大数据----32.hbase高可用的演示
1、概述:Hbase的优缺点和适用场景
优点:HBase 底层基于HDFS存储,高可用、高扩展、强一致性,支持上亿级别数据。
10亿数据 性能测试结果
-
写性能:集群吞吐量最大可以达到70000+ ops/sec,延迟在几个毫秒左右。网络带宽是主要瓶颈,如果将千兆网卡换成万兆网卡,吞吐量还可以继续增加,甚至达到目前吞吐量的两倍。
-
读性能:很多人对HBase的印象可能都是写性能很好、读性能很差,但实际上HBase的读性能远远超过大家的预期。集群吞吐量最大可以达到26000+,单台吞吐量可以达到8000+左右,延迟在几毫秒~20毫秒左右。IO和CPU是主要瓶颈。
-
Range 扫描性能:集群吞吐量最大可以达到14000左右,系统平均延迟在几毫秒~60毫秒之间(线程数越多,延迟越大);其中IO和网络带宽是主要瓶颈。
缺点:
占用内存很大,且鉴于建立在为批量分析而优化的HDFS上,导致读取性能不高
2、高可用
HBase集群如果只有一个master,一旦master出现故障,将导致整个集群无法使用,所以在实际的生产环境中,需要搭建HBase的高可用,也就是让HMaster高可用,也就是需要再选择一个或多个节点也作为HMaster,但是只有一个是active,其他的都为backup master当active的master宕机时,从backup master中选举一个作为active。
zookeeper管理节点实例:
当前的集群中是通过zookeeper来进行项目的管理节点的;
他管理: hadoop06;(主节点)hadoop07(从节点); hadoop08(从节点)
我们的hbase的原数据都是存储到zookeeper中的;
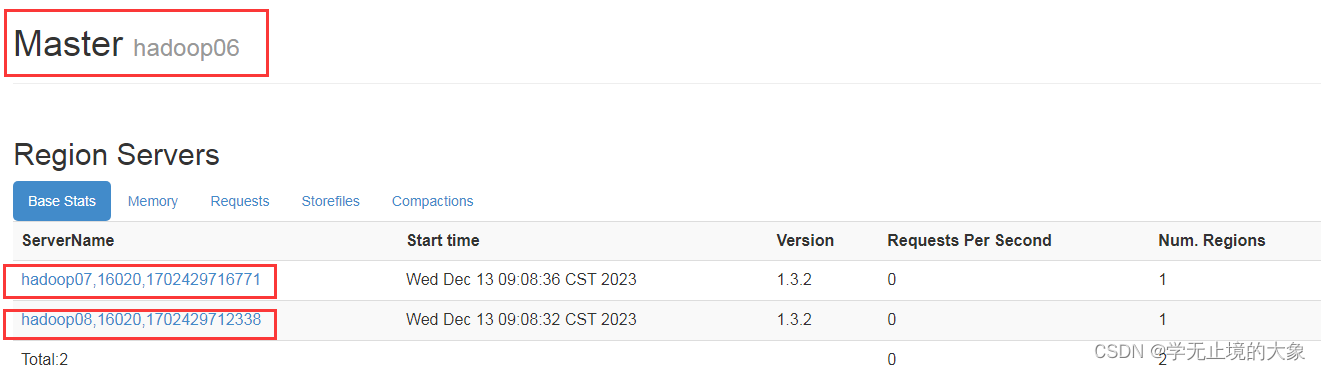
原数据存储位置:


这个时候我们看到他的数据是存储在hadoop07上的;

现在如果我们把hadoop07上的 hbase进行关闭;把他上面的zookeeper关闭;
那么出现的效果就是zookeeper会把hadoop08上进行存储元数据;

通过命令结束 他上面的进程;
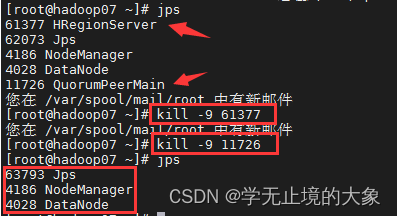
这个时候由zookeeper来管理;直接让hadoop08来管理元数据

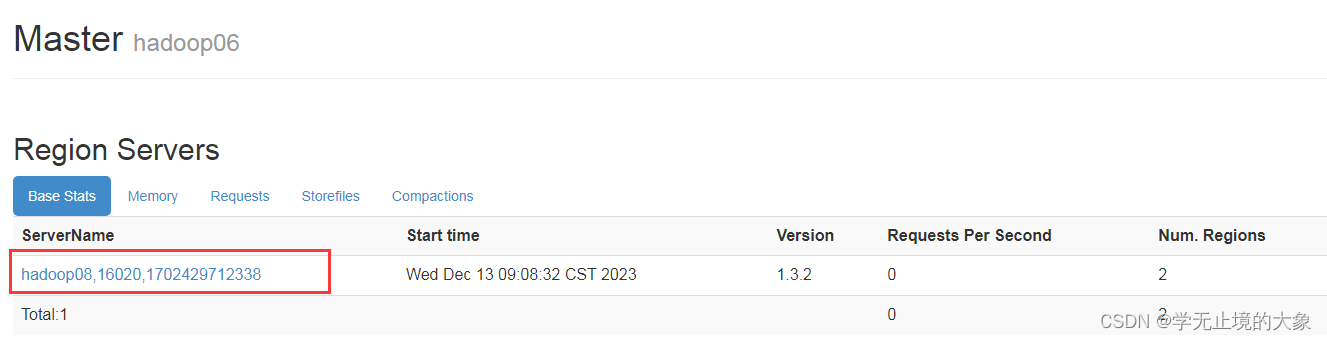
如果这个时候再一次启动我们的hbase和zookeeper 看看结果;

[root@hadoop07 bin]# ./hbase-daemon.sh start regionserver

已经启动:

但是看到的结果我们的hadoop08还是作为元数据来进行:
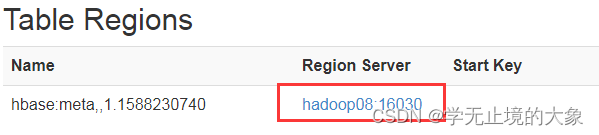
如果想再次返回给hadoop07; 就需要再hadoop08上进行结束那两个进程;然后后面启动;同上面一样; (也可以不对我们的zookeeper关闭)
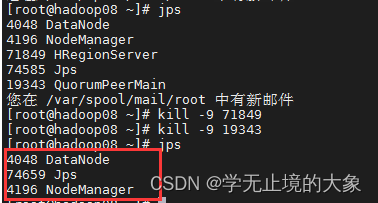

[root@hadoop08 bin]# ./hbase-daemon.sh start regionserver

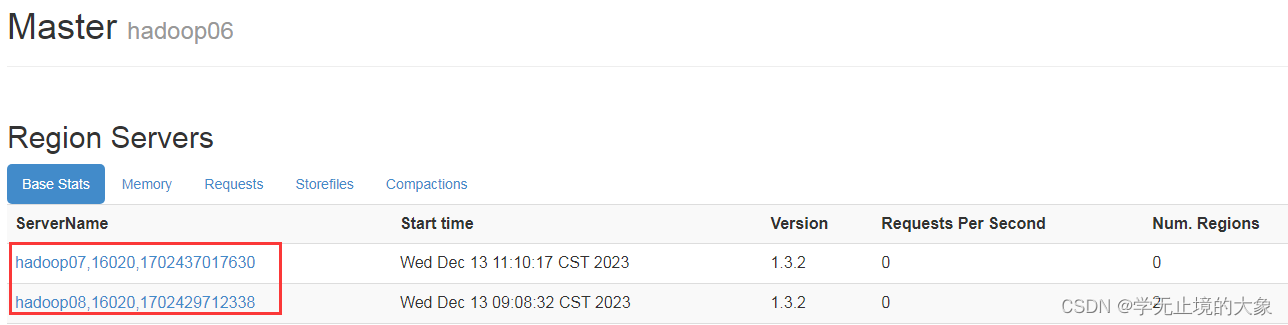
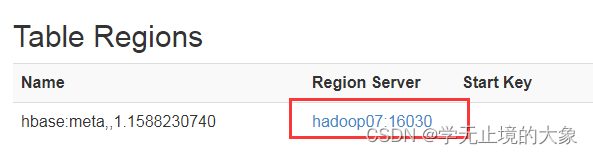
这个时候他就会把这个元数据放到hadoop07上;
hbase高可用的例子:
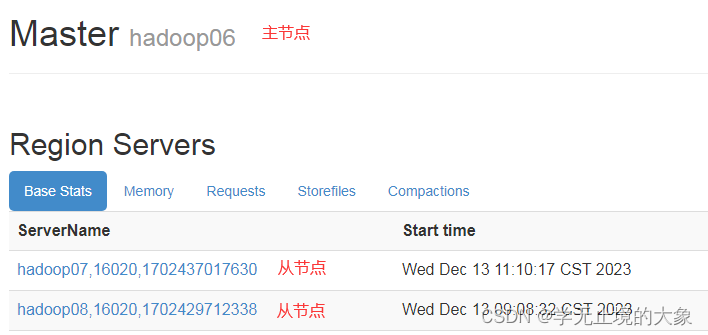
如果hadoop06这个节点突然死掉了; 那么zookeeper就会通过选举机制来从新现在一个主节点; 即使hadoop06启动了;他也不会把主给到他;
那么我们怎样设置高可用的hbase那?
需要之前的操作

然后再我们要进行接替的节点上进行启动:
现在的主节点是 hadoop06;
我们在hadoop07的节点上启动备用节点:
[root@hadoop07 bin]# ./hbase-daemon.sh start master

这个地方是在主节点上进行环境变量的设置;没有同传给其他的两个节点; 需要我们自己手共来进行启动; 简单的话;就把hadoop上的文件同传到其他节点:
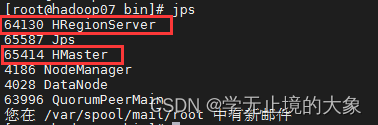
使用web就可以访问:
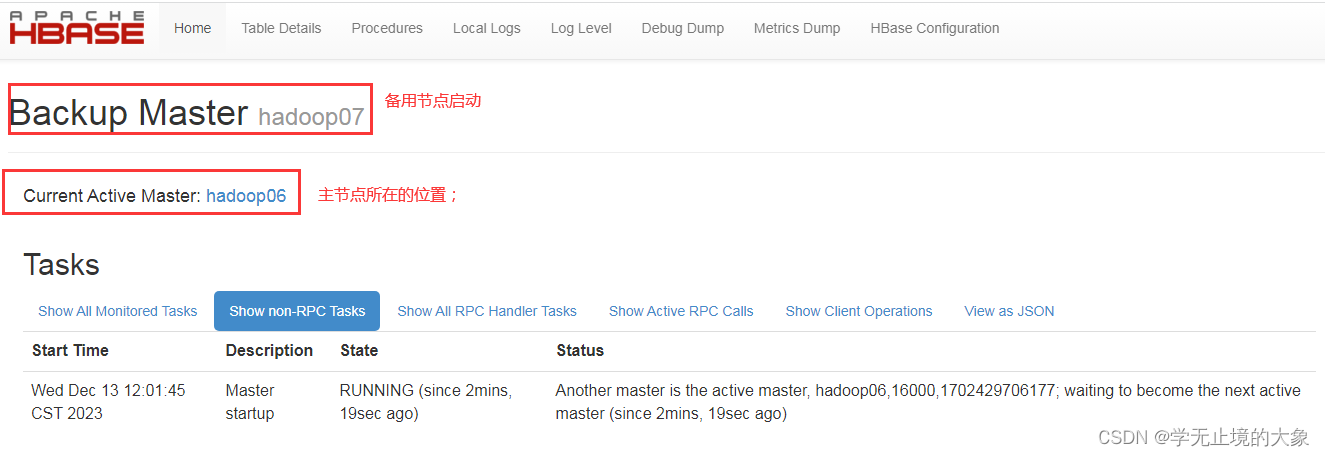
这个时候如果hadoop06的这个节点上的服务器死掉了;就会自动的hadoop07就会接管他的主节点:
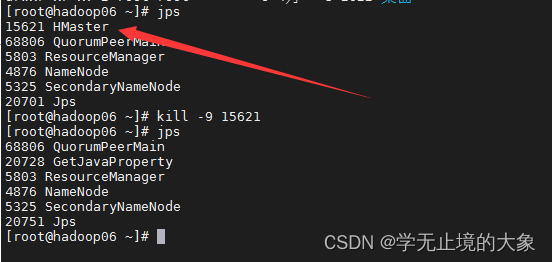
这个时候访问就访问不到hadoop06:
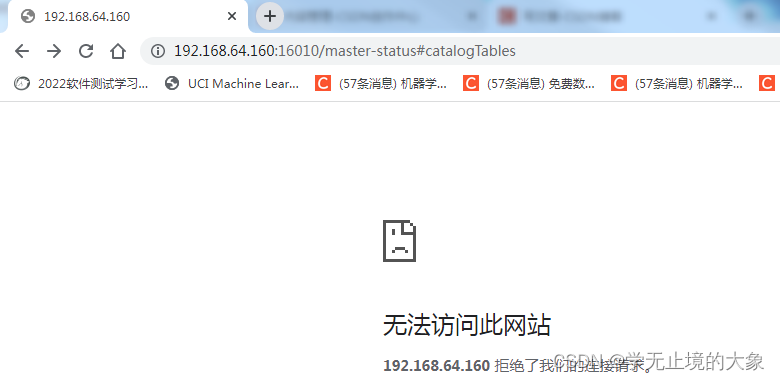
这个时候 hadoop7就接管了hadoop06的主节点:
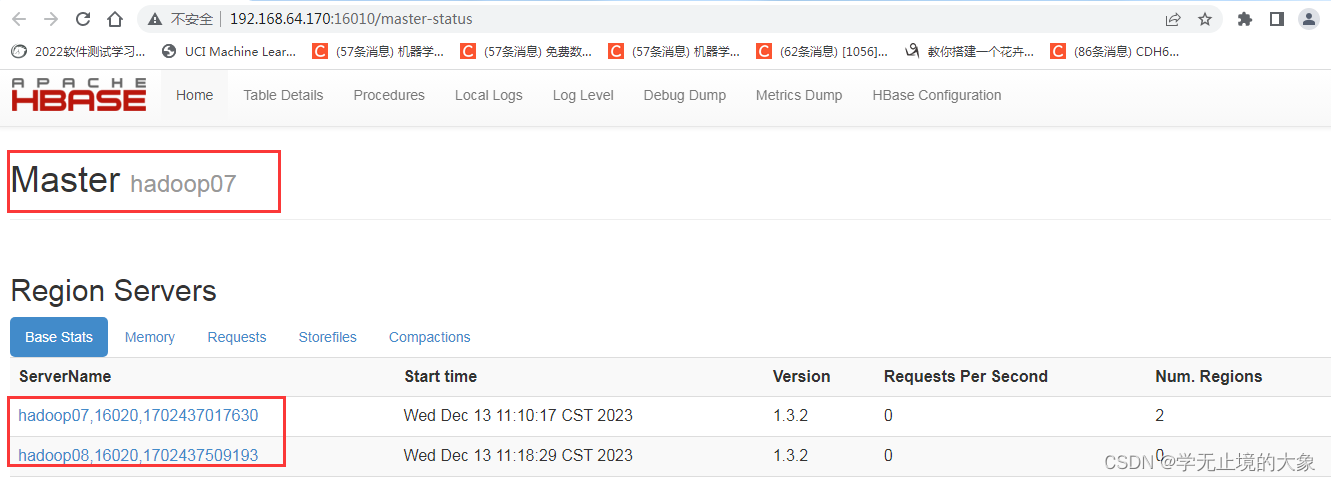
以上就实现了我们的高可用;
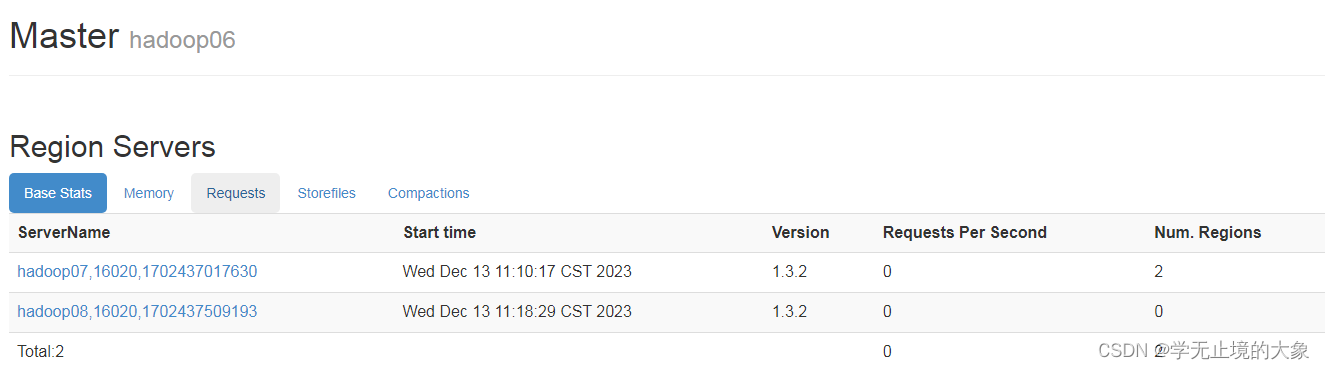
如果你还是想让hadoop06做主节点:
在hadoop06上进行启动主节点即可;
[root@hadoop06 ~]# hbase-daemon.sh start master


注意: 为了命令的执行好;可以同传我们的环境变量的文件到其他的两台机器中去;
scp –r /etc/profile hadoop07:/usr/
scp –r /etc/profile hadoop08:/usr/’
更新环境变量
source /etc/profile‘’
即可
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!