2.2 数据预处理
注意!!!
本博客仅用于本人学习笔记作用
资料来源:https://zh-v2.d2l.ai/chapter_introduction/index.html
数据预处理
读取数据集
import os
import pandas as pd
os.makedirs(os.path.join('.', 'data'), exist_ok=True)
data_file = os.path.join('.', 'data', 'house_tiny.csv')
with open(data_file, 'w') as f:
f.write('NumRooms,Alley,Price\n') # 列名
f.write('NA,Pave,127500\n') # 每行表示一个数据样本
f.write('2,NA,106000\n')
f.write('4,NA,178100\n')
f.write('NA,NA,140000\n')
data = pd.read_csv(data_file)
print(data)
NumRooms Alley Price
0 NaN Pave 127500
1 2.0 NaN 106000
2 4.0 NaN 178100
3 NaN NaN 140000
处理缺失值
“NaN”项代表缺失值。 为了处理缺失的数据,典型的方法包括插值法和删除法, 其中插值法用一个替代值弥补缺失值,而删除法则直接忽略缺失值。 在这里,我们将考虑插值法。
通过位置索引iloc,我们将data分成inputs和outputs, 其中前者为data的前两列,而后者为data的最后一列。 对于inputs中缺少的数值,我们用同一列的均值替换“NaN”项。
巷子类型
“巷子类型”(“Alley”)通常是指房地产数据中的一个特征,用于描述房屋所在的巷子或背街的类型。在房地产领域,房屋的位置和周围环境是一个重要的因素,而巷子类型是其中之一。
巷子类型通常可以包含以下几种类别:
-
“Pave”:表示巷子是铺设了道路或人行道的,通常是水泥或沥青路面,类似于一条小巷。
-
“Grvl”:表示巷子是用碎石或砾石铺设的,通常没有硬化的路面,更类似于土路。
-
“NaN”:这是一个特殊的类别,表示缺失值。当房地产数据中没有提供巷子类型的信息时,这个特征的值可能为"NaN"。
巷子类型可以在某些情况下影响房屋的价值或购买决策,因此在房地产数据分析和建模中,通常会将其作为一个特征进行处理。在处理巷子类型时,可以使用独热编码等方法,将其转化为机器学习模型能够理解的数值形式,以便进行分析或预测。
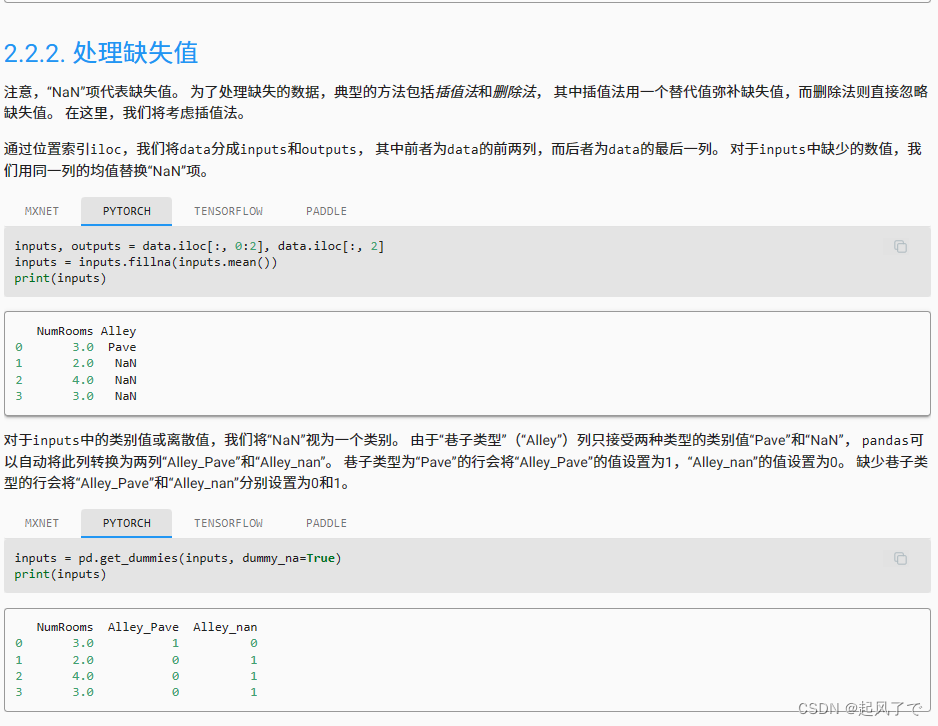
这里对于NumRooms这一列使fillna方法来进行填充,其中mean()用来计算列的平均值。
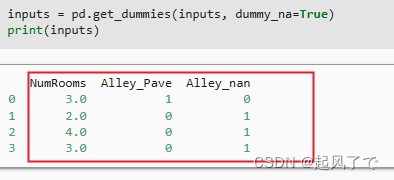
对于Alley_nan 这一分类特征采用的是独热编码来处理 “Alley” 列的缺失值。
转换为张量格式
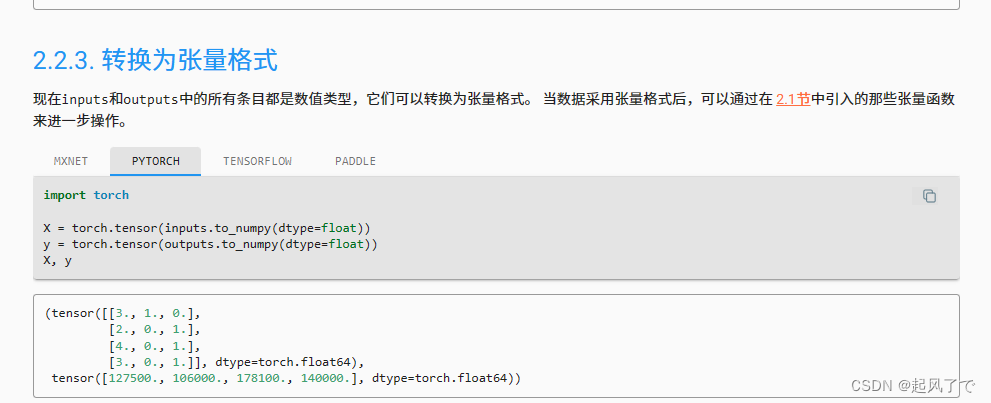
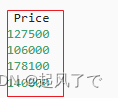
将前面的输入和输出转为张量格式
练习
1、删除缺失值最多的列
# -*- coding: utf-8 -*-
# Author: xxx
"""
李沐《动手学深度学习Pytorch版》第二章第二节
"""
import os
import pandas as pd
os.makedirs(os.path.join('.', 'data'), exist_ok=True)
data_file = os.path.join('.', 'data', 'house_tiny.csv')
with open(data_file, 'w') as f:
f.write('NumRooms,Alley,Price\n') # 列名
f.write('NA,Pave,127500\n') # 每行表示一个数据样本
f.write('2,NA,106000\n')
f.write('4,NA,178100\n')
f.write('NA,NA,140000\n')
data = pd.read_csv(data_file)
print(data)
import pandas as pd
# 读取CSV文件
data_file = "data/house_tiny.csv"
data = pd.read_csv(data_file)
# 统计每列中NaN值的数量
nan_counts = data.isna().sum()
# 找到包含NaN值最多的列
column_with_most_nans = nan_counts.idxmax()
# 删除包含NaN值最多的列
data_cleaned = data.drop(columns=[column_with_most_nans])
# 打印删除后的数据集
print(data_cleaned)
这几行代码的目的是处理数据中的缺失值:
-
nan_counts = data.isna().sum(): 这行代码首先使用data.isna()方法检查数据中的每个元素是否为 NaN(缺失值),然后使用.sum()方法对每列中的 NaN 值进行求和,以得到每列中 NaN 值的数量。nan_counts是一个包含每列 NaN 值数量的 Pandas Series。 -
column_with_most_nans = nan_counts.idxmax(): 这行代码使用nan_counts.idxmax()找到具有最多 NaN 值的列的标签(列名)。它会返回一个字符串,表示包含最多 NaN 值的列的名称。 -
data_cleaned = data.drop(columns=[column_with_most_nans]): 最后,通过使用 Pandas 的drop方法,删除包含最多 NaN 值的列,以得到一个新的数据框data_cleaned,其中不包含具有最多缺失值的那一列。
这个过程的目的是去除数据集中缺失值较多的列,以确保数据质量和模型训练的有效性。在实际数据处理中,处理缺失值是一个重要的数据预处理步骤,可以根据具体情况采用不同的策略,如删除、均值填充、中位数填充等。
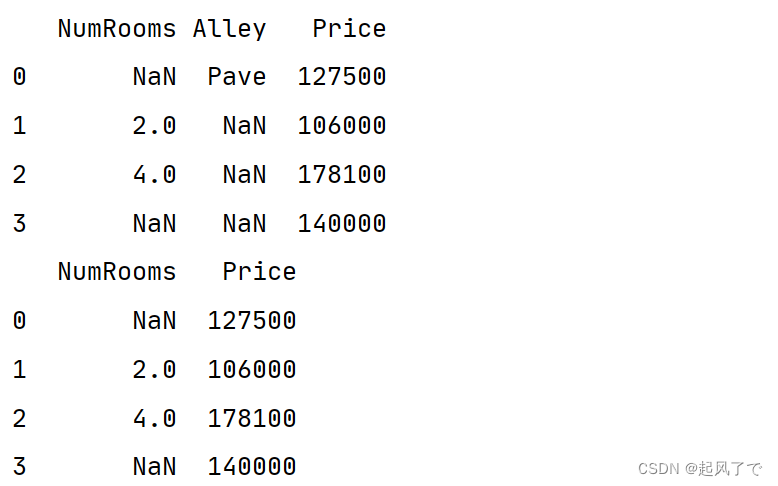
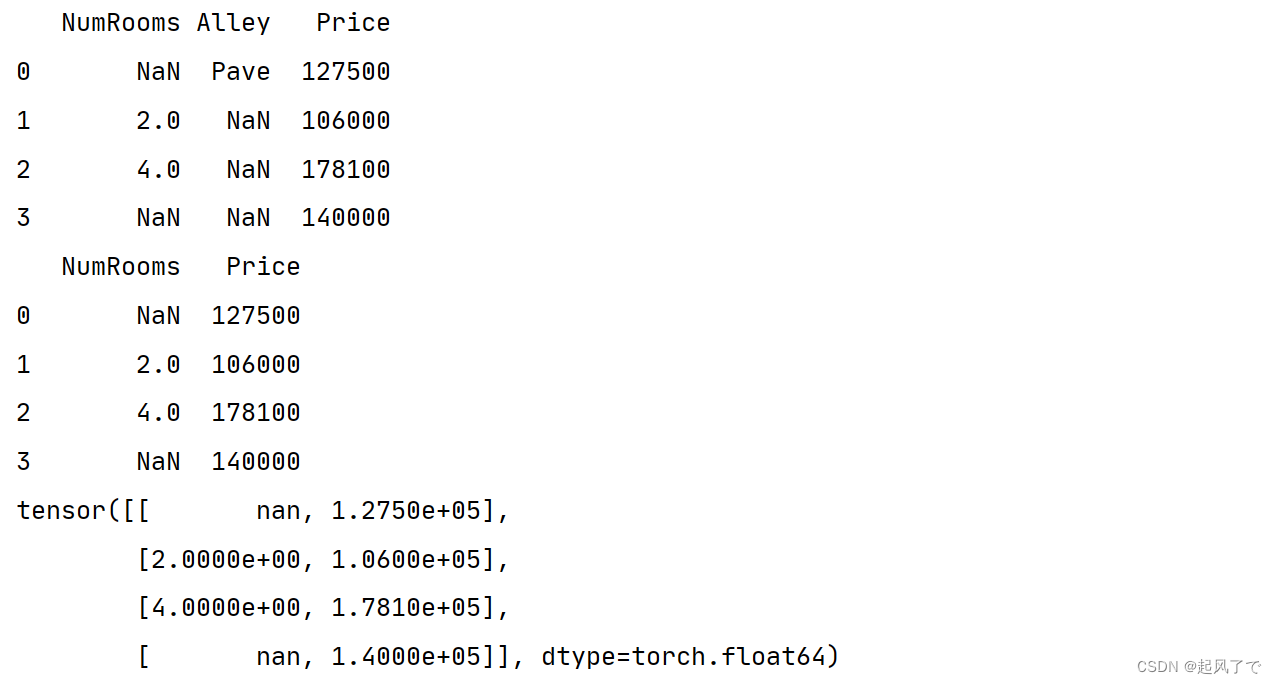
2、将处理后的数据集转换为张量模式
# 将数据转换为 PyTorch 张量
data_tensor = torch.tensor(data_cleaned.to_numpy(dtype=float))
print(data_tensor)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!