K8S(五)—命名空间与资源配额
命名空间(Namespace)
Kubernetes(K8s)的命名空间(Namespace)是用于在集群中对资源进行逻辑隔离和分类的一种机制。它可以将集群内的资源划分为不同的组,并且每个命名空间内的资源都有一个唯一的名称。命名空间可以帮助团队将不同的项目、环境或应用程序从彼此中隔离开来,以及更好地管理资源。
以下是Kubernetes命名空间的详细介绍:
-
隔离和资源分组: 命名空间允许将集群内的资源进行逻辑隔离和资源分组。每个命名空间内部的资源(例如Pod、Service、ReplicaSet等)都具有唯一的名称,但在不同的命名空间中可以有相同名称的资源。
-
默认命名空间: 如果在创建资源时没有指定命名空间,则资源会被自动创建在名为"default"的命名空间中。因此,如果没有显式创建命名空间,大多数资源都位于"default"命名空间。
-
多租户支持: 命名空间为多租户支持提供了基础。在同一个集群上,不同的团队、项目或用户可以使用不同的命名空间来管理和部署它们自己的资源,而不会相互干扰。
-
访问控制: Kubernetes提供了基于RBAC(Role-Based Access Control)的访问控制机制。可以通过RBAC配置来限制用户或服务账号对特定命名空间中资源的访问权限。
-
命名空间范围: 命名空间范围是指命名空间内的资源可以跨越的范围。例如,Cluster-wide资源(如节点和PersistentVolumes)不属于任何特定的命名空间,而Namespace-scoped资源(如Pod和Service)只属于一个命名空间。
-
命名空间标签: 可以为命名空间添加标签(Labels),这些标签可以用于组织和筛选命名空间,以便更轻松地管理和查找资源。
-
内置命名空间: Kubernetes提供了一些内置的命名空间,例如:
- default: 默认命名空间,用于大多数资源的默认创建。
- kube-system: 用于Kubernetes系统组件的命名空间,例如kube-dns、coredns、kube-proxy等。
- kube-public: 这是一个特殊的命名空间,它对所有用户(包括未经身份验证的用户)都是可读的。一些集群信息和配置可以在这里公开。
- kube-node-lease: 用于节点租约的命名空间,确保节点的健康状况。
- kube-ingress: 用于Ingress控制器的命名空间。
-
创建命名空间: 可以使用kubectl命令或YAML文件创建命名空间。例如:
kubectl create namespace my-namespace -
指定命名空间: 在使用kubectl管理资源时,可以通过
--namespace参数指定要操作的命名空间。例如:kubectl get pods --namespace=my-namespace
命令
查看所有的ns 命令:kubectl get ns
kubectl get namespace(ns)
查看指定的ns 命令:kubectl get ns ns名称
kubectl get ns default
指定输出格式 命令:kubectl get ns ns名称 -o 格式参数
kubernetes支持的格式有很多,比较常见的是wide、json、yaml
[root@master ~]# kubectl get ns default -o yaml
查看ns详情 命令:kubectl describe ns ns名称
[root@master ~]# kubectl describe ns default
计算资源配额
资源配额,通过 ResourceQuota 对象来定义,对每个命名空间的资源消耗总量提供限制。 它可以限制命名空间中某种类型的对象的总数目上限,也可以限制命名空间中的 Pod 可以使用的计算资源的总上限。
用户可以对给定命名空间下的可被请求的 计算资源 总量进行限制。
配额机制所支持的资源类型:
| 资源名称 | 描述 |
|---|---|
limits.cpu | 所有非终止状态的 Pod,其 CPU 限额总量不能超过该值。 |
limits.memory | 所有非终止状态的 Pod,其内存限额总量不能超过该值。 |
requests.cpu | 所有非终止状态的 Pod,其 CPU 需求总量不能超过该值。 |
requests.memory | 所有非终止状态的 Pod,其内存需求总量不能超过该值。 |
hugepages-<size> | 对于所有非终止状态的 Pod,针对指定尺寸的巨页请求总数不能超过此值。 |
cpu | 与 requests.cpu 相同。 |
memory | 与 requests.memory 相同。 |
创建命名空间
[root@k8smaster1 ~]# kubectl create namespace quota-mem-cpu-example
绑定一个ResourceQuota资源
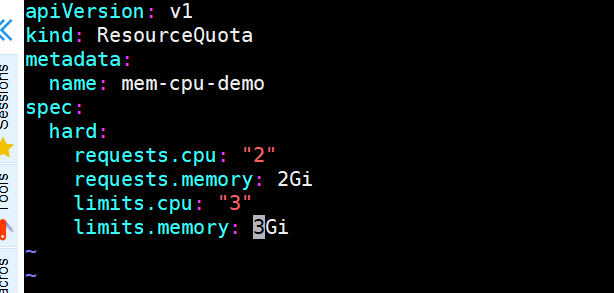
[root@k8smaster ~]# cat quota-mem-cpu.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: mem-cpu-demo
spec:
hard:
requests.cpu: "1"
requests.memory: 1Gi
limits.cpu: "2"
limits.memory: 2Gi
- 在该命名空间中的每个 Pod 的所有容器都必须要有内存请求和限制,以及 CPU 请求和限制。
- 在该命名空间中所有 Pod 的内存请求总和不能超过 1 GiB。
- 在该命名空间中所有 Pod 的内存限制总和不能超过 2 GiB。
- 在该命名空间中所有 Pod 的 CPU 请求总和不能超过 1 cpu。
- 在该命名空间中所有 Pod 的 CPU 限制总和不能超过 2 cpu。
- Requests(请求) 是容器在启动时向 Kubernetes 集群申请的资源(一开始)。它表明容器希望得到的最小资源量。如果容器实际使用的资源低于请求的量,Kubernetes 会为容器分配足够的资源。但是,如果容器实际使用的资源高于请求的量,Kubernetes 可能对容器进行 throttling,限制其使用的资源。
- Limits(限制) 是容器被允许使用的资源的上限(运行中)。它表明容器在运行时可以使用的资源的最大量。如果容器实际使用的资源超过了限制,Kubernetes 集群中的 QoS 机制可能会介入,可能导致容器被终止或限制其资源使用。
所以,您的理解是正确的:请求是在容器启动时申请的资源量,而限制是在容器运行时允许使用的最大资源量。
将命名空间和资源限制对象进行绑定
[root@k8smaster1 ~]# kubectl apply -f quota-mem-cpu.yaml --namespace=quota-mem-cpu-example
resourcequota/mem-cpu-demo created
这是一个用于 Kubernetes 集群中的
kubectl命令,用于将资源配额(ResourceQuota)配置文件应用到指定的命名空间。下面对命令及其参数进行详细解释:
kubectl apply:这是一个kubectl命令,用于将配置文件中定义的 Kubernetes 资源应用到集群。-f quota-mem-cpu.yaml:这个参数指定了要应用的配置文件的路径。在这里,quota-mem-cpu.yaml是一个 Kubernetes 配置文件的文件名,包含了定义资源配额的配置。--namespace=quota-mem-cpu-example:这个参数用于指定要操作的命名空间(Namespace)。在这个命令中,您将资源配额应用到了quota-mem-cpu-example命名空间。综合起来,这个命令的作用是将位于
quota-mem-cpu.yaml文件中定义的资源配额配置应用到了quota-mem-cpu-example命名空间中。资源配额可以用来限制在命名空间内可以使用的 CPU 和内存等资源的量,以确保资源在集群中的合理分配和控制。
获取特定命名空间中的资源配额(ResourceQuota)的详细信息
[root@k8smaster ~]# kubectl get resourcequota mem-cpu-demo --namespace=quota-mem-cpu-example --output=yaml
这是一个使用
kubectl命令的示例,用于获取特定命名空间中的资源配额(ResourceQuota)的详细信息,并以 YAML 格式进行输出。以下是命令及其参数的解析:
kubectl get resourcequota mem-cpu-demo:这部分命令用于获取资源配额对象。mem-cpu-demo是要获取的资源配额的名称。--namespace=quota-mem-cpu-example:这个参数指定了要操作的命名空间(Namespace),即quota-mem-cpu-example。--output=yaml:这个参数指定了输出格式。在这里,使用yaml格式进行输出,将资源配额的详细信息显示为 YAML 格式。综合起来,这个命令的作用是从
quota-mem-cpu-example命名空间中获取名为mem-cpu-demo的资源配额的详细信息,并将其以 YAML 格式进行输出。通过执行该命令,您可以查看资源配额的配置和限制,以确保命名空间中的资源使用得到适当的控制和管理。
尝试创建第二个 Pod
新建quota-mem-cpu-pod.yaml
[root@k8smaster1 ~]# cat quota-mem-cpu-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: quota-mem-cpu-demo
spec:
containers:
- name: quota-mem-cpu-demo-ctr
image: nginx
resources:
limits:
memory: "800Mi"
cpu: "800m"
requests:
memory: "600Mi"
cpu: "400m"
绑定应用
[root@k8smaster1 ~]# kubectl apply -f quota-mem-cpu-pod.yaml --namespace=quota-mem-cpu-example
查看详细信息
[root@k8smaster1 ~]# kubectl get pod -n quota-mem-cpu-example -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
quota-mem-cpu-demo 1/1 Running 0 101s 10.244.249.1 k8snode1 <none> <none>
- 尝试创建第二个 Pod
[root@k8smaster1 ~]# cat quota-mem-cpu-pod-2.yaml
apiVersion: v1
kind: Pod
metadata:
name: quota-mem-cpu-demo-2
spec:
containers:
- name: quota-mem-cpu-demo-2-ctr
image: redis
resources:
limits:
memory: "1Gi"
cpu: "800m"
requests:
memory: "700Mi"
cpu: "400m"
[root@k8smaster1 ~]# kubectl apply -f quota-mem-cpu-pod-2.yaml --namespace=quota-mem-cpu-example
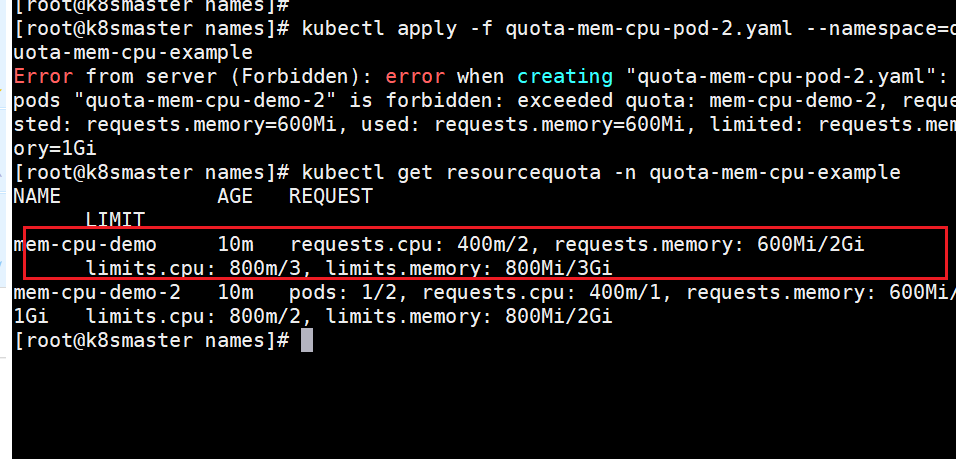
Error from server (Forbidden): error when creating "quota-mem-cpu-pod-2.yaml": pods "quota-mem-cpu-demo-2" is forbidden: exceeded quota: mem-cpu-demo, requested: requests.memory=700Mi, used: requests.memory=600Mi, limited: requests.memory=1Gi
根据报错信息,运行命令
kubectl apply -f quota-mem-cpu-pod-2.yaml --namespace=quota-mem-cpu-example时发生了错误。错误信息指出 Pod 的创建被拒绝,原因是超过了名为 “mem-cpu-demo” 的配额限制。让我们对错误信息进行解析:
Error from server: 从服务器返回的错误。(Forbidden): 操作被拒绝。error when creating "quota-mem-cpu-pod-2.yaml": 在创建 Pod 时出现了错误,具体是在处理 “quota-mem-cpu-pod-2.yaml” 文件时发生的问题。pods "quota-mem-cpu-demo-2" is forbidden: 试图创建名为 “quota-mem-cpu-demo-2” 的 Pod 时被拒绝。exceeded quota: mem-cpu-demo: 超过了 “mem-cpu-demo” 这个配额的限制。requested: requests.memory=700Mi, used: requests.memory=600Mi, limited: requests.memory=1Gi: 在请求中指定了内存的配额,当前已经使用了 600Mi 内存,但是请求的配额超过了该配额的限制,所以 Pod 创建被拒绝了。解决这个问题的方法有两种:
- 调整 Pod 的资源配额: 在 “quota-mem-cpu-pod-2.yaml” 文件中调整 Pod 的资源配额,将请求的内存减少到 “1Gi” 以下,然后再次尝试运行
kubectl apply命令。例如,将requests.memory的值设置为 “500M”。- 调整配额限制: 修改名为 “mem-cpu-demo” 的配额限制,允许更高的内存请求。您可以使用
kubectl edit quota mem-cpu-demo --namespace=quota-mem-cpu-example命令来编辑该配额,并增加requests.memory的限制值,然后保存退出。无论哪种方法,都需要确保请求的资源配额不超过配额限制,这样 Pod 才能够被成功创建。
解决方法:选择将配额进行调整
资源扩展后,第二个pod可以正常进去“quota-men-cpu-example”
https://kubernetes.io/zh-cn/docs/concepts/policy/resource-quotas/
查看ResourceQuota
直接查询
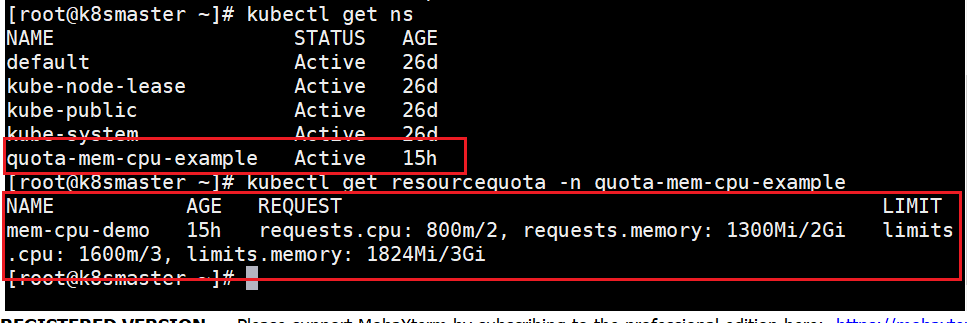
[root@k8smaster names]# kubectl get resourcequota mem-cpu-demo --namespace=quota-mem-cpu-example
NAME AGE REQUEST LIMIT
mem-cpu-demo 16h requests.cpu: 800m/2, requests.memory: 1300Mi/2Gi limits.cpu: 1600m/3, limits.memory: 1824Mi/3Gi
查询以yaml文件进行输出
kubectl get resourcequota mem-cpu-demo --namespace=quota-mem-cpu-example --output=yaml
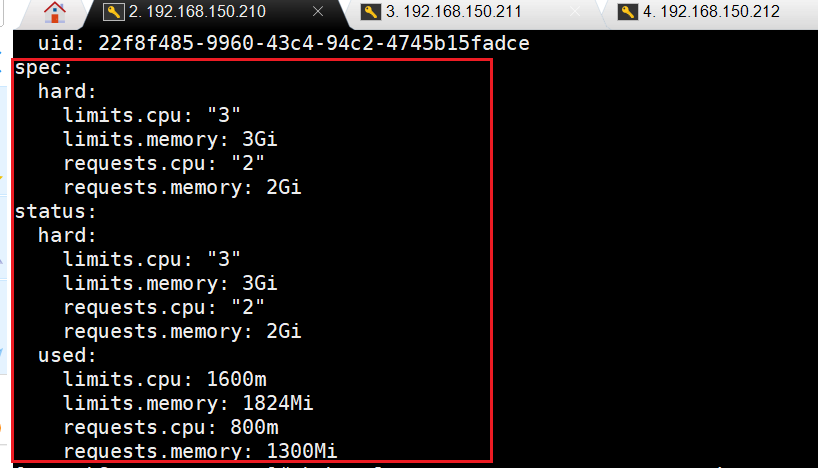
输出结果显示了配额以及有多少配额已经被使用。可以根据情况合理分配资源给pod中。
下载 jq 工具,(使用 JSONPath) 直接查询 used 字段的值,并且输出整齐的 JSON 格式。
centos/redhat
sudo yum install jq -y
查看命令。
kubectl get resourcequota mem-cpu-demo --namespace=quota-mem-cpu-example -o jsonpath='{ .status.used }' | jq .
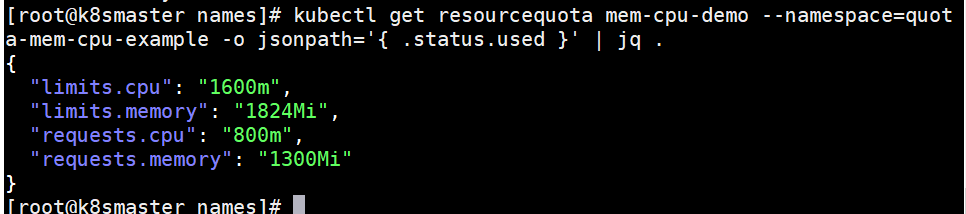
查看“quota-mem-cpu-example”空间中的pod的资源消耗。
[root@k8smaster names]# kubectl get pods --namespace=quota-mem-cpu-example -o=jsonpath='{range .items[*]}{.metadata.name}{"\t"}{.spec.containers[0].resources.requests.cpu}{"\t"}{.spec.containers[0].resources.requests.memory}{"\n"}{end}'
quota-mem-cpu-demo 400m 600Mi
quota-mem-cpu-demo-2 400m 700Mi
绑定第二个ResourceQuota
编写第二个ResourceQuota文件
apiVersion: v1
kind: ResourceQuota
metadata:
name: mem-cpu-demo-2
spec:
hard:
pods : "2"
requests.cpu: "1"
requests.memory: 1Gi
limits.cpu: "2"
limits.memory: 2Gi
这里还进行了pod数量的限制。
命名空间和资源绑定
[root@k8smaster names]# kubectl apply -f quota-mem-cpu-2.yaml --namespace=quota-mem-cpu-example
resourcequota/mem-cpu-demo-2 created
可以看到一个命名空间中已经存在了多个ResourceQuota,

在一个namespace创建多个resourcequota,他们共享内存,pod的创建能否进入这个命名空间,取决于该namespace中的多个ResourceQuota中的多个资源的request是否满足pod的申请数。
为命名空间配置默认的 CPU 、memory请求和限制
创建LimitRange的yaml文件,在该文件中的默认cpu、memory请求和默认cpu、memory限制。
apiVersion: v1
kind: LimitRange
metadata:
name: cpu-limit-range
spec:
limits:
- default:
cpu: 1
memory: 1Gi
defaultRequest:
cpu: 0.5
memory: 500Mi
type: Container
和命名空间进行绑定
[root@k8smaster names]# kubectl apply -f cpu-mem-defaults.yaml -n quota-mem-cpu-example
limitrange/cpu-limit-range created
查看详细信息
kubectl describe limitrange -n quota-mem-cpu-example cpu-limit-range

可以看到“quota-mem-cpu-example”命名空间中,本身存在一个
ResourceQuota。这不影响,搭配使用效果更佳。
如果只有ResourceQuota,里面设置了cpu、memory的请求和限制。
- 那么创建一个加入该命名空间的pod,需要有对应的cpu、memory请求和限制,否则会报错。
- 如何同时有一个ResourceQuota和一个LimitRange,现在不就pod中创建需要特定资源数可以,不指定资源数也可以了。同时ResourceQuota也做了一个命名空间的总资源的限制
(1)Pod 中所有容器都没有声明自己的 CPU 请求和 CPU 限制
创建容器的 Pod 的清单
apiVersion: v1
kind: Pod
metadata:
name: default-cpu-demo
spec:
containers:
- name: default-cpu-demo-ctr
image: nginx
创建pod
kubectl apply -f cpu-mem-pod.yaml -n quota-mem-cpu-example
查看“cpu-mem-demo”的详细情况。
kubectl get pod cpu-mem-demo --output=yaml -n quota-mem-cpu-example
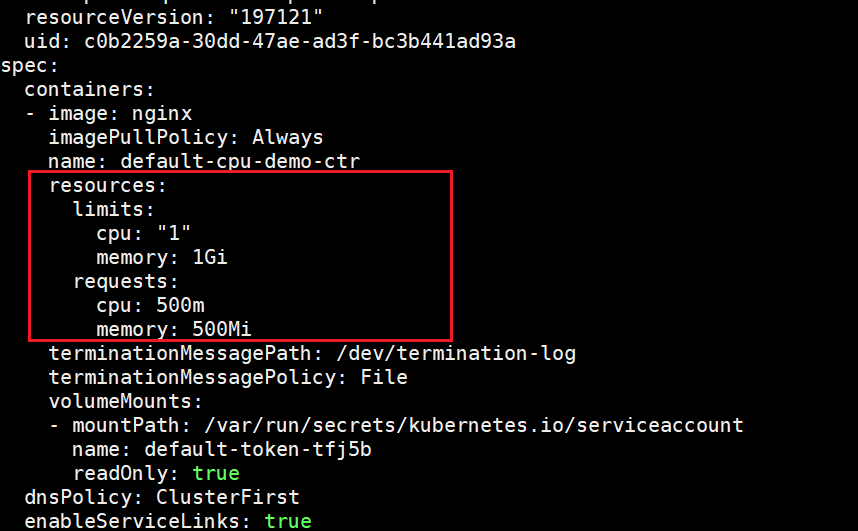
我们来看看ResourceQuota是什么情况,看看是不是cpu、memory也发生了相应的变化,是否能起到对该命名空间资源的整体把握。
这是没有创建空资源pod的情况。
这是创建后的情况

可以发现ResourceQuota中的资源数也发生了相应的变化。
(2)只声明容器的限制
创建清单
apiVersion: v1
kind: Pod
metadata:
name: cpu-mem-demo-2
spec:
containers:
- name: default-cpu-demo-2-ctr
image: nginx
resources:
limits:
cpu: "0.1"
创建pod
kubectl apply -f cpu-mem-pod-2.yaml -n quota-mem-cpu-example
查看“cpu-mem-demo”的详细情况。
kubectl get pod cpu-mem-demo-2 --output=yaml -n quota-mem-cpu-example
输出显示该容器的 CPU 请求和 CPU 限制设置相同。注意该容器没有被指定默认的 CPU 请求值 0.1 cpu:
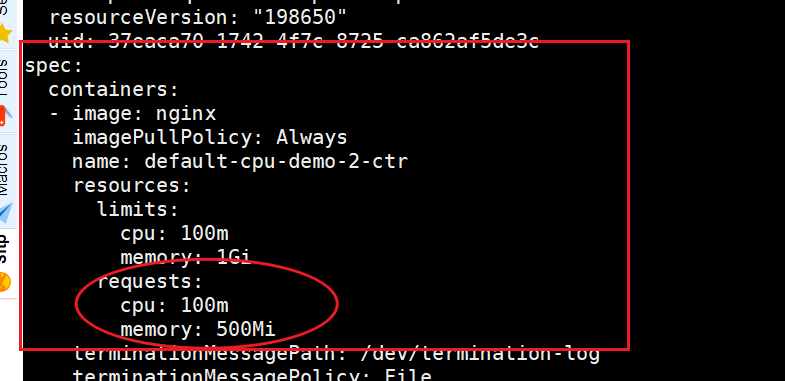

(3)只声明容器的请求
声明pod清单
apiVersion: v1
kind: Pod
metadata:
name: cpu-mem-demo-3
spec:
containers:
- name: default-cpu-demo-3-ctr
image: nginx
resources:
requests:
cpu: "0.2"
创建pod
[root@k8smaster names]# kubectl apply -f cpu-mem-pod-3.yaml -n quota-mem-cpu-example
pod申请的资源超过ResourceQuota限制,无法创建pod,这个时候可以选择缩减pod申请的系统资源,或者扩大ResourceQuota资源限制额。

这里可以看到“memory”的申请和限制额都不足了,这里对pod资源申请进行缩减。
[root@k8smaster names]# cat cpu-mem-pod-3.yaml
apiVersion: v1
kind: Pod
metadata:
name: cpu-mem-demo-3
spec:
containers:
- name: default-cpu-demo-3-ctr
image: nginx
resources:
requests:
cpu: "0.2"
memory: 100Mi
limits:
memory: 100Mi
创建pod
[root@k8smaster names]# kubectl apply -f cpu-mem-pod-3.yaml -n quota-mem-cpu-example
pod/cpu-mem-demo-3 created
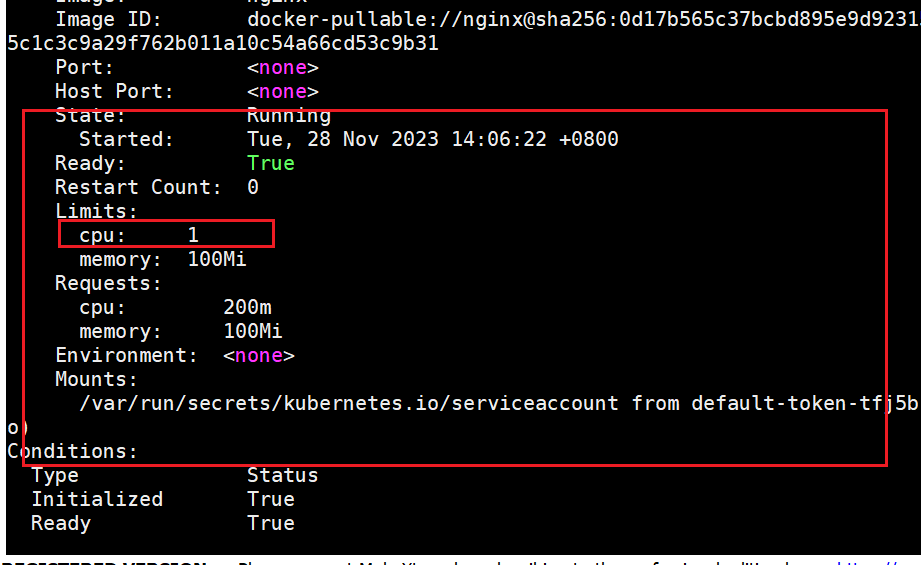
输出显示所创建的 Pod 中,容器的 CPU 请求为 Pod 清单中声明的值。 然而同一容器的 CPU 限制被设置为 1
cpu,此值是该命名空间的默认 CPU 限制值。

可以看到经过pod清单的调整,pod可以在“quota-mem-cpu-example”空间中被声明了。
如果你的命名空间设置了 CPU 资源配额, 为 CPU 限制设置一个默认值会很有帮助。 以下是 CPU 资源配额对命名空间的施加的两条限制:
- 命名空间中运行的每个 Pod 中的容器都必须有 CPU 限制。
- CPU 限制用来在 Pod 被调度到的节点上执行资源预留。
预留给命名空间中所有 Pod 使用的 CPU 总量不能超过规定的限制。
当你添加 LimitRange 时:
如果该命名空间中的任何 Pod 的容器未指定 CPU 限制, 控制面将默认 CPU 限制应用于该容器, 这样 Pod 可以在受到 CPU ResourceQuota 限制的命名空间中运行。
删除命名空间:
kubectl delete namespace your-namespace
当删除一个命名空间时,Kubernetes 会删除该命名空间中的所有资源,包括 Pod、Service、ConfigMap、Secret 等。这意味着在删除命名空间时,命名空间中的所有 Pod 也将被删除。
limitrange 例子
apiVersion: v1
kind: LimitRange
metadata:
name: example-limitrange
spec:
limits:
- type: Container
default:
memory: "256Mi"
cpu: "100m"
max:
memory: "512Mi"
cpu: "200m"
min:
memory: "64Mi"
cpu: "20m"
逐步解释这个配置文件:
apiVersion: v1: 指定 Kubernetes API 的版本,这里是 v1。kind: LimitRange: 定义资源对象的类型,这里是 LimitRange。metadata: 包含对象的元数据,例如对象的名称。name: example-limitrange: 设置 LimitRange 对象的名称为 “example-limitrange”。spec: 指定 LimitRange 对象的规格,包括资源的限制。limits: 包含一个列表,其中定义了资源限制的规则。在这个例子中,只有一个规则,类型是 “Container”,表示这个规则适用于容器。max、min和default: 定义了对应资源(这里是内存和 CPU)的最大值、最小值和默认值。
- 对于内存(Memory):
- 最大值为 “512Mi”。
- 最小值为 “64Mi”。
- 默认值为 “256Mi”。
- 对于 CPU:
- 最大值为 “200m”(表示 200 毫核)。
- 最小值为 “20m”(表示 20 毫核)。
- 默认值为 “100m”(表示 100 毫核)。
存储资源配额
用户可以对给定命名空间下的存储资源 总量进行限制。
此外,还可以根据相关的存储类(Storage Class)来限制存储资源的消耗。
| 资源名称 | 描述 |
|---|---|
requests.storage | 所有 PVC,存储资源的需求总量不能超过该值。 |
persistentvolumeclaims | 在该命名空间中所允许的 PVC 总量。 |
<storage-class-name>.storageclass.storage.k8s.io/requests.storage | 在所有与 <storage-class-name> 相关的持久卷申领中,存储请求的总和不能超过该值。 |
<storage-class-name>.storageclass.storage.k8s.io/persistentvolumeclaims | 在与 storage-class-name 相关的所有持久卷申领中,命名空间中可以存在的持久卷申领总数。 |
例如,如果一个操作人员针对 gold 存储类型与 bronze 存储类型设置配额, 操作人员可以定义如下配额:
gold.storageclass.storage.k8s.io/requests.storage: 500Gibronze.storageclass.storage.k8s.io/requests.storage: 100Gi
在 Kubernetes 1.8 版本中,本地临时存储的配额支持已经是 Alpha 功能:
| 资源名称 | 描述 |
|---|---|
requests.ephemeral-storage | 在命名空间的所有 Pod 中,本地临时存储请求的总和不能超过此值。 |
limits.ephemeral-storage | 在命名空间的所有 Pod 中,本地临时存储限制值的总和不能超过此值。 |
ephemeral-storage | 与 requests.ephemeral-storage 相同。 |
说明:
如果所使用的是 CRI 容器运行时,容器日志会被计入临时存储配额。 这可能会导致存储配额耗尽的 Pods 被意外地驱逐出节点。 参考日志架构 了解详细信息。
示例
创建命名空间(storage)
[root@k8smaster names]# kubectl create ns storage
namespace/storage created
当设置存储资源配额时,可以根据具体的需求和实际情况进行调整。以下是更多详细的存储资源配额的例子:
apiVersion: v1
kind: ResourceQuota
metadata:
name: storage-quota
spec:
hard:
# 设置存储请求的总和不超过10Gi
requests.storage: "10Gi"
# 设置CPU限制总和不超过4核
limits.cpu: "4"
# 设置内存限制总和不超过8Gi
limits.memory: "8Gi"
# 设置PersistentVolume数量不超过3个
persistentvolumeclaims: "3"
# 设置Service数量不超过5个
services: "5"
# 设置ConfigMap和Secret的总和不超过10个
configmaps: "5"
secrets: "5"
在这个例子中,配额限制了命名空间中的存储资源使用情况:
- 存储请求总和不能超过10 GiB。
- CPU限制总和不能超过4核。
- 内存限制总和不能超过8 GiB。
- PersistentVolume数量不能超过3个。
- Service数量不能超过5个。
- ConfigMap和Secret的总和不能超过10个。
ResourceQuota和命名空间绑定。
[root@k8smaster names]# kubectl apply -f storage.yaml -n storage
resourcequota/storage-quota created
查看ResourceQuota详细信息
[root@k8smaster names]# kubectl get resourcequota -n storage
NAME AGE REQUEST LIMIT
storage-quota 98s configmaps: 1/5, persistentvolumeclaims: 0/3, requests.storage: 0/10Gi, secrets: 1/5, services: 0/5 limits.cpu: 0/4, limits.memory: 0/8Gi
对象数量配额
你可以使用以下语法对所有标准的、命名空间域的资源类型进行配额设置:
count/<resource>.<group>:用于非核心(core)组的资源count/<resource>:用于核心组的资源
这是用户可能希望利用对象计数配额来管理的一组资源示例。
count/persistentvolumeclaimscount/servicescount/secretscount/configmapscount/replicationcontrollerscount/deployments.appscount/replicasets.appscount/statefulsets.appscount/jobs.batchcount/cronjobs.batch
相同语法也可用于自定义资源。 例如,要对 example.com API 组中的自定义资源 widgets 设置配额,请使用 count/widgets.example.com。
当使用 count/* 资源配额时,如果对象存在于服务器存储中,则会根据配额管理资源。 这些类型的配额有助于防止存储资源耗尽。例如,用户可能想根据服务器的存储能力来对服务器中 Secret 的数量进行配额限制。 集群中存在过多的 Secret 实际上会导致服务器和控制器无法启动。 用户可以选择对 Job 进行配额管理,以防止配置不当的 CronJob 在某命名空间中创建太多 Job 而导致集群拒绝服务。
对有限的一组资源上实施一般性的对象数量配额也是可能的。
支持以下类型:
| 资源名称 | 描述 |
|---|---|
configmaps | 在该命名空间中允许存在的 ConfigMap 总数上限。 |
persistentvolumeclaims | 在该命名空间中允许存在的 PVC 的总数上限。 |
pods | 在该命名空间中允许存在的非终止状态的 Pod 总数上限。Pod 终止状态等价于 Pod 的 .status.phase in (Failed, Succeeded) 为真。 |
replicationcontrollers | 在该命名空间中允许存在的 ReplicationController 总数上限。 |
resourcequotas | 在该命名空间中允许存在的 ResourceQuota 总数上限。 |
services | 在该命名空间中允许存在的 Service 总数上限。 |
services.loadbalancers | 在该命名空间中允许存在的 LoadBalancer 类型的 Service 总数上限。 |
services.nodeports | 在该命名空间中允许存在的 NodePort 类型的 Service 总数上限。 |
secrets | 在该命名空间中允许存在的 Secret 总数上限。 |
例如,pods 配额统计某个命名空间中所创建的、非终止状态的 Pod 个数并确保其不超过某上限值。 用户可能希望在某命名空间中设置 pods 配额,以避免有用户创建很多小的 Pod, 从而耗尽集群所能提供的 Pod IP 地址。
示例
创建命名空间(storage)
[root@k8smaster names]# kubectl create ns object
namespace/object created
以下是一组可于管理的资源类型的对象计数配额的示例:
yamlCopy codeapiVersion: v1
kind: ResourceQuota
metadata:
name: example-object-quota
spec:
hard:
count/persistentvolumeclaims: 5
count/services: 10
count/secrets: 20
count/configmaps: 15
count/replicationcontrollers: 3
count/deployments.apps: 2
count/replicasets.apps: 4
count/statefulsets.apps: 1
count/jobs.batch: 5
count/cronjobs.batch: 2
与命名空间进行绑定。

配额作用域
每个配额都有一组相关的 scope(作用域),配额只会对作用域内的资源生效。 配额机制仅统计所列举的作用域的交集中的资源用量。
当一个作用域被添加到配额中后,它会对作用域相关的资源数量作限制。 如配额中指定了允许(作用域)集合之外的资源,会导致验证错误。
| 作用域 | 描述 |
|---|---|
Terminating | 匹配所有 spec.activeDeadlineSeconds 不小于 0 的 Pod。 |
NotTerminating | 匹配所有 spec.activeDeadlineSeconds 是 nil 的 Pod。 |
BestEffort | 匹配所有 Qos 是 BestEffort 的 Pod。 |
NotBestEffort | 匹配所有 Qos 不是 BestEffort 的 Pod。 |
PriorityClass | 匹配所有引用了所指定的优先级类的 Pods。 |
CrossNamespacePodAffinity | 匹配那些设置了跨名字空间 (反)亲和性条件的 Pod。 |
BestEffort 作用域限制配额跟踪以下资源:
pods
Terminating、NotTerminating、NotBestEffort 和 PriorityClass 这些作用域限制配额跟踪以下资源:
podscpumemoryrequests.cpurequests.memorylimits.cpulimits.memory
需要注意的是,你不可以在同一个配额对象中同时设置 Terminating 和 NotTerminating 作用域,你也不可以在同一个配额中同时设置 BestEffort 和 NotBestEffort 作用域。
scopeSelector 支持在 operator 字段中使用以下值:
InNotInExistsDoesNotExist
定义 scopeSelector 时,如果使用以下值之一作为 scopeName 的值,则对应的 operator 只能是 Exists。
TerminatingNotTerminatingBestEffortNotBestEffort
如果 operator 是 In 或 NotIn 之一,则 values 字段必须至少包含一个值。 例如:
scopeSelector:
matchExpressions:
- scopeName: PriorityClass
operator: In
values:
- middle
如果 operator 为 Exists 或 DoesNotExist,则不可以设置 values 字段。
示例
一个配额对象中使用不同的作用域进行资源数量限制:
apiVersion: v1
kind: ResourceQuota
metadata:
name: example-resource-quota
spec:
hard:
pods: "10"
cpu: "2"
memory: 2Gi
requests.cpu: "1"
requests.memory: 1Gi
limits.cpu: "1.5"
limits.memory: 1.5Gi
scopeSelector:
matchScopes:
- Terminating
- NotBestEffort
- PriorityClass
- CrossNamespacePodAffinity
operator: In
values:
- middle
在这个例子中:
hard字段定义了资源的硬性限制,包括 Pod 数量、CPU 使用、内存使用,以及请求和限制的 CPU 和内存。scopeSelector字段定义了作用域选择器,包括Terminating、NotBestEffort、PriorityClass和CrossNamespacePodAffinity。它使用In操作符,表示这些作用域的交集中的资源会受到限制。- 对于
PriorityClass,配额限制了引用了 “middle” 优先级类的 Pods。
请注意,这只是一个示例,实际中你需要根据你的需求来调整这些作用域和配额值。
基于优先级类(PriorityClass)来设置资源配额
特性状态: Kubernetes v1.17 [stable]
Pod 可以创建为特定的优先级。 通过使用配额规约中的 scopeSelector 字段,用户可以根据 Pod 的优先级控制其系统资源消耗。
仅当配额规范中的 scopeSelector 字段选择到某 Pod 时,配额机制才会匹配和计量 Pod 的资源消耗。
如果配额对象通过 scopeSelector 字段设置其作用域为优先级类, 则配额对象只能跟踪以下资源:
podscpumemoryephemeral-storagelimits.cpulimits.memorylimits.ephemeral-storagerequests.cpurequests.memoryrequests.ephemeral-storage
本示例创建一个配额对象,并将其与具有特定优先级的 Pod 进行匹配。 该示例的工作方式如下:
- 集群中的 Pod 可取三个优先级类之一,即 “low”、“medium”、“high”。
- 为每个优先级创建一个配额对象。
将以下 YAML 保存到文件 quota.yml 中。
apiVersion: v1
kind: List
items:
- apiVersion: v1
kind: ResourceQuota
metadata:
name: pods-high
spec:
hard:
cpu: "500"
memory: 5Gi
pods: "10"
scopeSelector:
matchExpressions:
- operator: In
scopeName: PriorityClass
values: ["high"]
- apiVersion: v1
kind: ResourceQuota
metadata:
name: pods-medium
spec:
hard:
cpu: "100"
memory: 2Gi
pods: "10"
scopeSelector:
matchExpressions:
- operator: In
scopeName: PriorityClass
values: ["medium"]
- apiVersion: v1
kind: ResourceQuota
metadata:
name: pods-low
spec:
hard:
cpu: "10"
memory: 1Gi
pods: "10"
scopeSelector:
matchExpressions:
- operator: In
scopeName: PriorityClass
values: ["low"]
使用 kubectl create 命令运行以下操作。
kubectl create -f ./quota.yml
resourcequota/pods-high created
resourcequota/pods-medium created
resourcequota/pods-low created
使用 kubectl describe quota 操作验证配额的 Used 值为 0。
kubectl describe quota
Name: pods-high
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 0 500
memory 0 5Gi
pods 0 10
Name: pods-low
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 0 10
memory 0 1Gi
pods 0 10
Name: pods-medium
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 0 100
memory 0 2Gi
pods 0 10
创建优先级为 “high” 的 Pod。 将以下 YAML 保存到文件 high-priority-pod.yml 中。
apiVersion: v1
kind: Pod
metadata:
name: high-priority
spec:
containers:
- name: high-priority
image: ubuntu
command: ["/bin/sh"]
args: ["-c", "while true; do echo hello; sleep 10;done"]
resources:
requests:
memory: "2Gi"
cpu: "100m"
limits:
memory: "3Gi"
cpu: "150m"
priorityClassName: high
创建一个名为“high”的prorityclass的yaml文件
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high
value: 1000000 # 根据您的优先级要求调整值
globalDefault: false
description: "此 PriorityClass 用于高优先级 Pods。"
进行声明
kubectl apply -f high-priority-class.yaml
查看“priorityclass”
[root@k8smaster priority]# kubectl get priorityclass
NAME VALUE GLOBAL-DEFAULT AGE
high 1000000 false 3m10s
system-cluster-critical 2000000000 false 27d
system-node-critical 2000001000 false 27d
使用 kubectl create 运行以下操作。
kubectl create -f ./high-priority-pod.yml
确认 “high” 优先级配额 pods-high 的 “Used” 统计信息已更改,并且其他两个配额未更改。
kubectl describe quota
Name: pods-high
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 100m 500
memory 2Gi 5Gi
pods 1 10
Name: pods-low
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 0 10
memory 0 1Gi
pods 0 10
Name: pods-medium
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 0 100
memory 0 2Gi
pods 0 10
跨名字空间的 Pod 亲和性配额
特性状态: Kubernetes v1.24 [stable]
集群运维人员可以使用 CrossNamespacePodAffinity 配额作用域来限制哪个名字空间中可以存在包含跨名字空间亲和性规则的 Pod。 更为具体一点,此作用域用来配置哪些 Pod 可以在其 Pod 亲和性规则中设置 namespaces 或 namespaceSelector 字段。
禁止用户使用跨名字空间的亲和性规则可能是一种被需要的能力, 因为带有反亲和性约束的 Pod 可能会阻止所有其他名字空间的 Pod 被调度到某失效域中。
使用此作用域操作符可以避免某些名字空间(例如下面例子中的 foo-ns)运行特别的 Pod, 这类 Pod 使用跨名字空间的 Pod 亲和性约束,在该名字空间中创建了作用域为 CrossNamespacePodAffinity 的、硬性约束为 0 的资源配额对象。
apiVersion: v1
kind: ResourceQuota
metadata:
name: disable-cross-namespace-affinity
namespace: foo-ns
spec:
hard:
pods: "0"
scopeSelector:
matchExpressions:
- scopeName: CrossNamespacePodAffinity
operator: Exists
如果集群运维人员希望默认禁止使用 namespaces 和 namespaceSelector, 而仅仅允许在特定名字空间中这样做,他们可以将 CrossNamespacePodAffinity 作为一个被约束的资源。方法是为 kube-apiserver 设置标志 --admission-control-config-file,使之指向如下的配置文件:
apiVersion: apiserver.config.k8s.io/v1
kind: AdmissionConfiguration
plugins:
- name: "ResourceQuota"
configuration:
apiVersion: apiserver.config.k8s.io/v1
kind: ResourceQuotaConfiguration
limitedResources:
- resource: pods
matchScopes:
- scopeName: CrossNamespacePodAffinity
operator: Exists
基于上面的配置,只有名字空间中包含作用域为 CrossNamespacePodAffinity 且硬性约束大于或等于使用 namespaces 和 namespaceSelector 字段的 Pod 个数时,才可以在该名字空间中继续创建在其 Pod 亲和性规则中设置 namespaces 或 namespaceSelector 的新 Pod。
请求与限制的比较
分配计算资源时,每个容器可以为 CPU 或内存指定请求和约束。 配额可以针对二者之一进行设置。
如果配额中指定了 requests.cpu 或 requests.memory 的值,则它要求每个容器都显式给出对这些资源的请求。 同理,如果配额中指定了 limits.cpu 或 limits.memory 的值,那么它要求每个容器都显式设定对应资源的限制。
查看和设置配额
Kubectl 支持创建、更新和查看配额:
kubectl create namespace myspace
cat <<EOF > compute-resources.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-resources
spec:
hard:
requests.cpu: "1"
requests.memory: 1Gi
limits.cpu: "2"
limits.memory: 2Gi
requests.nvidia.com/gpu: 4
EOF
kubectl create -f ./compute-resources.yaml --namespace=myspace
cat <<EOF > object-counts.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: object-counts
spec:
hard:
configmaps: "10"
persistentvolumeclaims: "4"
pods: "4"
replicationcontrollers: "20"
secrets: "10"
services: "10"
services.loadbalancers: "2"
EOF
kubectl create -f ./object-counts.yaml --namespace=myspace
kubectl get quota --namespace=myspace
NAME AGE
compute-resources 30s
object-counts 32s
kubectl describe quota compute-resources --namespace=myspace
Name: compute-resources
Namespace: myspace
Resource Used Hard
-------- ---- ----
limits.cpu 0 2
limits.memory 0 2Gi
requests.cpu 0 1
requests.memory 0 1Gi
requests.nvidia.com/gpu 0 4
kubectl describe quota object-counts --namespace=myspace
pace
Name: object-counts
Namespace: myspace
Resource Used Hard
-------- ---- ----
configmaps 1 10
persistentvolumeclaims 0 4
pods 0 4
replicationcontrollers 0 20
secrets 1 10
services 0 10
services.loadbalancers 0 2
查看“configmaps”
[root@k8smaster priority]# kubectl get configmaps --namespace=myspace
NAME DATA AGE
kube-root-ca.crt 1 79s
kubectl describe configmap kube-root-ca.crt --namesp ace=myspace
ace=myspace
Name: kube-root-ca.crt
Namespace: myspace
Labels: <none>
Annotations: <none>
Data
====
ca.crt:
----
-----BEGIN CERTIFICATE-----
MIIC5zCCAc+gAwIBAgIBADANBgkqhkiG9w0BAQsFADAVMRMwEQYDVQQDEwprdWJl
cm5ldGVzMB4XDTIzMTEwMTA2MjkzMVoXDTMzMTAyOTA2MjkzMVowFTETMBEGA1UE
AxMKa3ViZXJuZXRlczCCASIwDQYJKoZIhvcNAQEBBQADggEPADCCAQoCggEBAM4/
LpHETK0oO//kLbYIBao8XkpOlngeCI9LDjPb3EZ0RHJvfPLSf76+hnDTfnQng4W8
xWqKKD7TMgyQQxRXRmkf5fr6hzYK+PfCnNnw7JxlXv1s/Ne5Fwq3xWSzpbR1UrUz
j4UeYHGFcEbmkLk8574Okte0fEIXJ7xalavSUQPIVlCN+pmBYMk1emhpzjCaQfKY
9p41r43ADAiHeLNqpeJsS3Cypgc1ra7i+hLGRQ0x18lJ5a4ri2x42gMl4JWUkrZz
j0xV4BvtF7apl9FBclIutbUQA5j6eFu+9a5k6J9XquhtwpjIfVxl2x18WblH+ogy
/AeLdvSyo2A6XIS7rDsCAwEAAaNCMEAwDgYDVR0PAQH/BAQDAgKkMA8GA1UdEwEB
/wQFMAMBAf8wHQYDVR0OBBYEFGvglNTMLDATLYCDVj1xHuLdLKDgMA0GCSqGSIb3
DQEBCwUAA4IBAQBT1sQR3E6mumre6b18YmxNeFXXMgY21fOthS9S6zT/6of6qKBZ
5LXsQAmFQeaDlqTTWb5EgHzr1P9Ew0Y2A303Uoyb/H3qosjvgEOnwUlj/zL5mx+l
3i3v/ZTflGRKnLhNFVVmB2QOPlaTp0haE8bbPv1QyEJydQOkOCLDxJCeHtZawWrI
2DXaq+CBdUz2RKOOr8o53mhYeLuaF7vQcv8V2s+EPnbzeRUWXqdTaMsLv4GOlIVC
kKXM+P37T4ASrC/M6lpWukraE6UnFF5O+iw0Xv9YTE4UcbV41BMmgHsMfbdz87E3
c6ztPxXaAe9maDTZ6wBBVeoShr+oqmyFGwVQ
-----END CERTIFICATE-----
Events: <none>
kubectl 还使用语法 count/<resource>.<group> 支持所有标准的、命名空间域的资源的对象计数配额:
kubectl create namespace myspace
kubectl create quota test --hard=count/deployments.apps=2,count/replicasets.apps=4,count/pods=3,count/secrets=4 --namespace=myspace
kubectl create deployment nginx --image=nginx --namespace=myspace --replicas=2
kubectl describe quota --namespace=myspace
Name: test
Namespace: myspace
Resource Used Hard
-------- ---- ----
count/deployments.apps 1 2
count/pods 2 3
count/replicasets.apps 1 4
count/secrets 1 4
配额和集群容量
ResourceQuota 与集群资源总量是完全独立的。它们通过绝对的单位来配置。 所以,为集群添加节点时,资源配额不会自动赋予每个命名空间消耗更多资源的能力。
有时可能需要资源配额支持更复杂的策略,比如:
- 在几个团队中按比例划分总的集群资源。
- 允许每个租户根据需要增加资源使用量,但要有足够的限制以防止资源意外耗尽。
- 探测某个命名空间的需求,添加物理节点并扩大资源配额值。
这些策略可以通过将资源配额作为一个组成模块、手动编写一个控制器来监控资源使用情况, 并结合其他信号调整命名空间上的硬性资源配额来实现。
注意:资源配额对集群资源总体进行划分,但它对节点没有限制:来自不同命名空间的 Pod 可能在同一节点上运行。
默认情况下限制特定优先级的资源消耗
有时候可能希望当且仅当某名字空间中存在匹配的配额对象时,才可以创建特定优先级 (例如 “cluster-services”)的 Pod。
通过这种机制,操作人员能够限制某些高优先级类仅出现在有限数量的命名空间中, 而并非每个命名空间默认情况下都能够使用这些优先级类。
要实现此目的,应设置 kube-apiserver 的标志 --admission-control-config-file 指向如下配置文件:
apiVersion: apiserver.config.k8s.io/v1
kind: AdmissionConfiguration
plugins:
- name: "ResourceQuota"
configuration:
apiVersion: apiserver.config.k8s.io/v1
kind: ResourceQuotaConfiguration
limitedResources:
- resource: pods
matchScopes:
- scopeName: PriorityClass
operator: In
values: ["cluster-services"]
现在在 kube-system 名字空间中创建一个资源配额对象:
policy/priority-class-resourcequota.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: pods-cluster-services
spec:
scopeSelector:
matchExpressions:
- operator : In
scopeName: PriorityClass
values: ["cluster-services"]
kubectl apply -f https://k8s.io/examples/policy/priority-class-resourcequota.yaml -n kube-system
resourcequota/pods-cluster-services created
在这里,当以下条件满足时可以创建 Pod:
- Pod 未设置
priorityClassName - Pod 的
priorityClassName设置值不是cluster-services - Pod 的
priorityClassName设置值为cluster-services,它将被创建于kube-system名字空间中,并且它已经通过了资源配额检查。
如果 Pod 的 priorityClassName 设置为 cluster-services,但要被创建到 kube-system 之外的别的名字空间,则 Pod 创建请求也被拒绝。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!