【Hadoop】Zookeeper架构/特点
2023-12-25 07:27:32
Zookeeper 中的角色主要有以下三类:

- Zookeeper需要保证高可用性和强一致性
- 为了支持更多的客户端,需要增加更多Server,但是Server增多,意味着投票阶段延迟增大,会影响整个系统的性能。所以在3.3.0中ZK引入的新角色:Observer
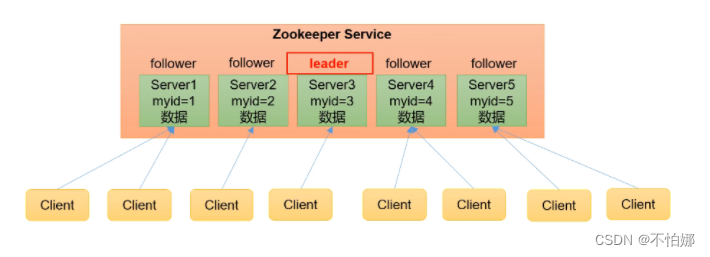
- Zookeeper是由一个Leader,多个Learner组成的集群。客户端如果发来写请求(更新操作),要交给Leader来处理,如果是读请求,那么让Leaner来处理。这就要求leader和Leaner之间要同步。
- 集群中只要有半数以上节点存活,Zookeeper集群就能正常服务。所以Zookeeper适合安装奇数台服务器。
- 全局数据一致:每个Server保存一份相同的数据副本,这样就保证了Client无论连接到哪个Server,数据都是一致的。
- 更新请求顺序执行:来自同一个Client的更新请求按其发送顺序依次执行。就相当于队列先进先出。
- 数据更新原子性:一次数据更新要么成功,要么失败。
- 实时性。在一定时间范围内,Client能读到最新数据。一个客户端向服务器写数据了,那其他服务器什么时候拿到数据,这就是同步问题。Zookeeper的同步时间是非常快的。因为每个节点的数据量很小,所以在传输的时间就短。
文章来源:https://blog.csdn.net/m0_60511809/article/details/135096933
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!