多模态大模型的前世今生
1 引言
前段时间 ChatGPT 进行了一轮重大更新:多模态上线,能说话,会看图!微软发了一篇长达 166 页的 GPT-4V 测评论文,一时间又带起了一阵多模态的热议,随后像是 LLaVA-1.5、CogVLM、MiniGPT-5 等研究工作紧随其后,到处刷屏。大模型的多模态能力到底是怎么来的?
2 CLIP: 连接文本和图像的桥梁
CLIP 是由 OpenAI 在 2021 年提出的预训练模型,用于评估给定图像与给定文本描述的匹配程度。该模型使用大量(约 4 亿)从网页中爬取的图像-文本对(pair)数据进行对比学习。
数据的收集:
- 搜索了 50w 个 queries(query 列表主要来自英文版维基百科中至少出现 100 次的所有单词,并做了些其他补充)
- 为了保证每个 query 的数据相对平衡,每个 query 保留最多 2w 个(image, text)
典型的双塔模型,有两个 encoder,一个对应图片,一个对应文本,图像和文本经过各自的 encoder 后,通过简单的点乘来代表不同模态的交互(相似性)。
训练时,假设一个 batch 有 N 对(图像,文本)对,可以有 N x N 种组合方式,对比学习把原始数据集中的 N 个组合作为正样本(下图对角线),把其他的 N x N - N 种组合作为负样本(下图非对角线)。

模型训练的目标就是最大化对角线上的分数,并最小化对角线外的分数。这里从分类的角度给大家一个关于损失函数的理解,可以把每一行/列看作是个一个 N 分类问题,其中分类的标签就是真实图文组合所在位置(也就是对角线),比如第一行的 label 是 0,第二行的 label 是 1,以此类推。
论文中给出了实现 CLIP 的 numpy 风格伪代码
# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
# I[n, h, w, c] - minibatch of aligned images
# T[n, l] - minibatch of aligned texts
# W_i[d_i, d_e] - learned proj of image to embed
# W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter
# extract feature representations of each modality
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]
# joint multimodal embedding [n, d_e]
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# scaled pairwise cosine similarities [n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# symmetric loss function
labels = np.arange(n)
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2因为 CLIP 在两个 encoder 后只进行了简单的内积作为模态的交互,对于复杂点的任务就不那么 work 了,一个顺其自然的发展就是去增强不同模态的交互/融合,也就是可以用一个神经网络来替换内积。
3 ALBEF:先对齐后融合
文章的主要贡献有两个:
- ALBEF 解决了多模态领域中图像和文本对齐、交互的问题。在 ALBEF 之前,多模态方法通常使用 transformer 的多模态编码器来同时编码视觉和文本特征,由于目标检测器是提前训练好的,因此视觉和文本特征并不是对齐的。图像和文本特征可能距离很远,这使得多模态编码器难以学习到它们之间的交互。为了解决这个问题,ALBEF 通过一个对比损失(也就是 CLIP 中的 ITC 损失)在进行多模态交互之前对齐图像和文本数据。
- 网上爬取的大量图文对通常噪声很大(图文不匹配)。ALBEF 采用动量蒸馏(momentum distillation)的自训练方法来从网络图文对数据中学习,以缓解原始数据中的噪声问题。从理论上讲,ALBEF 通过互信息最大化的角度解释了不同的多模态任务,说明不同任务实际上为图文对提供了不同的视角,类似于数据增强,使得训练得到的多模态模型能够理解不同模态下的语义,具备语义保持的能力。
接下来看一下模型的结构:

- 下面红色框其实就类似于 CLIP,双塔各自编码图像和文本,然后取 CLS 进行对比学习;
- 上面蓝色框就是为了加强不同模态交互用的编码器(前面提到过 CLIP 内积的方式太简单了,这里就是加强多模态融合以适配更难的任务);
- 图像编码器 12 层,文本编码器 6 层,多模态编码器 6 层;其实右侧是将一个 12 层的文本编码器拆成了两部分,这是因为一些研究工作发现在多模态中需要更强的图像编码器,进行这样的拆分一定程度上保证了强图像 encoder 和弱文本 encoder,且保证了模型参数不过多的情况下融合图像和文本的信息。
训练的目标函数:
- ITC loss,这个跟 CLIP 是一样的

- ITM loss,在 ITM 任务中,模型需要判断一对图像和文本是否匹配。为了实现这一目标,论文使用多模态编码器输出的[CLS] token 的嵌入作为图像-文本对的联合表示,并通过一个全连接层和 softmax 函数来预测一个二分类的概率。由于判断 batch 内的负样本过于简单,文章提出通过 ITC loss 计算得到的各样本间的余弦相似度,取除正样本外相似度最高的作"hard negatives"。

- MLM loss,mask 掉一些文本,然后将 mask 过后的文本和图片一起通过 ALBEF 模型,预测 mask 掉的文本。因此,ALBEF 的每一轮迭代需要经过两次前向传播的过程。多模态学习的方法通常训练时长较长,就是因为需要进行多次前向传播,计算不同的损失。

总的 loss 就是三个 loss 简单加和:
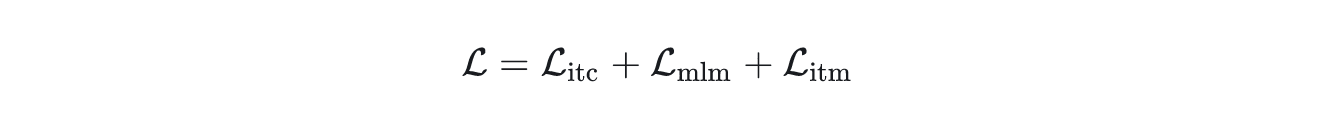
动量蒸馏:通过保持一个模型的动量版本来生成伪标签,作为额外的监督信号进行训练。
- 使用基础模型的参数的指数移动平均版本作为动量模型
- 使用动量模型生成的伪标签(是个分布)进行训练
- 主模型的预测既要跟 one-hot 标签尽可能接近之外,也要跟 pseudo-targets 尽可能接近(KL 散度)
ITC loss:
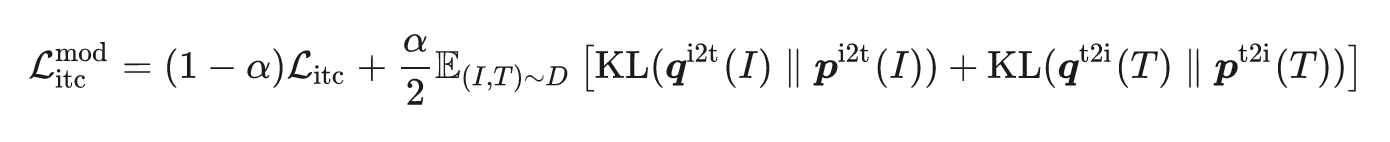
MLM loss:
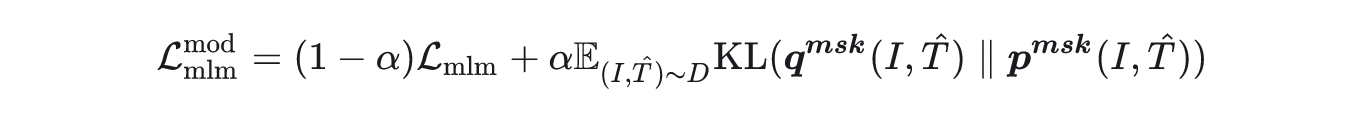
多模态编码器能够提高不同模态交互/融合的能力,使得模型在一些任务上表现更好,但是在检索任务数据集大的时候,推理时间会非常慢,那能不能解决这个问题?
4 VLMO: 灵活才是王道
VLMo 模型通过使用混合模态专家(MoME)Transformer 实现了统一的视觉-语言预训练。MoME Transformer 的结构设计允许根据输入信号的不同使用对应的 FFN 层参数进行计算。具体来说,VLMo 模型包括了视觉专家(V-FFN)、文本专家(L-FFN)和图文专家(VL-FFN),它们分别用于处理图像、文本和图像-文本输入。这种灵活的设计使得VLMo 模型能够根据任务的不同使用不同的结构进行训练和推理。

在预训练阶段,VLMo 模型采用了三种任务:图像-文本对比学习(ITC)、图像-文本匹配(ITM)和掩码语言建模(MLM)。在 ITC 任务中,VLMo 模型以双塔结构对图像和文本进行嵌入。在 ITM 和 MLM 任务中,VLMo 模型以融合编码器的形式,分别提取图像和文本的特征,并通过 MoME Transformer 进行模态融合。VLMo 模型使用不同的 FFN 层参数来计算不同任务的损失函数,并更新对应的参数。
VLMo 模型的优势之一是其灵活性。在训练阶段,根据任务的不同使用不同的结构计算损失函数,并更新对应的参数。这样的训练过程需要多次模型前向计算,但在推理阶段,灵活性的优势得到了体现。对于检索类任务,可以使用单独的文本/图像编码器提取特征,提高处理效率;而对于推理类任务,可以通过图文编码器进行充分的模态交互。这种设计巧妙地解决了传统视觉-语言模型中双编码器和融合编码器之间的冲突。

另一个 VLMo 模型的优化是引入大规模的图像和文本数据进行分阶段的预训练。首先,在图像数据上训练视觉专家和自注意力层的参数;然后,在文本数据上训练文本专家的参数;最后,在多模态数据上训练自注意力层和三种专家的参数。通过这种分阶段的预训练策略,VLMo 模型能够学习到更具泛化能力的表示。
5 BLIP:理解、生成我都要
文章的研究动机:
- 现有的预训练模型通常在理解型任务或生成型任务中表现出色,但很少有模型能够同时在这两种任务上达到优秀的性能。
- 现有的性能改进主要是通过扩大数据集规模并使用从网络收集的带有噪声的图像-文本对进行训练实现的。然而,网络数据集中的噪声会对模型的性能产生负面影响。
主要的贡献:
- 统一了图像-语言的理解与生成任务
- Bootstrap 的方式清洗网络噪声数据
在模型的设计上结合了 ALBEF 和 VLMo,看下图中红色框中就类似 ALBEF,只是画 image-grounded text encoder 的位置不同;蓝色框中类似 VLMo,虽然有三个模型,但是大部分参数都是共享的。

- 左一为 Image Encoder(图像编码器):该组件使用 Vision Transformer(ViT)对图像进行编码,将全局图像特征表示为一个额外的[CLS]标记。
- 左二为 Text Encoder,采用了 BERT 的结构,提取文本特征用于与视觉特征计算 ITC loss。Text Encoder 不与视觉特征计算交叉注意力。
- 左三为 Image-grounded Text Encoder(基于图像的文本编码器),该组件通过在每个 Transformer 块的自注意力(Self-Attention)层和前馈神经网络(Feed Forward Network)之间插入一个交叉注意力(Cross-Attention)层,将视觉信息注入到文本编码中,提取文本特征用于计算 ITM 损失。
- 左四为 Imagegrounded Text Decoder(基于图像的文本解码器),用于进行 LM 语言建模训练(这里不再是用 MLM 了),生成与图像相关的文本描述。
- 三个文本编解码器分别为在文本前添加 [CLS]、[Encode]、[Decode] token
- 与 ALBEF 一样,同样采用动量模型为 ITC 生成伪标签;使用 ITC 为 ITM 进行难负例挖掘。
BLIP 的训练流程

- 使用含噪声的数据训练一个 MED(Multimodal Mixture of Encoder-Decoder)模型;
- 将该模型的 Image-grounded Text Encoder 和 Image-grounded Text Decoder 在人工标注的 COCO 数据集上进行微调,分别作为 Filter 和 Captioner;
- Captioner 根据图像数据生成对应的文本描述;
- Filter 对噪声较大的网络数据和生成数据进行过滤清洗,得到较为可靠的训练数据;
- 再根据这些可靠的训练数据,训练更好的 MED 模型,从而实现 bootstraping 训练。
?6 CoCa: 让模型训练得更快一点
CoCa 将解决图像或多模态问题的模型概括成 3 种经典结构,分别是 single-encoder model、dual-encoder model、encoder-decoder model。Single-encoder model 指的是基础的图像分类模型,dual-encoder model 指的是类似 CLIP 的双塔图文匹配模型,encoder-decoder model 指的是用于看图说话任务的生成式模型。

CoCa 的出发点就是将三种类型的模型结构进行统一,它是 ALBEF 的后续工作,从结构上看来,都是左侧处理图像,右侧文本从中间劈开,前半段处理文本,后半段进行不同模态的融合。与 ALBEF 最大的不同在于 CoCa 右侧处理文本和进行多模态融合的网络是一个 decoder 而非 encoder。

在模型的训练上,看名字就能知道它是使用对比损失和文本生成损失进行训练,也就是使用了 ITC 和 LM loss;这里没有使用 ITM loss,减少了模型参数每次迭代所需前向传播的次数,从而降低了训练时间。
7 BEITv3:图片也是一种语言
BEITv3 的主要想法就是希望统一多模态学习中的模型结构、预训练任务以及模型规模。为此将图片也看作一种语言(Imglish),图像文本对看作是 parallel sentences。在输入形式统一之后,也就不需要 ITC、ITM、MLM、WPA 等其他目标函数,而是可以使用统一的 masked “language” modeling 的方式进行训练。
BEITv3 的模型结构使用的是 Multiway Transformer (其实就是前面 VLMo 的 MoME),因此也就具备了之前提到的灵活性的特点,可以适用于非常多的下游任务。

文章使用了一个统一的预训练任务:masked data modeling。该任务涉及到对单模态数据(如图像和文本)以及多模态数据(如图像-文本对)进行掩码操作,并训练模型来恢复被掩码的标记。
- 文本数据使用 SentencePiece tokenizer 进行 tokenize
- 图像数据使用 BEIT v2 的 tokenizer 进行 tokenize,以获得离散的视觉 token 作为重构的目标
- 当输入数据是纯文本时,掩码的比例是 10%
- 当输入数据是纯图像时,使用 block-wise 掩码策略,掩码的比例是 40%
- 当输入数据是图文对时,会对文本的 50%进行掩码
到这里时,其实已经呈现了一个趋势,多模态模型的规模在不断扩大,训练用的数据规模也在扩大,虽然这一定程度上对性能有利的,但是端到端训练的成本也会随之增加。
此时也就会有另外一种思考,有没有什么高效的对齐方法,直接利用已经预训练好的视觉、文本模型就能快速对齐,完成对模态任务。
8 BLIP2:将图像特征对齐到预训练语言模型
BLIP-2 通过在冻结的预训练图像编码器和冻结的预训练大语言模型之间添加一个轻量级 查询 Transformer (Query Transformer, Q-Former) 来弥合视觉和语言模型之间的模态隔阂。在整个模型中,Q-Former 是唯一的可训练模块,而图像编码器和语言模型始终保持冻结状态。

Q-Former 由两个子模块组成,这两个子模块共享相同的自注意力层:
- 与冻结的图像编码器交互的图像 transformer,用于视觉特征提取
- 文本 transformer,用作文本编码器和解码器

图像 transformer 从图像编码器中提取固定数量的输出特征,这里特征的个数与输入图像分辨率无关。同时,图像 transformer 接收若干查询嵌入作为输入,这些查询嵌入是可训练的。这些查询还可以通过共享的自注意力层与文本进行交互。
Q-Former 分两个阶段进行预训练。 第一阶段,图像编码器被冻结,Q-Former 通过三个损失函数进行训练:
- ITC loss
- ITM loss
- Image-grounded Text Generation (ITG) loss:用于训练 Q-Former 模型在给定输入图像条件下生成文本。在注意力机制上,queries 之间互相可见但是不能看到文本 token,而文本 token 可以看到所有的 queries 以及它之前的文本 token。此外将 CLS token 替换为 DEC token 以便提示模型进行解码任务。
通过第一阶段的训练,Query 已经能够理解图片的含义了,接下来就是让 LLM 也能够理解图片信息,因此作者针对两类不同 LLM 设计了不同的任务:
- Decoder 类型的 LLM(如 OPT):以 Query 做输入,文本做目标;
- Encoder-Decoder 类型的 LLM(如 FlanT5):以 Query 和一句话的前半段做输入,以后半段做目标;因为不同模型的 embedding 维度不同,所以这里还加上了一个全连接层。

BLIP2 验证了之前的想法,直接利用已经预训练好的视觉、文本模型,通过设计参数量较少的“对齐模块”来实现多模态的对齐。
然而,注意到 BLIP2 在抽视觉特征其实是不考虑文本的;此时也正值 指令微调 在大语言模型中大杀四方,因此进一步的发展方向也就诞生了。
9 InstructBLIP:指令微调大杀四方
InstructBLIP 可以理解为是 BLIP2 + 指令微调
- 作者们收集了 26 数据集并转化指令微调的格式
- 并改进 BLIP2 中的 Query Transformer 为 指令感知的 Query Transformer,能够抽取和给定指令相关的信息
InstructBLIP 的模型结构如下所示:

可以看到 Q-Former 的输入部分多了 Instruction,指令可以通过 Q-Former 的自注意力层与查询嵌入进行交互,并鼓励提取与任务相关的图像特征。
10 MiniGPT-4:LLM 助力多模态
对于 GPT4 能够具有超强的图文理解能力,作者们的理解是这是得益于大语言模型的能力,因此考虑将最新的一些能跟 ChatGPT “媲美”的语言模型引入其中,这里采用了 Vicuna 作为语言模型,在视觉理解上,作者采用了和 BLIP2 里面一样的视觉模块,包含一个 ViT 模块和一个 Q-Former 模块。模型的整体框架如下所示,我们从下往上看:首先一张图片会经过视觉模块(ViT&Q-Former)进行编码得到一个图像 embedding,由于视觉模块给出的 embedding 不能够直接被语言模型理解,因此一般需要将视觉 embedding 和文本 embedding 进行对齐,这里加入了一个线性层,可以理解为这里假设图片编码器得到的输出经过一个线性层后就能够被语言模型理解了,然后将原始的文本信息和经过对齐后的图像信息拼接起来,送入 LLM,就可以实现能够接受多模态信息的 GPT 了。

对于这样一个模型如何进行训练呢?我们可以看到模型架构中视觉模块和 LLM 模块都有个“冷冻”起来的标志,这表示这两个模块的模型参数是固定的,也就是不进行更新的,可以理解为这两个模块继承了原来的视觉模块和 LLM 模型的能力;需要训练的地方只有线性层,通过训练这一层线性层实现图像 embedding 向文本 embedding 的转化。
要实现图像和文本信息的“对齐”自然需要相应的数据集,数据集还必须是那种图像-文本对的形式,这里采用了 Conceptual Caption、SBU、LAION 三个数据集和混合,大概 5million 的图像-文本对来进行模型的训练。这其实这是 miniGPT4 第一阶段的训练,因为作者发现这样训练完后让模型进行生成的文本缺乏连贯性,会出现一些比如重复或者断断续续的情况。
进一步,作者借助 ChatGPT 来修正一些描述,按照设计的对话模板构造了一个大约 3000 个图像-文本对的高质量数据集用于第二阶段的训练。
此时的感受就是:大语言模型牛 X、高质量数据牛 X,一些基于开源 LLM 进行修改的多模态大模型也开始百花齐放
11 Visual Instruction Tuning:继续将指令微调发扬光大
LLaVA 模型的结构包括两个主要组件:视觉编码器和语言模型。
- 视觉编码器:LLaVA 中使用的视觉编码器基于 CLIP(ViT-L/14 变体)。在 LLaVA 中,视觉编码器接收输入图像(
)并使用 ViT-L/14 模型生成视觉特征(
)。然后,使用可训练的投影矩阵(
),将这些视觉特征转换为语言嵌入标记(
)。这个投影矩阵使得图像特征能够与语言模型的词嵌入空间对齐。

- 语言模型:LLaVA 中使用的语言模型为 LLaMA。语言模型接收由视觉编码器生成的语言嵌入标记(
)作为输入,并根据这些输入生成文本输出。

训练模型的输入序列构造:

LLaVA 模型的训练过程分为两个阶段:
- 阶段 1:视觉编码器和 LLM 权重被冻结,可训练的参数是投影矩阵(W)
- 阶段 2:端到端微调
最近的升级版本 LLaVA-1.5

主要做了几点优化:
- 使用单一的响应格式提示语,明确指示输出格式。例如,“Answer the question using a single word or phrase.”这样的提示语可以促使 LLM 根据用户的指示正确调整输出格式。
- vision-language 的 connector 使用一个两层的 MLP
- 额外使用一些学术任务导向的数据集
- 扩大 LLM 的参数规模、图像的分辨率等
12 VisualGLM
没有放出相关的论文,这是一次分享中的 PPT,可以看到和前面的做法大同小异:

13 CogVLM:视觉优先再现江湖
这是 VisualGLM 的升级版,但是放弃了 VisualGLM 的一些思想,这里的主要思想回归 LLM 前的多模态研究思路:更大的图像编码器可能是有效的,也就是视觉优先。
模型的结构如下所示:

- 图 a 可以看到跟之前的方法类似,图像经过图像编码器后经过一个浅层的 MLP 来向文本对齐
- 图 b 可以看到在语言模型中新增了视觉专家模块(图像的 QKV 矩阵和 FFN 层),以实现深度视觉-语言特征对齐
- 这设计有一点前面 VLMO 的味道,但本质又不一样
14 MiniGPT-5:多模态生成是未来
之前的工作大多是考虑的是多模态理解(看图说话),最近刚提出的 MiniGPT-5 则想着直接多模态同时生成(同时生成文本和图片)。
图片生成的话用 Stable Diffusion 来做是个比较常规的操作了,简单回忆下 Stable Diffusion 怎么做的,其实就是一个 Unet 接收加噪的图片、时间步长、以及文本的 token embedding 来进行生成,这里的文本编码器来自于 CLIP,那多模态发展得风风火火,把这里的文本编码器换成新一点的模型是不是可行?

答案是可以的,MiniGPT-5 本质可以理解为就是将 Stable Diffusion 中的 CLIP 文本编码器替换成 MiniGPT-4,从而实现文本、图像同时生成。

为了能够将 MiniGPT-4 和 Stable Diffusion 中 Unet 完美结合起来还需要对模型结构进行一定的修改:
- 为了 LLM 的词表添加了用来表示图像的 token,称为 generative vokens
- 为了将 MiniGPT-4 的输出 embedding 输入到 Unet,用一个 MLP+Transformer 进行了映射(上图中间红色框部分)
这样一个复杂的模型要训练起来肯定是费劲的,除了让模型要同时理解图像和文本的对应关系,再生成的时候还要保证一致性,作者也是提出了一个两阶段训练的方式。
- 第一阶段除了考虑文本生成的 loss、图像生成的 latent diffusion model loss,还要 SD 的文本编码器的输出对 generative vokens 进行了引导
- 第二阶段使用更复杂的数据和任务来进行微调,只考虑了文本生成的 loss 和图像生成的 loss
- 因为训练涉及到图像生成,所以也用了 Classifier-free Guidance 来提升条件扩散模型的性能
15 GPT-4V:远远领先!
openai 还是保持着 closeai 的风格,关于 GPT-4V 的模型以及训练相关的细节并没有公布,只有一份微软的测评论文,从结果上来看是远远领先。
看完两个模态的多模态工作,我们再来看看如何扩展到更多的模态
16 ImageBind:更多模态一起对齐
ImageBind 的目标是将不同模态的 embedding 对齐到一个公共的空间,可以理解为是 CLIP 的多模态版本。
文章的主要思想是通过图片作为桥梁来将不同模态的数据关联起来。

假设每个模态有个自己的编码器,编码器输出加一个映射层来对齐 embedding 的维度,然后就跟 CLIP 一样用对比学习来训练就可以了。

这里表示的是图片的 embedding,
是和图片对应的其他任意模态的 embedding。
ImageBind 考虑的主要是不同模态的对齐,那如何进行一些多模态的下游任务呢?
17 Meta-Transformer:未来就是要统一
Meta-Transformer 野心就比较大了,同时考虑了 12 种模态。

它的主要思想是使用一个统一的框架来处理来自多种模态的数据,而无需为每种模态设计特定的模型或网络。通过将所有模态的数据映射到一个共享的 embedding 空间,并使用一个公共的编码器来提取特征。
- 统一的 Tokenization:通过设计特定的 Tokenization 策略,例如将图像分割成小块或将文本分割成词或子词,然后为每个块或词生成一个 token。这些 token 然后被映射到一个连续的向量空间,形成 token embedding;
- 模态共享的编码器: 使用一个预训练的 Transformer 编码器,它的参数是冻结的。这个编码器可以处理来自不同模态的 token embedding(因为它们都在同一个共享的流形空间内);
- 任务特定的头部:这些头部通常由多层感知机(MLP)组成,并根据不同的模态和任务进行调整。

18 总结
多模态的研究做的事情主要是:
- 不同模态进行对齐
- 不同模态进行融合
- 指令微调促进人机交互,数据的质量可能比数量更重要
- 模型设计既要保证检索任务下的高效推理,又要能够进行多模态深度融合
- 进入大语言模型时代前,用更大的图像编码器一般是更有效的
- 进入大语言模型时代后,图文理解能力的强大可能来自于大语言模型的能力
- 进入大语言模型时代后,视觉优先仍然是值得探索的方向,但是训练大视觉模型向来是比较困难的
- 想要在多模态理解的基础上扩充多模态生成能力需要设计不同模态对应的解码器
- 理想的框架:多模态对齐+统一的编码器+统一的解码器,一举拿下多模态理解和生成
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!