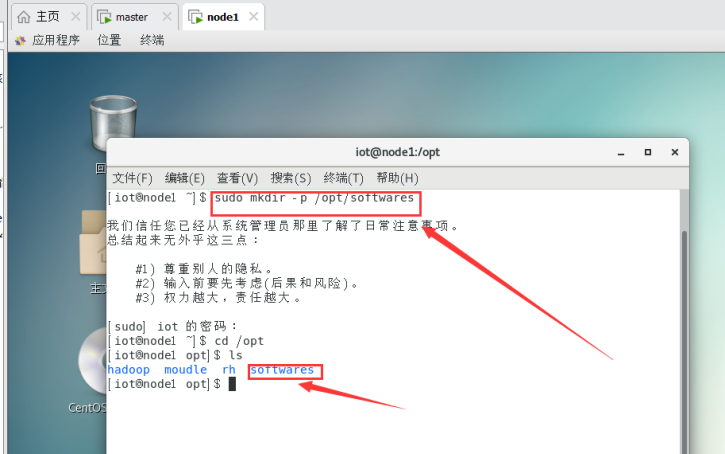
$mkdir -p /opt/modules //用于存放解压文件夹

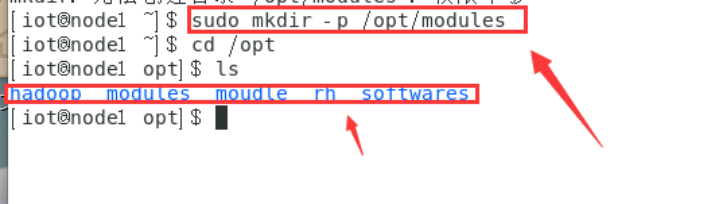
将安装包上传到softwares目录
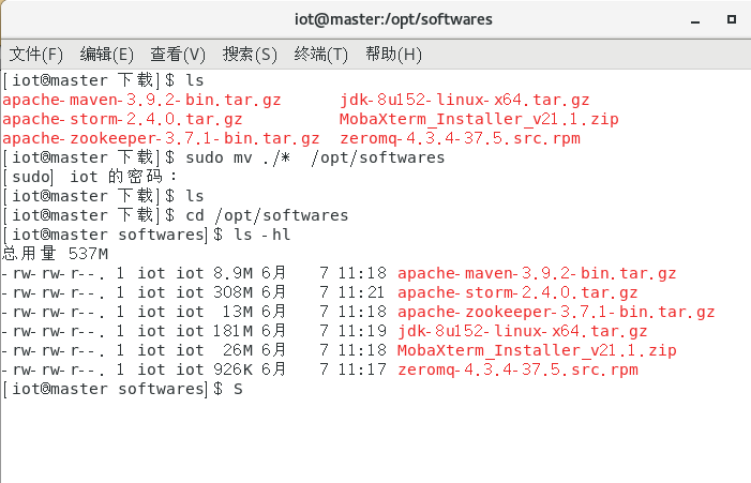
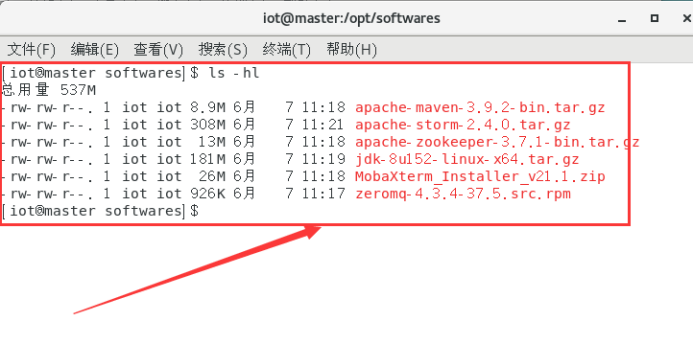
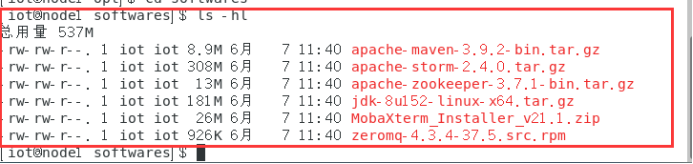
将master节点下的/opt/softwares文件分发给node1节点
sudo scp -r /opt/softwares iot@192.168.95.21:/opt
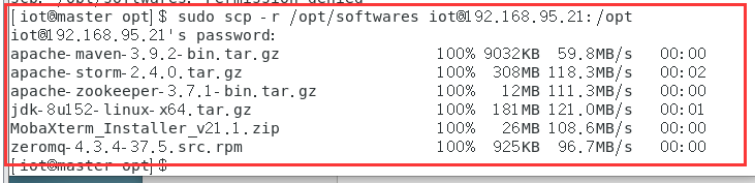
Node1节点查看传输文件
cd /opt
ls
cd softwares
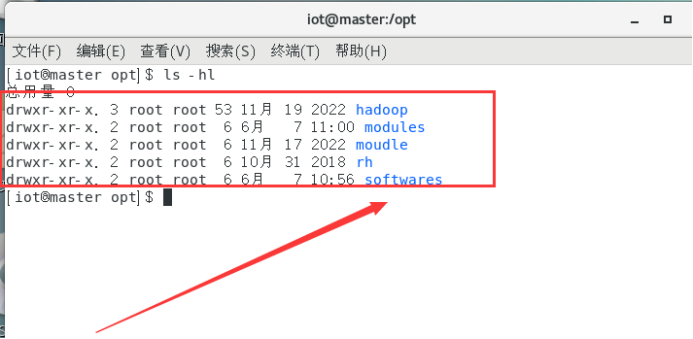
ls -hl
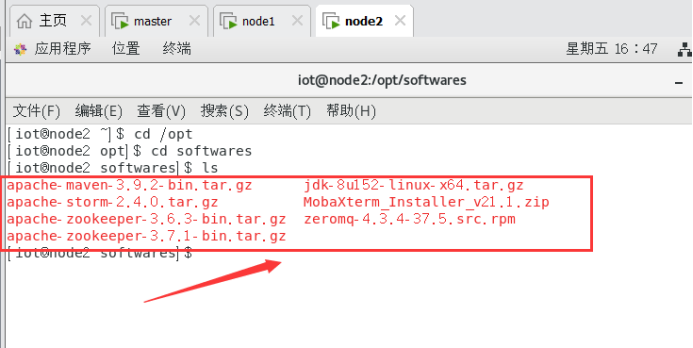
node2
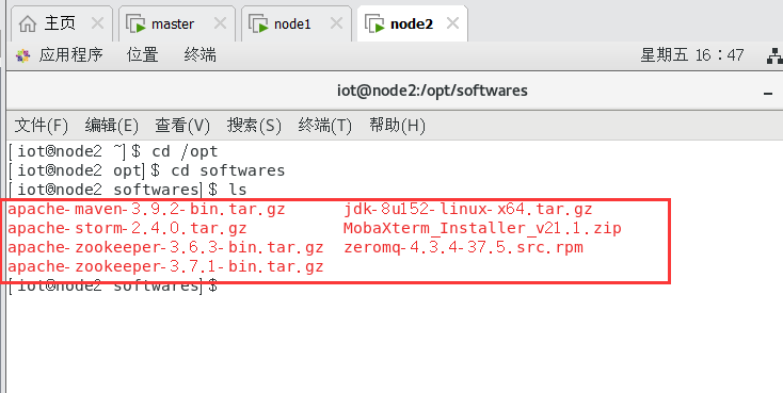
1.4将已下载软件放置在/opt/softwares目录
放在主节点。后面如要放在从节点,请遵照。
2.安装依赖包及软件
2.1安装依赖包
在所有节点上进行。
$ sudo yum -y install gcc-c++ uuid* libtool libuuid libuuid-devel
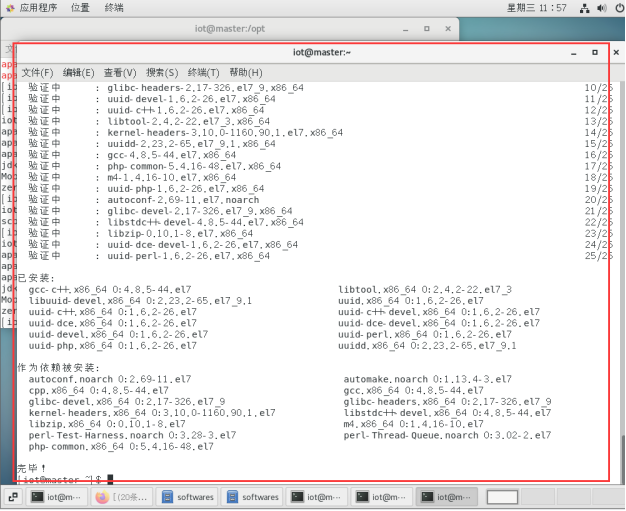
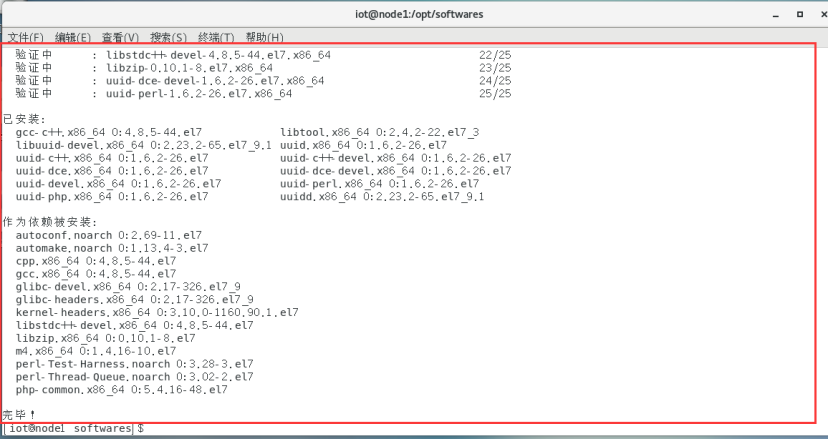
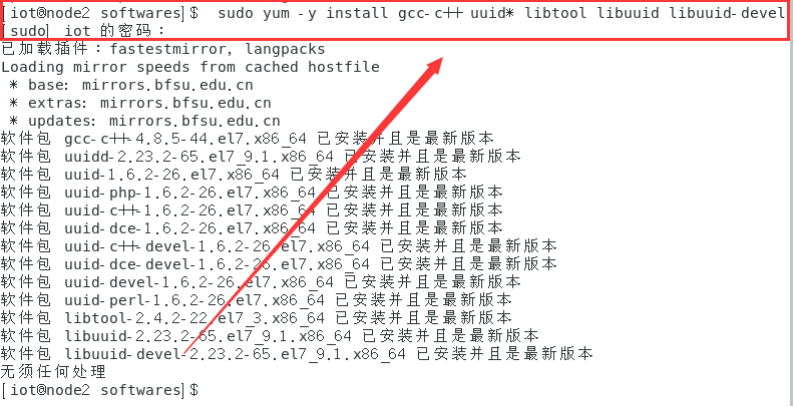
2.2安装并配置JDK
2.2.1安装JDK
2.2.1.1.1在主节点上解压
此步骤如果该前面章节安装过,已忽略。
2.2.1.2检查Java是否安装成功
Master里面查看java:
java -version

Node1里面查看java:
java -version

Node2里面查看java:
Java -version

3.安装Zookeeper
以下步骤如无特殊说明,请在主节点上运行。
3.1解压安装包
$tar -zxvf apache-zookeeper-3.6.3-bin.tar.gz -C /opt/modules
3.2配置Zookeeper
3.2.1编辑主节点配置文件
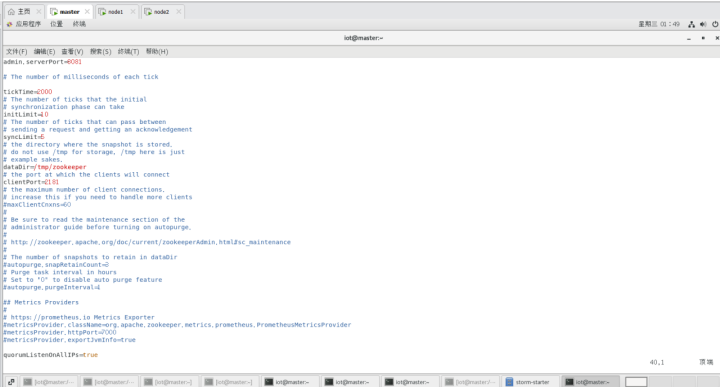
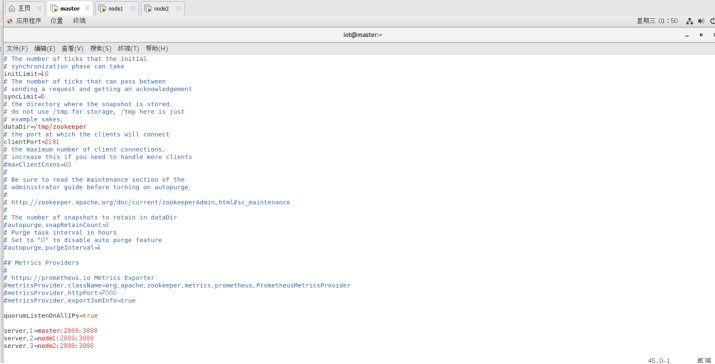
$vi /opt/modules/apache-zookeeper-3.6.3-bin/conf/zoo.cfg

在配置文件的最后添加以下内容:
server.1=192.168.95.20:2888:3888
server.2=192.168.95.22:2888:3888
server.3=192.168.95.23:2888:3888
3.2.1myid文件
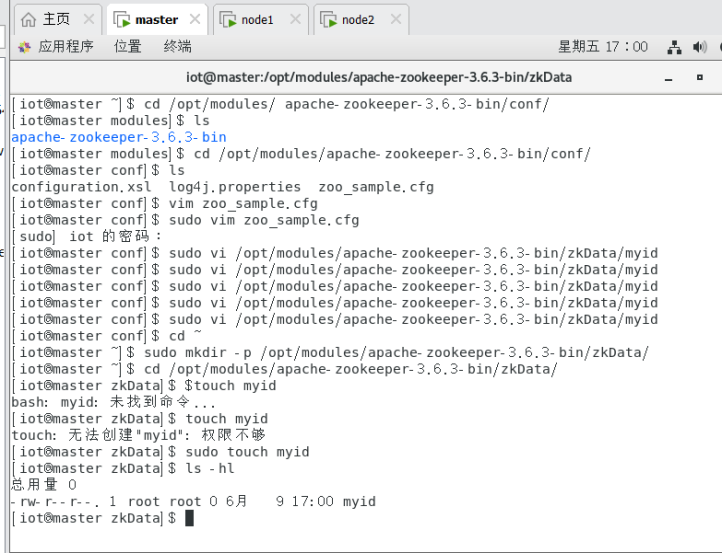
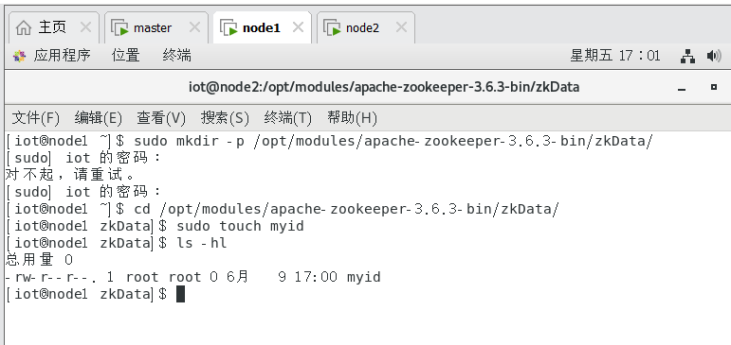
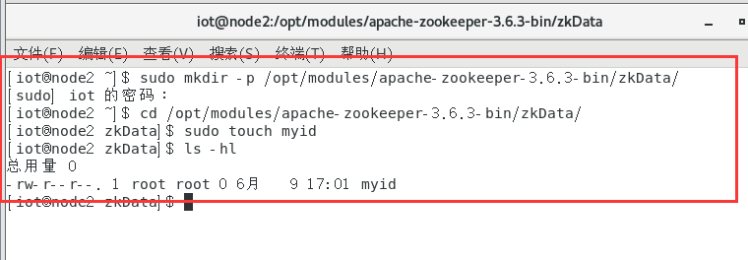
3.2.1.1创建zkData目录及myid文件
在所有节点上进行。
$mkdir -p /opt/modules/apache-zookeeper-3.6.3-bin/zkData/
$cd /opt/modules/apache-zookeeper-3.6.3-bin/zkData/
$touch myid
Master:
Node1:
Node2:
3.2.1.2第一个节点
在第一个节点进行。
$vi /opt/modules/apache-zookeeper-3.6.3-bin/zkData/myid
键入:
1
3.2.1.3第二个节点
在第二个节点进行。
$vi /opt/modules/apache-zookeeper-3.6.3-bin/zkData/myid
键入:
2
3.2.1.4第三个节点
在第三节点进行。
$vi /opt/modules/apache-zookeeper-3.6.3-bin/zkData/myid
键入:
3
3.3配置Zookeeper环境变量
在所有节点上进行。
$sudo vi /etc/profile
做如下修改:
export ZOOKEEPER_HOME=/opt/modules/apache-zookeeper-3.6.3-bin
export PATH=$PATH:$ZOOKEEPER_HOME/bin
master:

Node1:
Node2

4.安装ZeroMQ
在所有节点进行。
4.1解压缩包
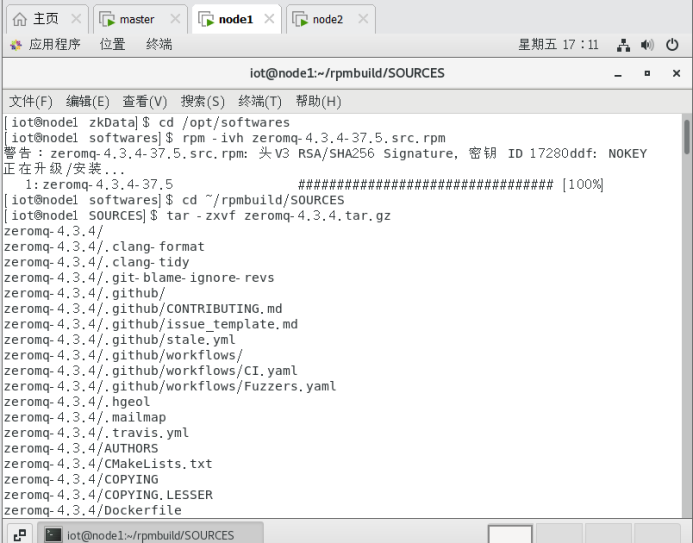
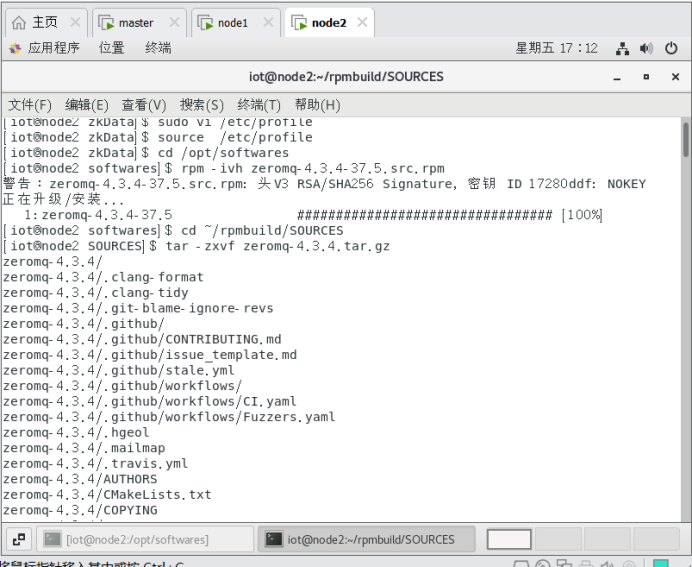
cd /opt/softwares
rpm -ivh zeromq-4.3.4-37.5.src.rpm
cd ~/rpmbuild/SOURCES
tar -zxvf zeromq-4.3.4.tar.gz
4.2编译并安装
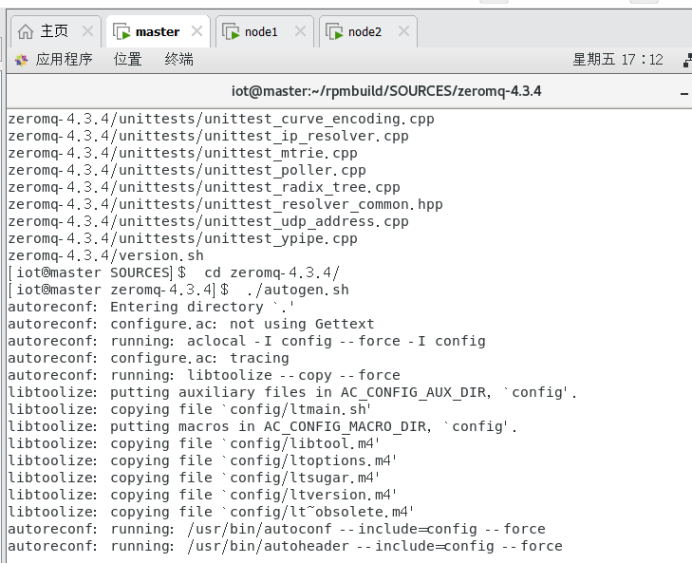
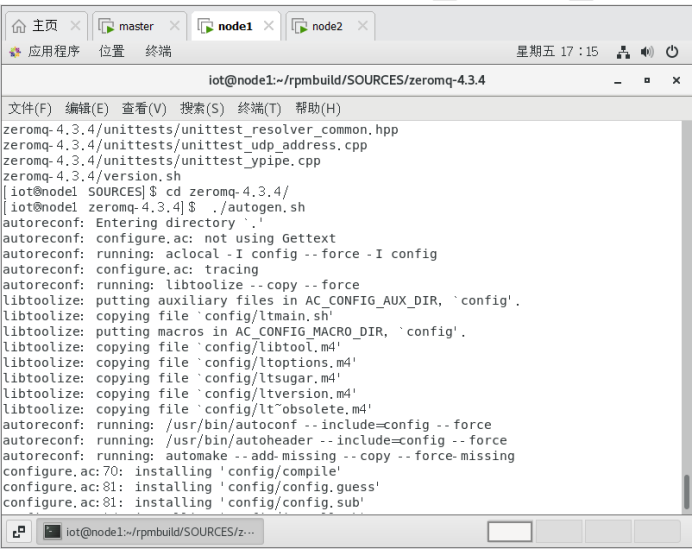
$ cd zeromq-4.3.4/
$ ./autogen.sh
$./configure
$make
$sudo make install
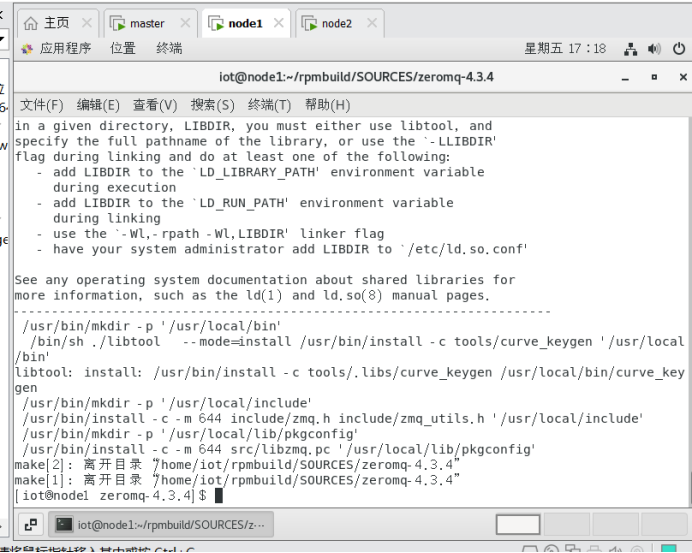
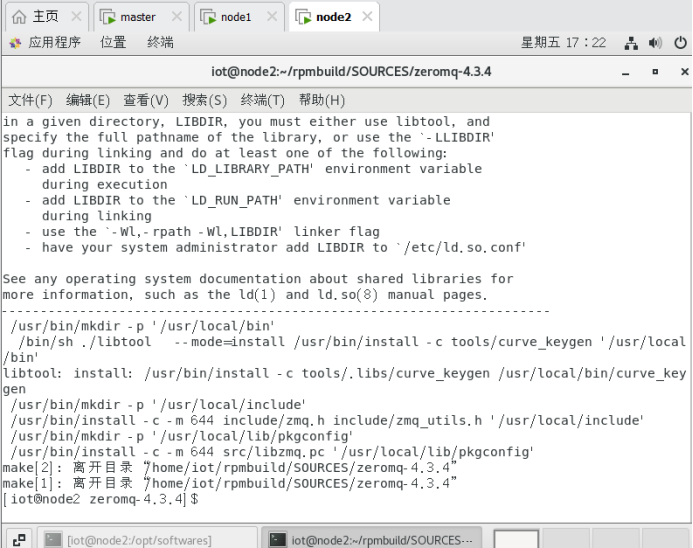
4.3更新动态链接库
$sudo vi /etc/ld.so.conf
在最后面追加/usr/local/lib/ //该目录存放了JZMQ和ZeroMQ的库文件
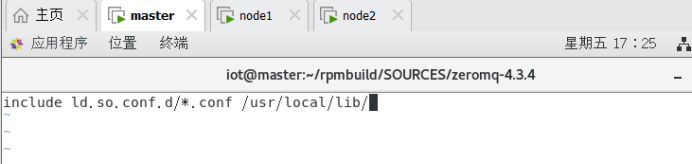
sudo ldconfig //将库路径加载到内存

参考:https://blog.51cto.com/u_2650279/6143472 ;https://www.656463.com/article/UbuntuxStormazdjfbs_3
5.安装JZMQ
在所有节点进行。
5.1安装git
$ sudo yum install -y git
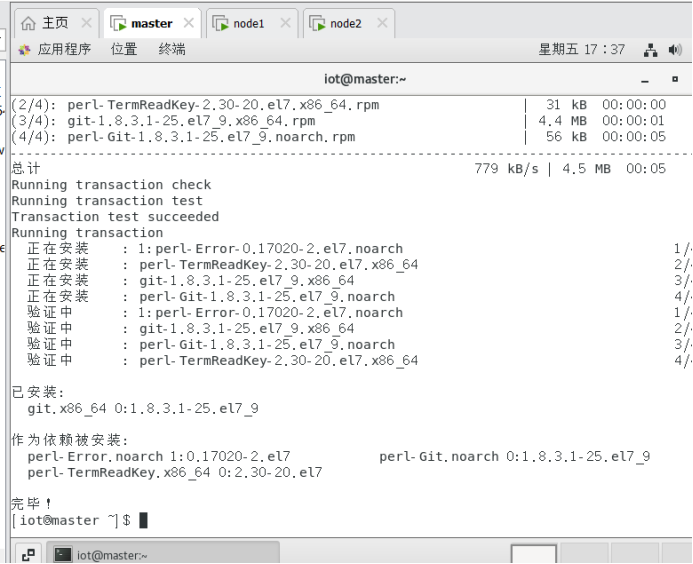
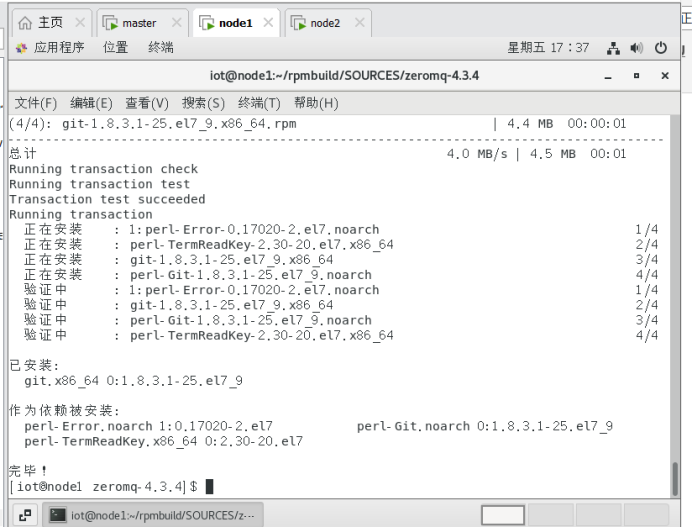
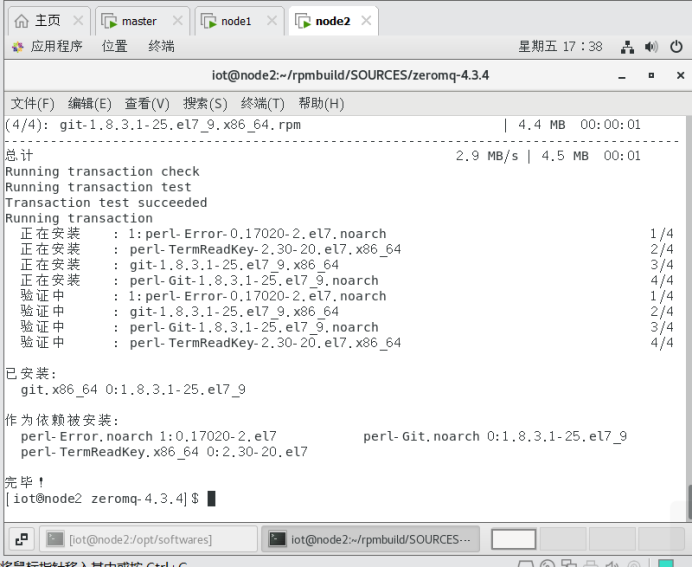
5.2下载JZMQ代码
$cd /opt/softwares
$git clone https://github.com/zeromq/jzmq.git
注:如果出现fatal: unable to access 'https://github.com/zeromq/jzmq.git/': Failed connect to github.com:443; Connection refused问题,可使用以下命令解决:(参考:https://blog.csdn.net/weixin_44442186/article/details/124979085)
取消全局代理:
git config --global --unset http.proxy
git config --global --unset https.proxy
添加全局代理:
git config --global http.proxy
git config --global https.proxy
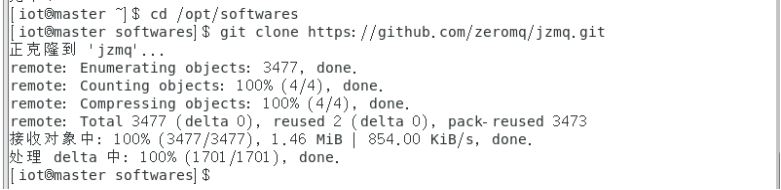
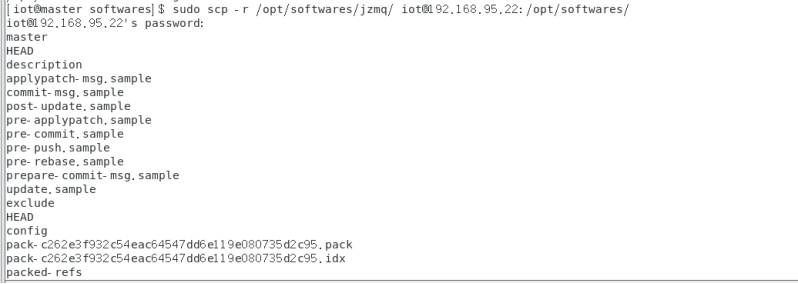
将下载好的JZMQ代码通过scp传到node1和node2节点。


5.3编译并安装
直接复制粘贴到终端:
$cd jzmq
$cd jzmq-jni
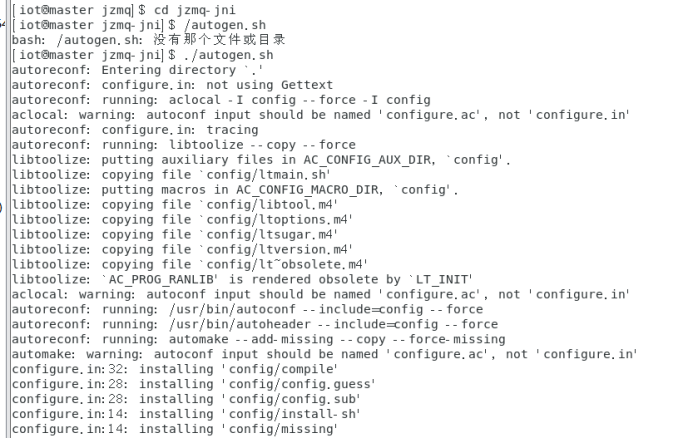
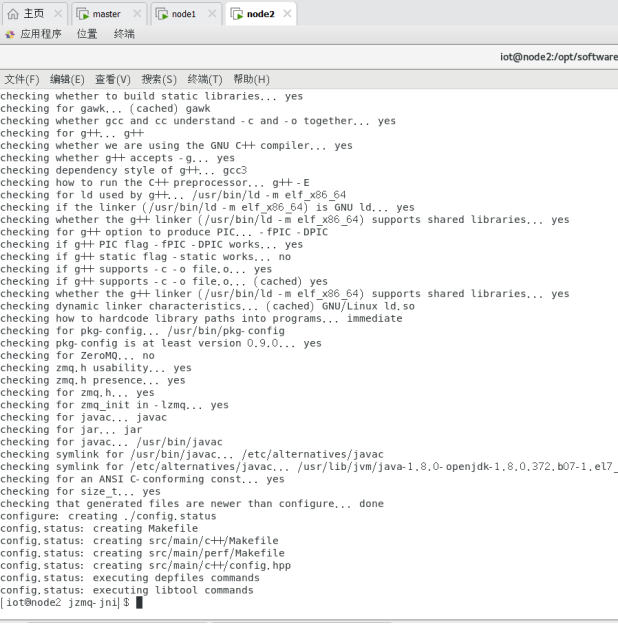
$./autogen.sh
$./configure
$make
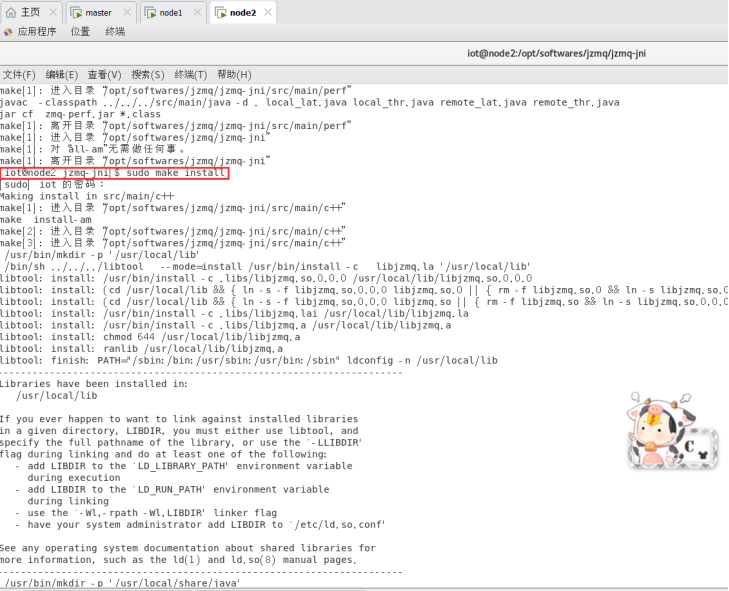
$sudo make install
Master节点:
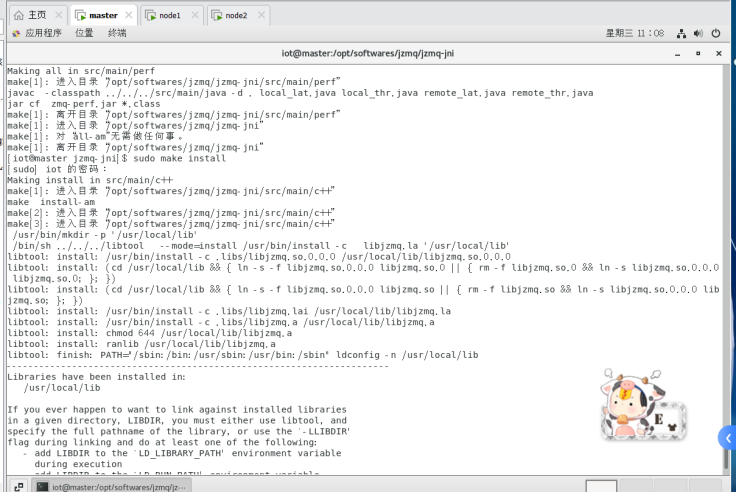
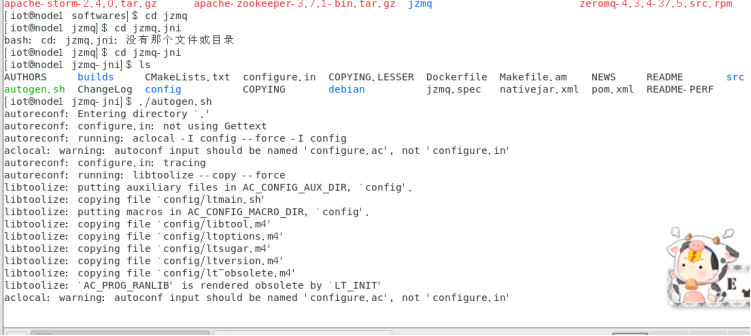
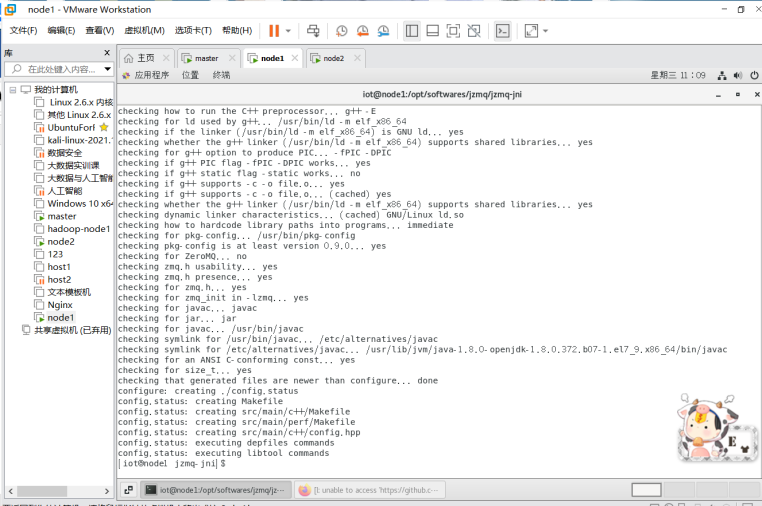
Node1节点:
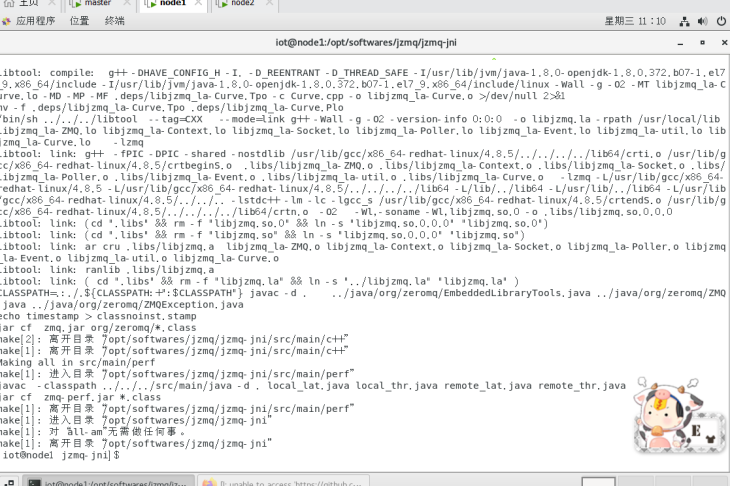
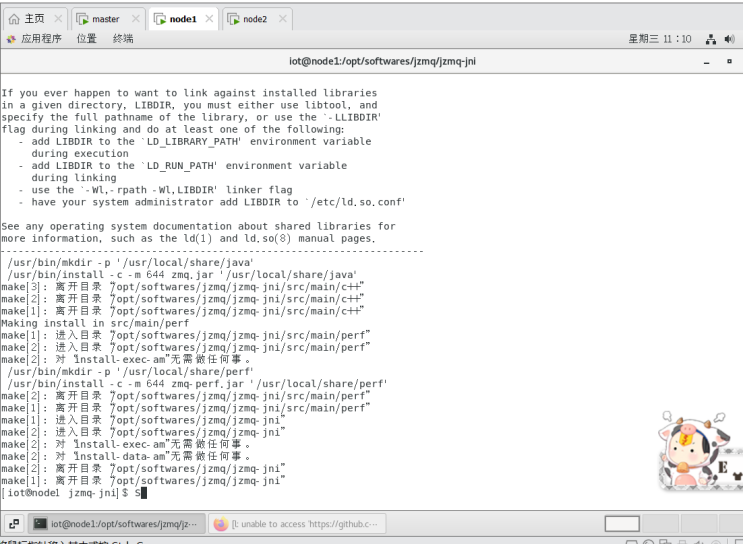
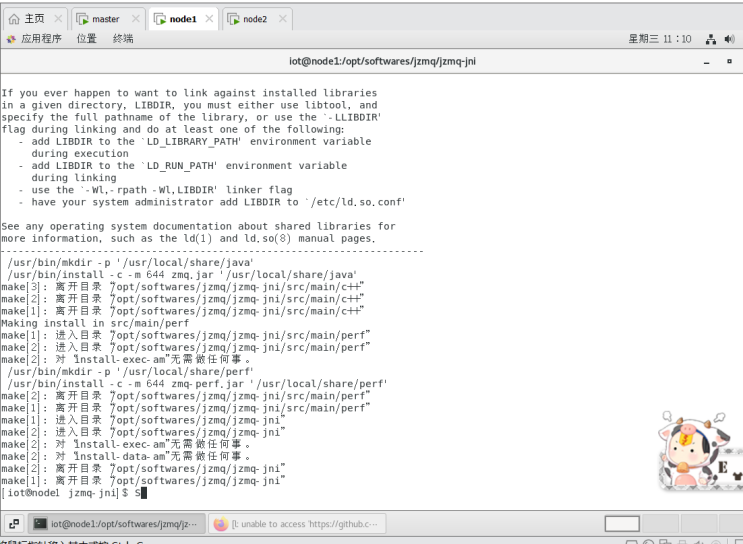
Node2节点:
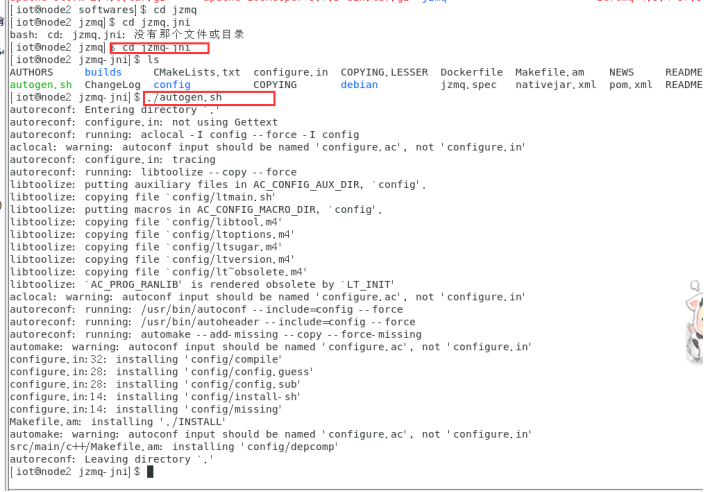
6.安装Storm
以下步骤如无特殊说明,请在主节点上运行。
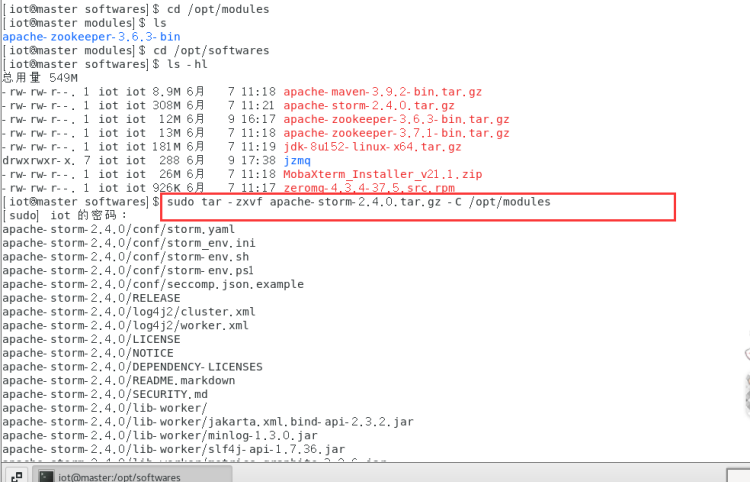
6.1解压缩Storm安装包
解压apache-storm-2.4.0.tar.gz到/opt/modules目录(若没有此目录则创建)
$ tar -zxvf apache-storm-2.4.0.tar.gz -C /opt/modules
6.2设置Storm配置文件
$vi /opt/modules/apache-storm-2.4.0/conf/storm.yaml
做如下替换:
6.2.1替换1
#storm.zookeeper.servers:
- "server1"
- "server2"
替换为:
storm.zookeeper.servers:
- "192.168.95.20"
- "192.168.95.22"
- "192.168.95.23"
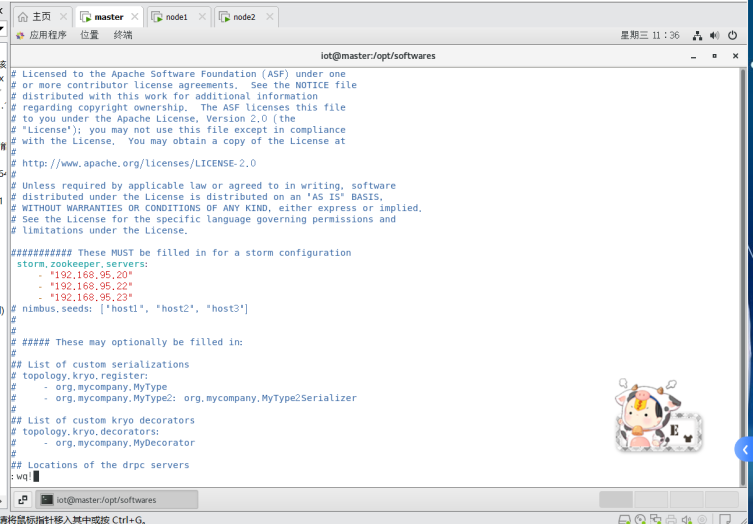
6.2.2替换2
nimbus.seeds: ["host1", "host2", "host3"]
替换为:
nimbus.seeds: ["192.168.109.131", "192.168.109.132", "192.168.109.133"]
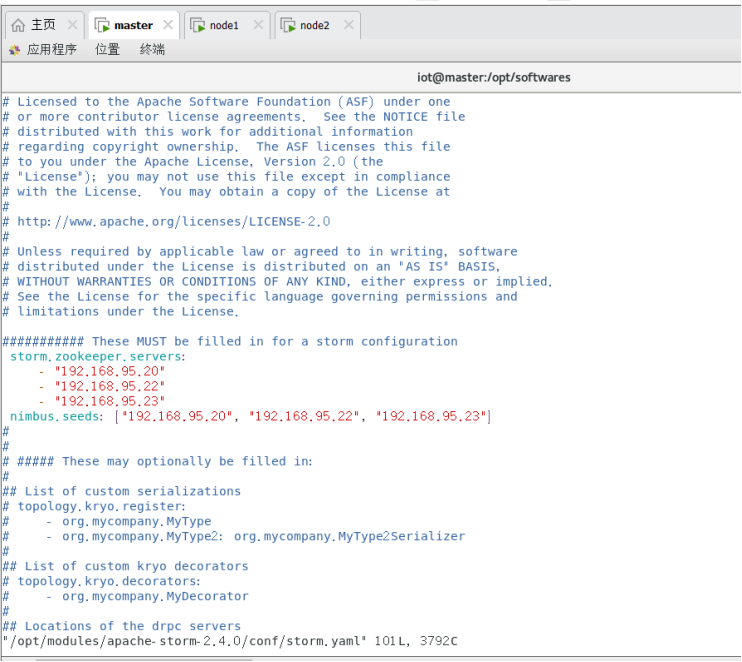
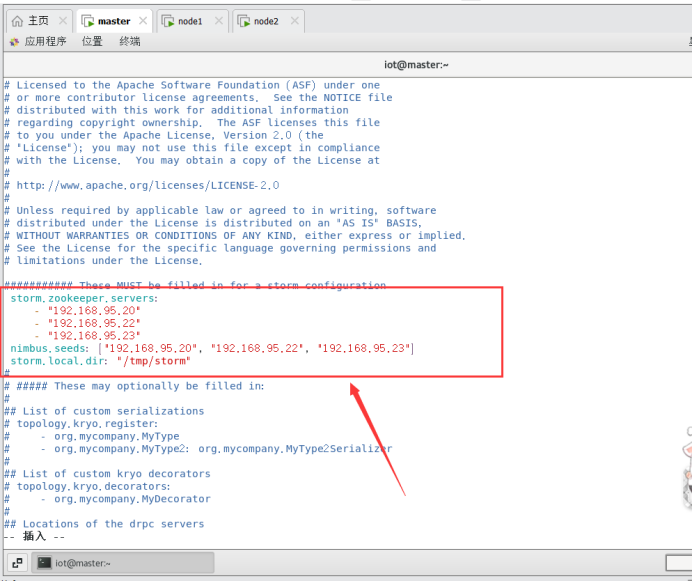
6.2.3设置临时路径
在所有节点进行。
storm.local.dir: "/tmp/storm" //前提是已经创建了此临时路径
参考:https://blog.csdn.net/zjjcchina/article/details/120650514
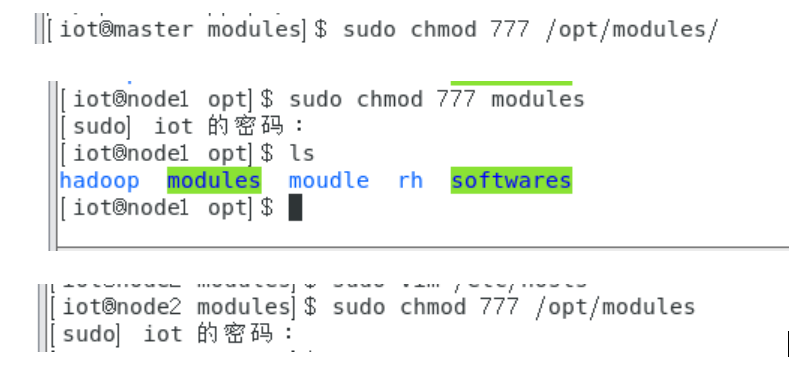
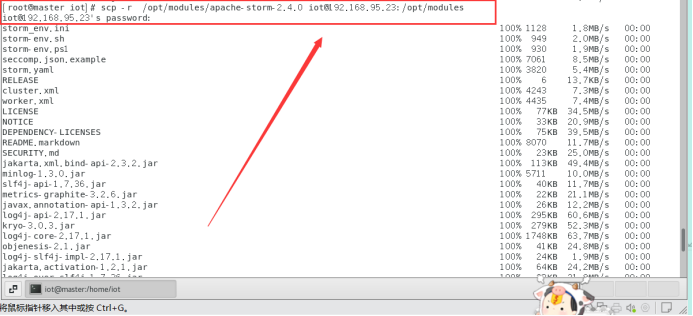
6.3复制到从节点
Sudo chmod 777 /opt/modules
$scp -r /opt/modules/apache-storm-2.4.0/ iot@192.168.95.22: /opt/modules/
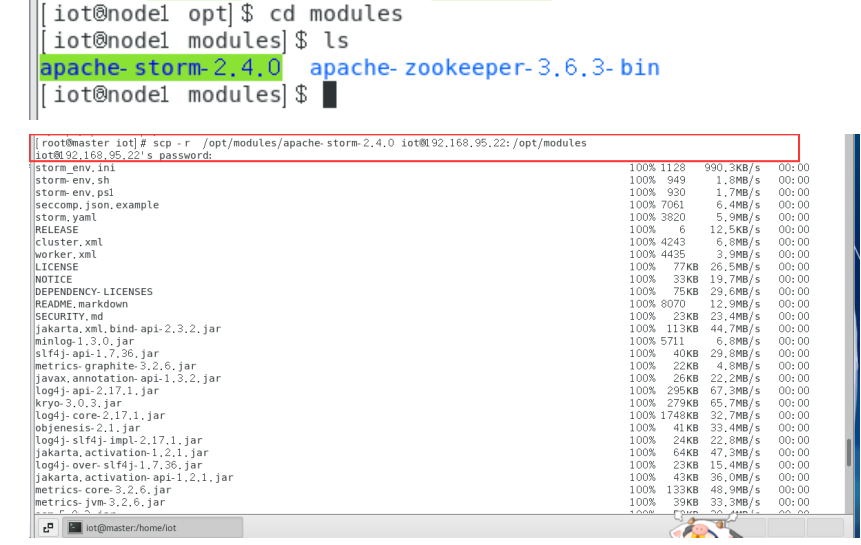
$scp -r /opt/modules/apache-storm-2.4.0/ iot@192.168.95.23: /opt/modules/

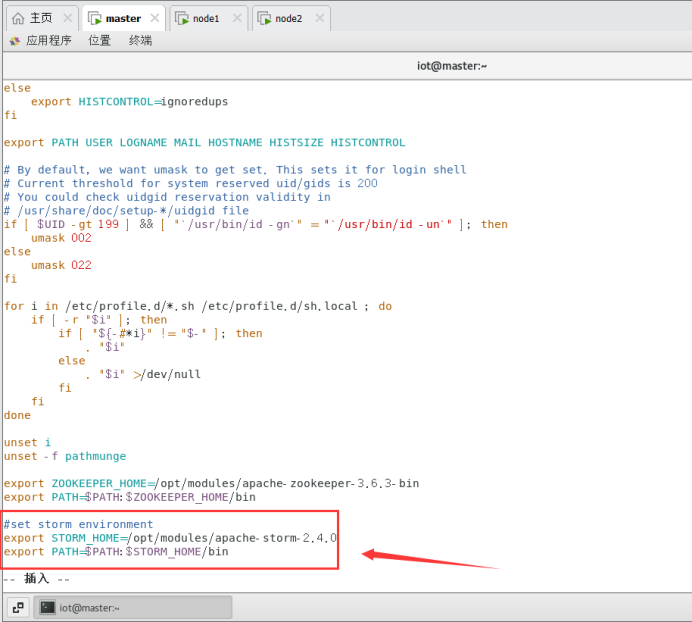
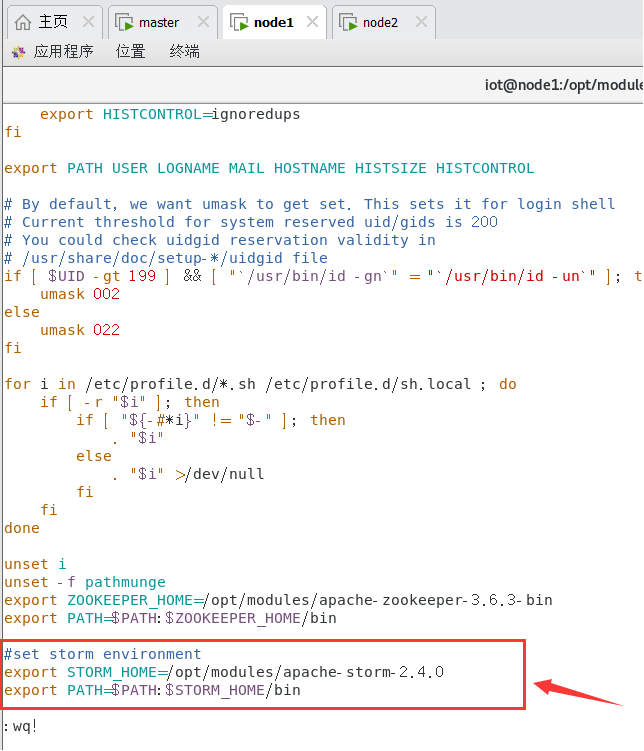
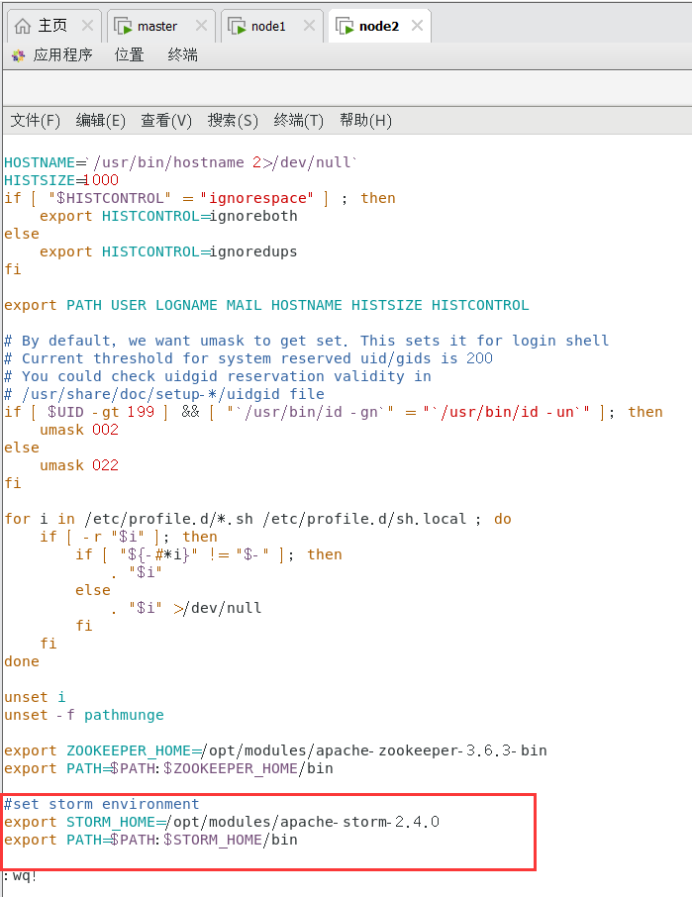
6.4配置Storm环境变量
在所有节点上运行。
$sudo vi /etc/profile
做如下修改:
#set storm environment
export STORM_HOME=/opt/modules/apache-storm-2.4.0
export PATH=$PATH:$STORM_HOME/bin
6.5使环境变量生效
在所有节点上运行。
$source /etc/profile


7启动Zookeeper
此步需要在启动Storm之前执行。
在所有节点上执行。
确保已经添加java环境。
sudo vim /etc/profile
cd /opt/modules/apache-zookeeper-3.6.3-bin/bin
udo vi ./zkServer.sh

加入
export JAVA_HOME=/usr/lib/jvm/java-openjdk
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin

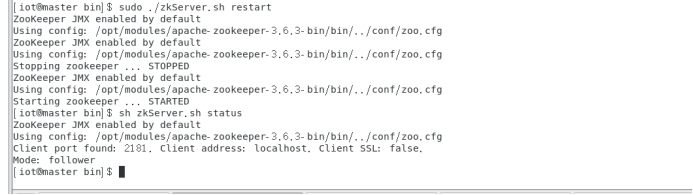
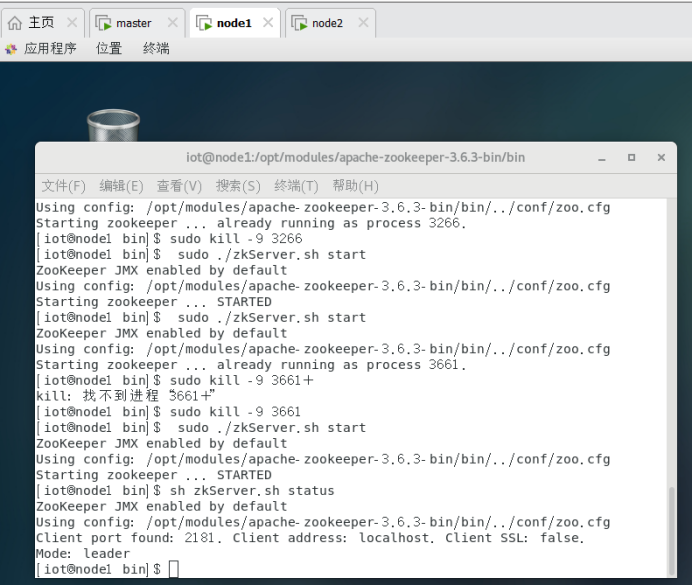
$cd /opt/modules/apache-zookeeper-3.6.3-bin/bin
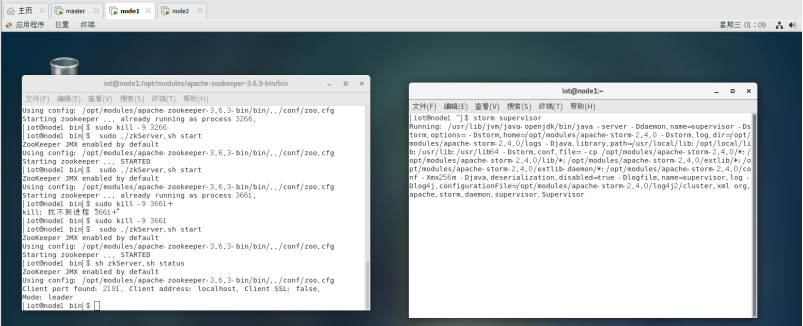
$./zkServer.sh start
执行结果及进程如下:

7.启动Storm
建议使用MobaXterm远程登录客户端,因为同一个节点,比如192.168.109.131需要启动多个服务,且各个服务启动后就不会返回shell界面。这时就可以使用MobaXterm较方便的打开多个终端启动其他服务。
8.1主节点
8.1.1启动nimbus进程
$storm nimbus
8.1.2启动UI
$vi /opt/modules/apache-storm-2.4.0/conf/storm.yaml
storm ui的默认端口为8080, 而该端口被其他进程占用(如hadoop等),我们将其修改为其它端口。
加入:
ui.port: 19999(注意冒号后面一定要有空格)
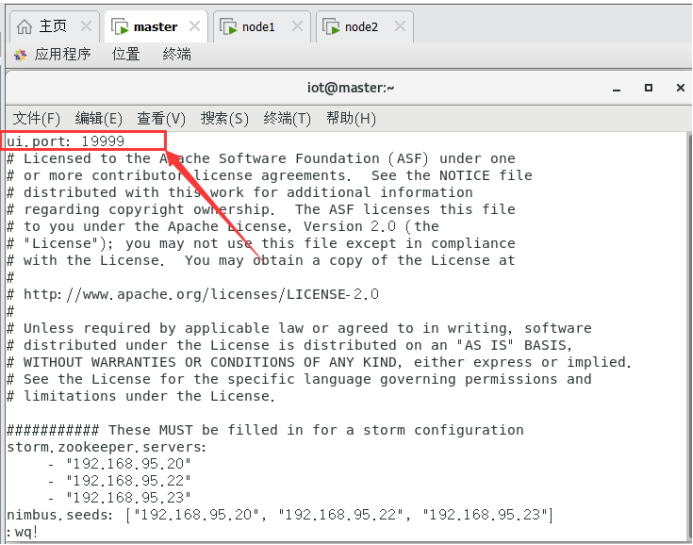
$storm ui

8.1.3启动logviewer
$storm logviewer
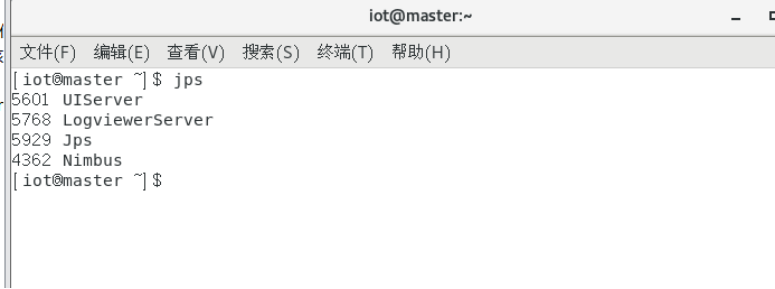
8.1.4主节点执行结果及进程
直接jps查看进程:
jps
8.2从节点
8.2.1启动supervisor
$storm supervisor
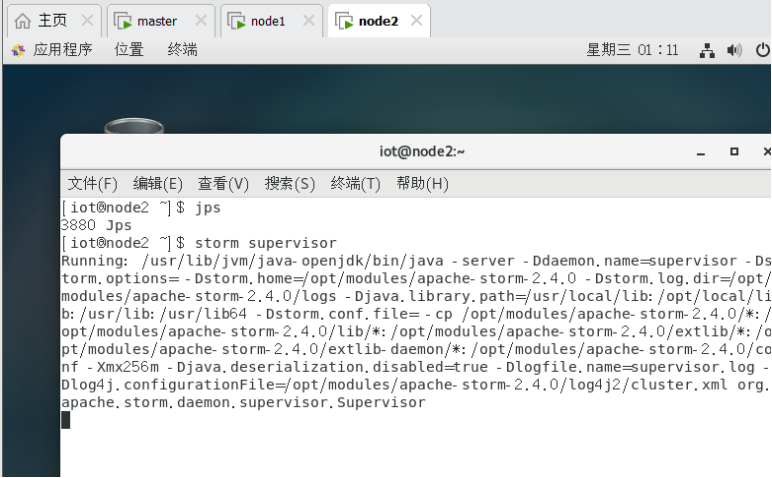
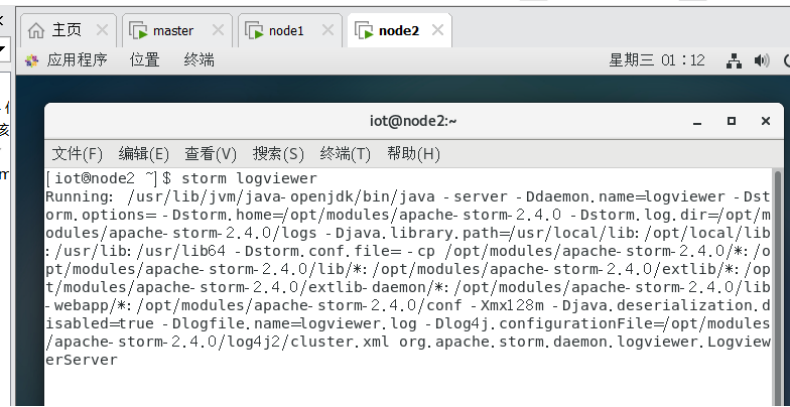
8.2.2启动logviewer
.$storm logviewer
9Storm应用实践
9.1使用Maven管理storm-starter
在主节点进行。
9.1.1安装Maven
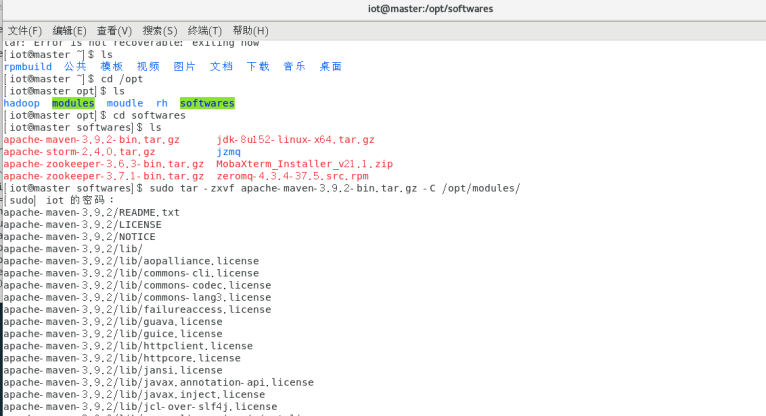
9.1.1.1解压
$tar -zxvf apache-maven-3.9.2-bin.tar.gz -C /opt/modules/
9.1.2配置Maven环境变量
9.1.2.1设置Maven环境变量
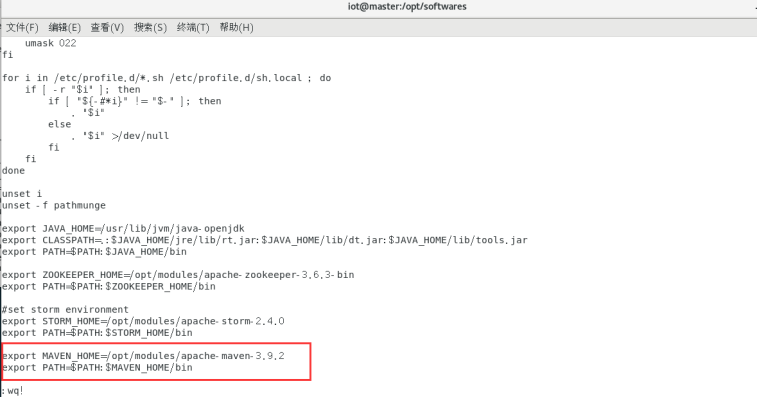
$sudo vi /etc/profile
export MAVEN_HOME=/opt/modules/apache-maven-3.9.2
export PATH=$PATH:$MAVEN_HOME/bin
9.1.2.2使环境变量生效
$source /etc/profile

9.1.2.3测试Maven是否安装成功
mvn -version

9.1.3使用Maven管理示例工程storm-starter
9.1.3.1修改Maven的配置文件
$cd /opt/modules/apache-maven-3.9.2/conf
$vi settings.xml
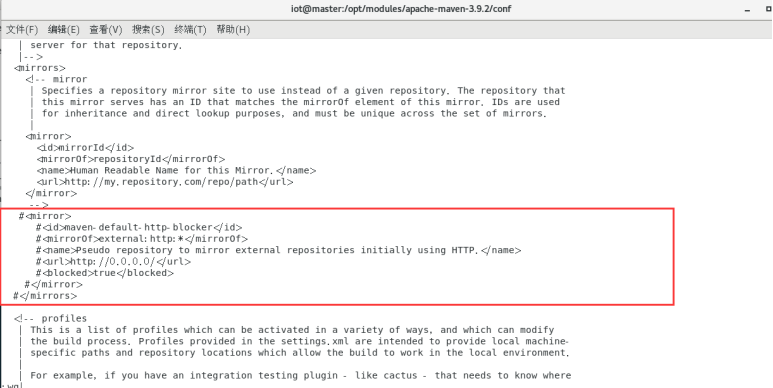
对以下语句进行注释:
<mirror>
<id>maven-default-http-blocker</id>
<mirrorOf>external:http:*</mirrorOf>
<name>Pseudo repository to mirror external repositories initially using HTTP.</name>
<url>http://0.0.0.0/</url>
<blocked>true</blocked>
</mirror>
9.1.3.2进入storm-starter目录
$cd /opt/modules/apache-storm-2.4.0/examples/storm-starter

9.1.3.3编辑pom.xml文件
$vi pom.xml
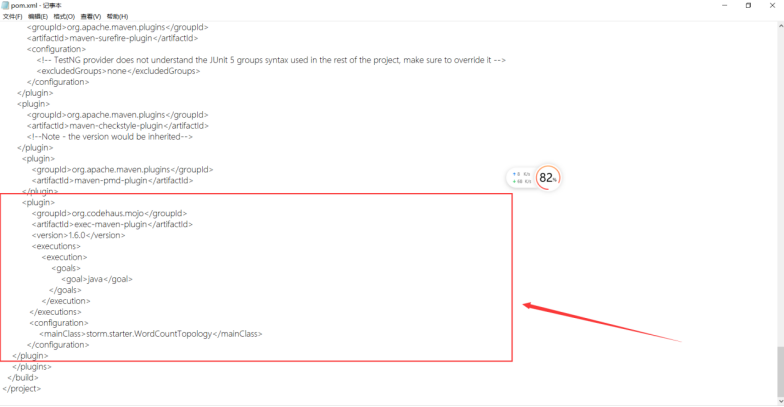
在和标签中添加:
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>exec-maven-plugin</artifactId>
<version>1.6.0</version>
<executions>
<execution>
<goals>
<goal>java</goal>
</goals>
</execution>
</executions>
<configuration>
<mainClass>storm.starter.WordCountTopology</mainClass>
</configuration>
</plugin>
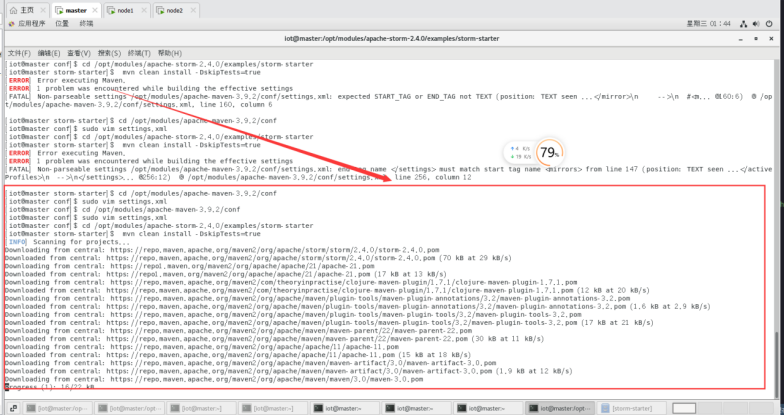
9.1.3.4编译storm-starter工程
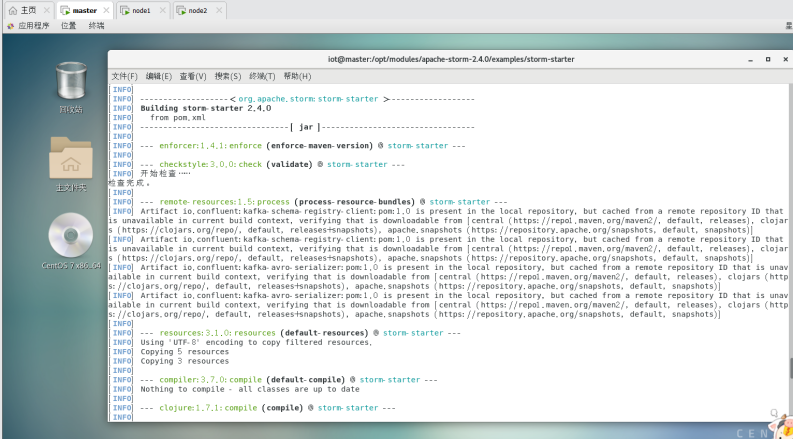
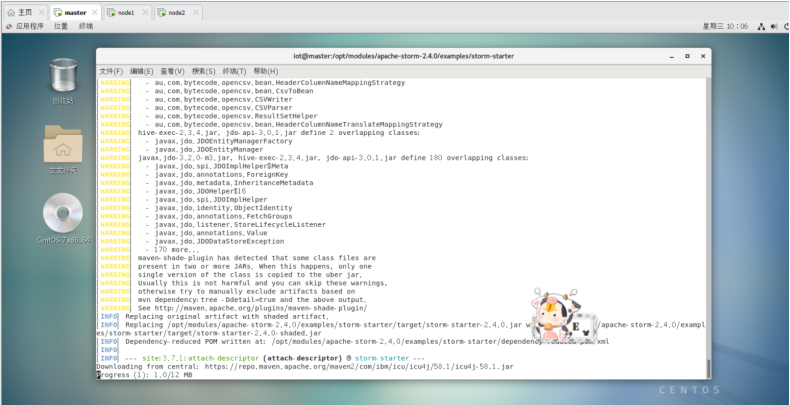
$ mvn clean install -DskipTests=true
此过程会下载大量文件,请耐心等待……
9.1.3.5打包成jar
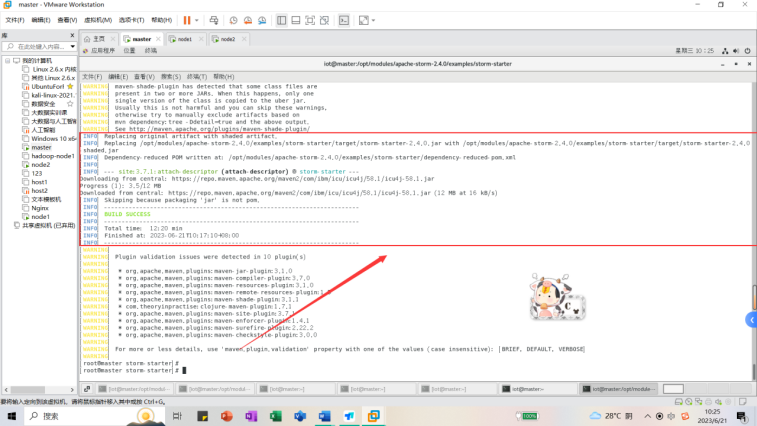
$ mvn package
9.2提交运行
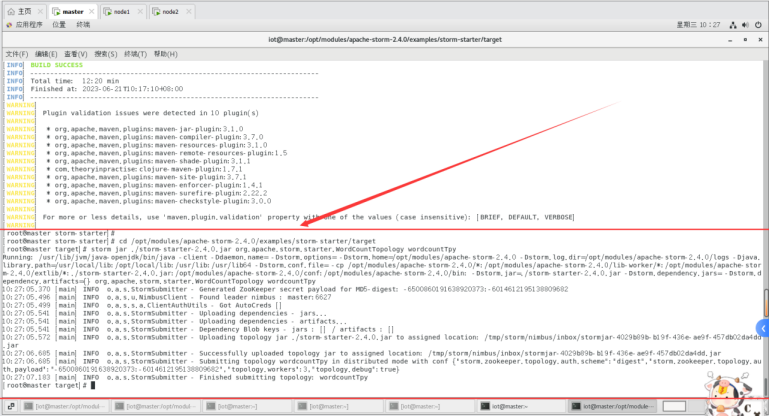
$cd /opt/modules/apache-storm-2.4.0/examples/storm-starter/target
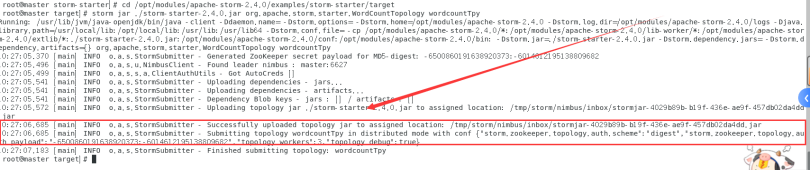
$storm jar ./storm-starter-2.4.0.jar org.apache.storm.starter.WordCountTopology wordcountTpy
//参考:https://blog.csdn.net/lt1693016523/article/details/82662071
成功提交运行jar包
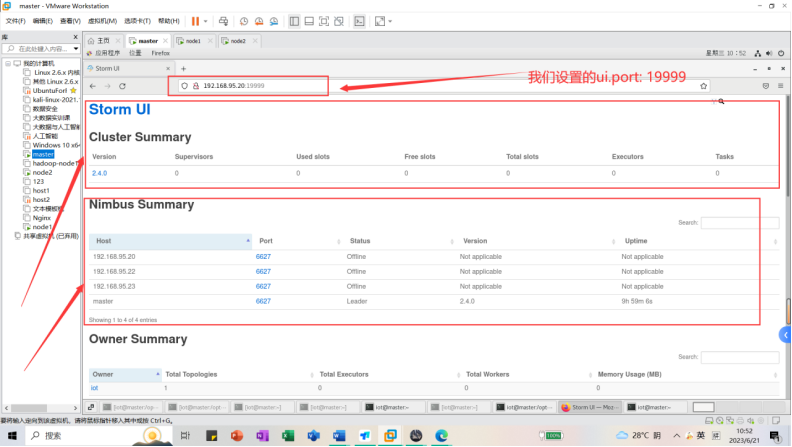
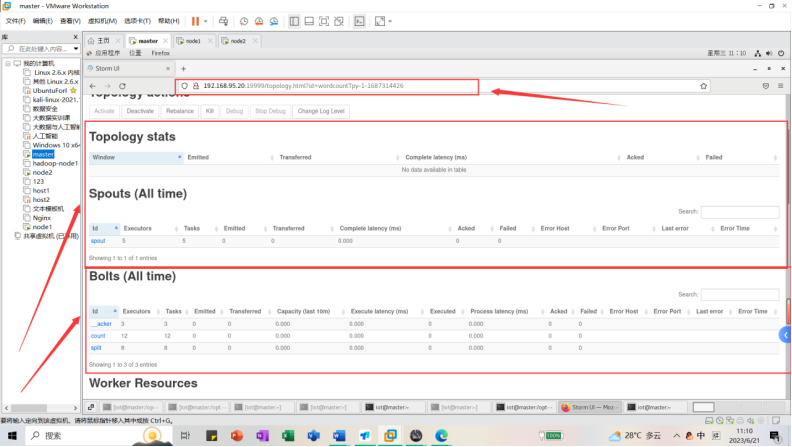
9.2.1UI监控
任务提交之后就可以监控。在浏览器中输入:
192.168.95.20:19999 //ip地址视自己情况改变
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!