使用torch解决线性回归问题
2023-12-15 11:29:27
-
数据处理
import torch
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
data=pd.read_csv('./datasets/Income1.csv') #数据准备
data.head(5)#展示数据
#以上所有的代码都是用jupyter notebook写,形成了阶段性的结果展示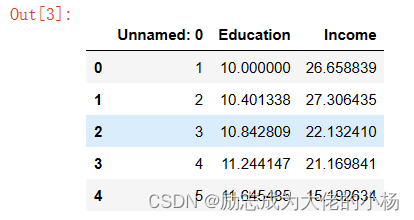
查看数据信息
data.info()
绘制数据的散点图
plt.scatter(data.Education,data.Income) #绘制散点图
plt.xlabel('Education')
plt.ylabel('Income')
plt.show()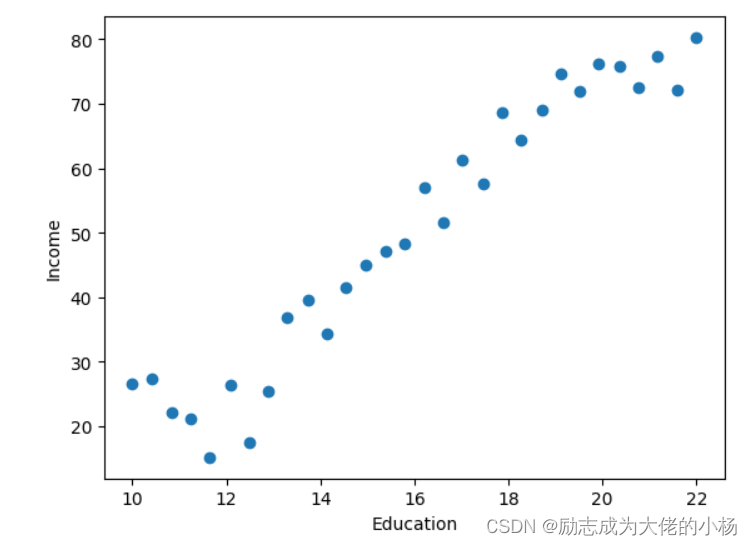
数据转换
X=torch.from_numpy(data.Education.to_numpy().reshape(-1,1)).type(torch.FloatTensor)
Y=torch.from_numpy(data.Income.to_numpy().reshape(-1,1)).type(torch.FloatTensor)上面一行代码首先通过data.Education获取受教育年限这一列,使用to_numpy()方法将其转换为ndarrray数组形式,然后使用reshape方法将其形状设置为二维数组,并且将最后一个维度明确为1。
展示数据的形状
print(X.size(),Y.size())![]()
查看数据集的形状如上图所示,目前数据集是二维的,最后一个维度为1,代表单条数据的长度,前面的30代表数据的个数,所以X和Y这两个数据集的形状可以理解为输入X是30个长度为1的数据,输出Y也是30个长度为1的数据。
模型建立与数据训练
编写训练类
from torch import nn #nn.Module是PyTorch的高阶API
class EIModel(nn.Module):
def __init__(self):
super(EIModel,self).__init__() #继承父类的属性 重写init的方法有两种 一.super(子类,self).__init__() 二.父类.__init__(self)
self.linear=nn.Linear(in_features=1,out_features=1)#创建线性层
def forward(self,inputs):
logits=self.linear(inputs) #在输入上调用初始化的线性层
return logits因为当前模型是一个简单的线性回归模型,只有w和b两个参数,在__init__()方法中,使用nn.Linear()方法初始化一个线性连接层,nn.Linear有两个参数,即in_features和out_features,分别代表输入和输出维度的大小,根据X和Y的size()方法,我们可以输入和输出的维度大小都为1.
创建EIModel对象
model=EIModel() #创建一个ETModel对象这里的模型就是一个最简单的线性层,也就是所谓的一个线性函数,只有w和b两个参数,接下来是我们定义计算损失函数,并且根据损失值进行梯度优化,优化模型参数
构建损失函数
loss_fn=nn.MSELoss() #定义了均方误差损失来计算损失函数
opt=torch.optim.SGD(model.parameters(),lr=0.0001) #初始化一个优化器第一行代码就是用了PyTorch中内置的均方误差来计算损失函数,第二行初始化了一个内置的优化器,第一个参数为需要优化的变量,通过model.parameters()方法可以获取模型中的所有变量,优化器中参数lr为学习率,也就是在计算梯度时用到的alpha。
迭代训练
for epoch in range(5000): #对全部的数据训练5000次
for x,y in zip(X,Y): #同时对X和Y迭代
y_pred=model(x) #调用model得到预测输出y_pred
loss=loss_fn(y_pred,y) #根据模型预测输出与实际的值y计算损失
opt.zero_grad() #将累计的梯度置为0
loss.backward() #反向传播损失,计算损失与模型参数之间的梯度
opt.step() #根据计算得到梯度优化模型参数
print("Down!")模型训练代码有一行opt.zero_grad(),是因为PyTorch会累计每次计算的梯度,使用此代码将上一循环中计算的梯度置为0
展示参数
print(list(model.named_parameters()))#以生成器的形式返回模型参数的名称和值
模型效果展示
#绘制原数据分布的散点图
plt.scatter(data.Education,data.Income,label='real data')
#用我们训练出来的参数,来绘制直线
plt.plot(X,model(X).detach().numpy(),c='r',label='predict line')
plt.xlabel('Education')#设置x轴的标签
plt.ylabel('Income')#设置y轴的标签
plt.legend()#可以显示图例
plt.show()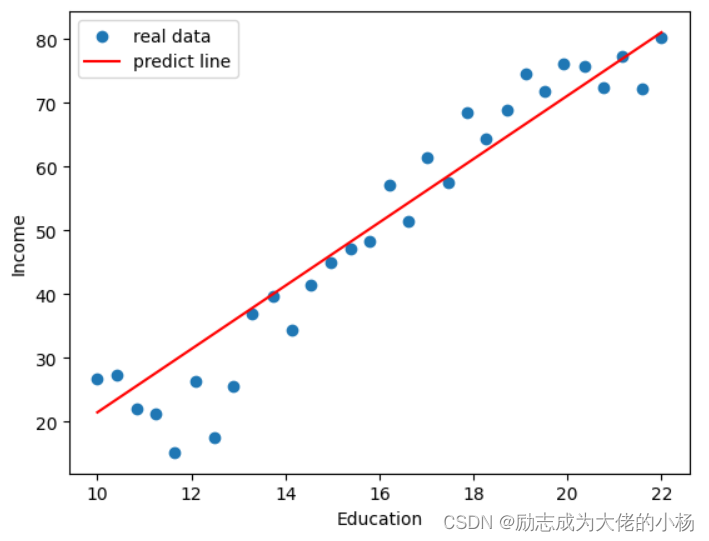
文章来源:https://blog.csdn.net/xiaoyang01234/article/details/134938827
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!