Efficient Classification of Very Large Images with Tiny Objects(CVPR2022补1)
文章目录
Two-stage Hierarchical Attention Sampling
一阶段缩放是hw,提取的特征是h1w1,
二阶段缩放是uv(在hw的基础上),提取的是h2*w2
One-stage

在第一阶段,注意力网络a Θ(·)为输入图像生成一个注意图(按s 1的比例缩小),其中N个块被替换采样() 在第二阶段,注意力网络bΘ(·)为每个选择的块生成一个注意图,并选择一个子块,因此选择了N个子块(不替换)。然后将所有子块馈送到特征提取器fΘ(·),使用其相应的注意力权重对特征映射进行聚合,并使用分类模块g Θ(·)从聚合的特征中获得预测
定义Ts1(x,c)函数从输入图像x∈R(H×W)中提取一个大小为h1×w1的块,并将其放置在低分辨率视图V(x,s1)∈R(h×w)中的位置c={i,j}处。
即:Ts1(x,c)将坐标通过[?(i?1)(W?1)/(w?1)?,?(j?1)(H?1)/(h?1)?]映射到x hw中的一个位置, 并返回一个大小为h1×w1的块。
s1是缩放因子,s1∈(0,1),h = s1H,w = s1W。
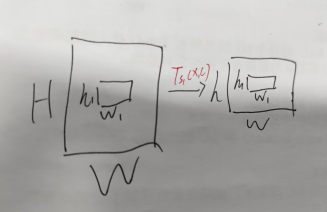
好,第一个问题:为什么通过[?(i?1)(W?1)/(w?1)?,?(j?1)(H?1)/(h?1)?]进行特征映射呢?
在这个过程中,Ts1(x,c) 的作用是对全分辨率H×W输入x中的一块区域 h1×w1 做特征提取,这里的c={i,j} 表示这块区域相对于全分辨率图像 x 的坐标。所以 [i-1,j-1]分别表示了相对应的行号和列号。
接下来,Ts1(x,c) 将把 x HW 上的像素转换为其相应的小尺度版本 x hw,这一步骤是为了降低计算成本。因为随着尺度变小,所需的内存和时间也会大大减小。
至于为什么要乘以(W-1)/(w-1) 和 (H-1)/(h-1),这是因为在图像缩放的过程中,保持纵横比不变是很重要的。也就是说,尽管图像的高度和宽度都发生了改变,但我们希望确保图像的比例仍然保持一致。这两个分数确保了在缩放到新尺度时,图像的长宽比例不会发生显著变化。
需要注意的是:(i)这种策略只依赖于x和s1的尺寸,而不取决于tile的大小; (ii)要求h1,w1>1/s1以保证对x进行全面覆盖; (iii)我们已经忽略了颜色通道维度,但在我们的实验中考虑了彩色图像(具有额外的一个维数)。
最后,提供注意力机制如下:


所以(2)就是添加了注意力机制后的分类器
接着作者提出了使用蒙特卡洛估计来避免计算由视角V(x,s1)暗示的所有|C|个可能的tiles的特性,这是因为如果原始输入x很大,则内存需求过高。为了利用Monte Carlo估算,在原输入图像上采样了一小部分tile,这些样本是由注意权重分布确定的独立同分布地进行选择的。因此,他们用一小部分来自大输入的tile代替所有可能的tiles来进行计算。这样做的好处是可以减少需要处理的数据量,从而提高效率。
可以通过从(1)到(3)采样近似估计(2)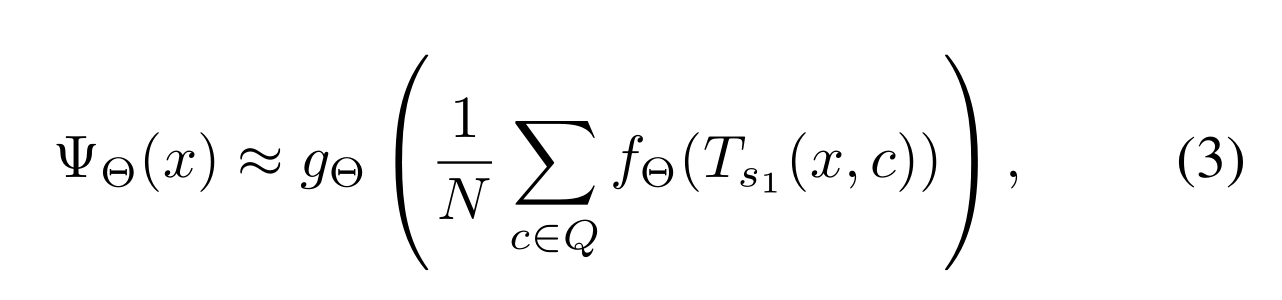
C是V(x,s1)全部索引对的集合,C=h*w
Q是从aΘ(V(x,s1))中提取的N个索引对
Two-Stage
V(x,s2,c)∈R uv 是将第一阶段缩放后的x hw在缩放因子s2∈(0,1)下的位置c处的视图
所以:u = s2 h = s2 s1H, v = s2 w = s2 s1W
进一步,Ts2(Ts1(x, c),c ')提取了一个子块h2×w2(从h1w1中)
具体来说,V(x,s?,c)是一个在尺度s?∈(0,1)下的图像x hw在位置c处的视图,其大小为u×v,其中u=s?h=s?s?H(高度)和v=s?w=s?s?W(宽度)。进一步定义了一个函数T??(T??(x,c),c’),它从在尺度s?下、位置c={i,j}的块T??(x,c)中–>再在尺度s?下的视图V(x,s?)的位置c’={i’,j’}处提取一个大小为h?×w?的子块。
这个映射函数T??(T??(x,c),c’)与T??(x,c)的定义类似,但返回的是尺寸为h?×w?而非h?×w?的子块 ,并且满足h? < h?, w? < w?以及h?,w2 > 1/s?的条件。
可以同(1)一样定义注意力机制

β是V(x,s1)在c处的注意力权重矩阵,Σc’∈C β‘c = 1 ,bΘ是注意力函数,|C’| = uv
C‘是V(x,s2,c)全部索引对的集合
由于V(x,s2,c)中的位置c’在全分辨率图像x中的对应位置为αcβc’(x–>αc—>βc‘),因此我们可以重写(2):

现在聚合表征是x中所有大小为h 2 ×w 2 子块的加权平均值,同(3)一样我们可以近似估计(5):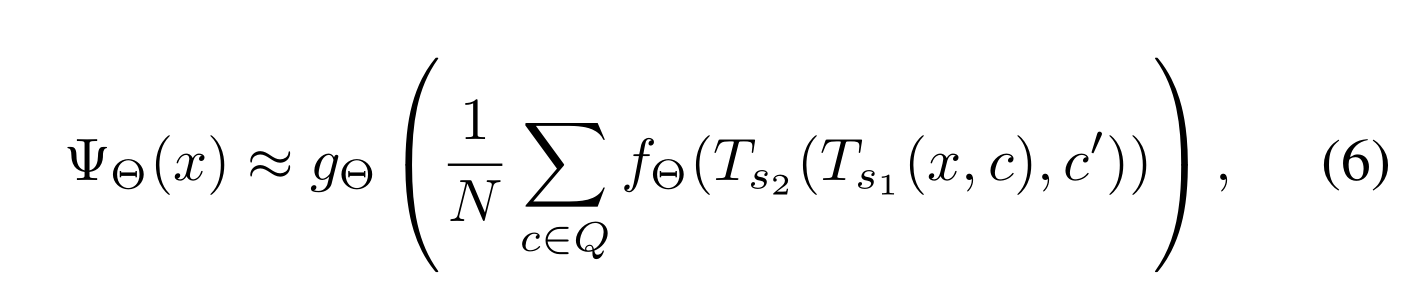
利用Gumbel-Top-K trick来获得无偏差的平均预期值的估计,我们可以重写(5):
这个估计器是由两层嵌套的求和组成,外层是对所有可能的选择c’进行遍历,内层则是针对每一个c’执行相应的操作。
具体而言,外层的求和作用在于考虑所有可能的c’,并将它们对应的注意力权重乘以fΘ(TS2(TS1(x,c),c’)) 并累加起来。这样做的目的是为了构建一个总体上的估计器,考虑到所有可能的c’的影响。
至于内层的求和,它是针对那些不是当前正在评估的c’'的所有c来进行的。也就是说,只有当c≠ c’时才会发生内部求和的操作。同时,**每一项都包含了注意力权重βcc’除以(1-βc‘)的部分,再加上剩余未使用的注意力权重 (1-βc’)。**最后,这两者的积就是对应于c的实际贡献到总估计器中的数值。
总的来说,这个公式展示了一种有效的方式来估计期望值,即使面对非独立同分布(non-iid) 数据的情况下也能保持良好的效果。
右边的和是左边期望的无偏差估计。或者,我们可以写为:
非iid(非独立同分布)意味着它的各个部分之间存在某种依赖关系或者是异方差性(即各部分的误差方差并不相等)。这样的特性可能会导致传统的学习算法无法很好地适应这类数据,Gumbel-Top-K trick在这里的作用是为了克服nond-iid数据带来的挑战,使我们能够高效地估算目标函数的期望值。
然后,式9在8的基础上进行了变换,我们可以像在(6)中那样近似(5),但使用采样而不替换:
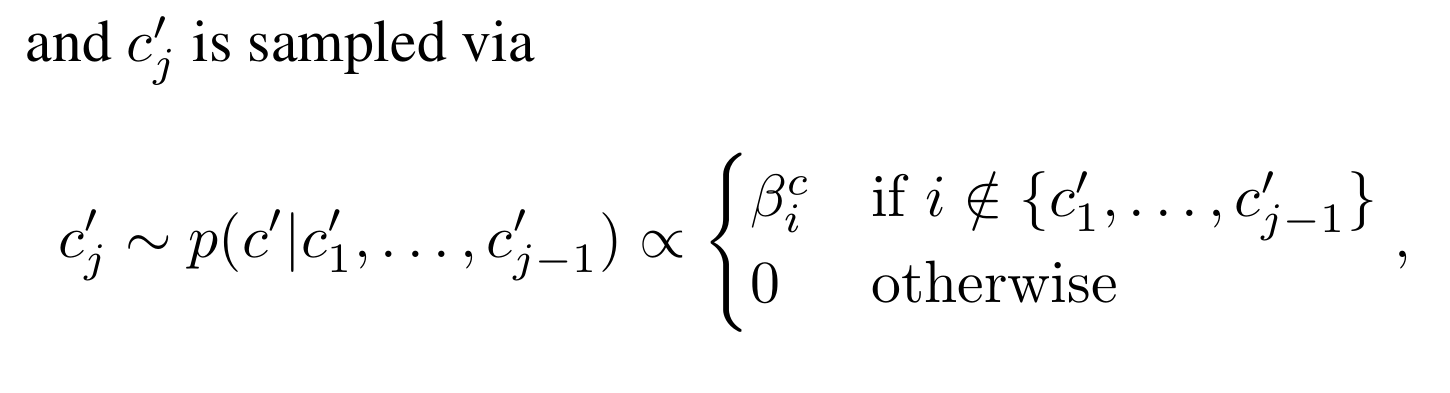
当i不属于 {c’1, …, c’j-1},时,c’j正比于βci采样,否则不采样,避免了重复采样
内存需求
具体而言,对于N个样本的推理,单阶段[20]和提出的两阶段分层模型,其峰值内存使用量分别为O(s2HW + Nh2w2)和O(s1 2 HW + N’ s1 2 s2 2 HW + Nh2w2)。N’ 来代表Q和s中唯一块的数量。事实上,通过选择s1 <s和s2=s,我们可以证明我们的模型比单阶段注意力采样需要更少的GPU内存。注意,在第一阶段,选择块的数量会随着注意力映射的优化而急剧减少,峰值内存这个术语用来表示最坏的情况。
Efficient Contrastive Learning with Attention Sampling
这种技术的主要目的是让分类器能够更好地识别出属于类别 y=1 的图像作为对比示例
具体来说,我们利用(1)和(4)中现有的注意力函数。为了生成图像x的对比特征向量,使y =1,类似(1)——我们首先通过1 - aΘ(V(x, s1))采样(替换)块位置,然后类似(4),我们通过1 -bΘ(V(x, s2,c))采样N个子块(无需替换)
采样的对比子块通过特征网络,然后由分类器处理,使用(9)进行预测ΨΘ(x|y =1),其中使用条件y =1来强调我们使用y =1类的图像x作为对比示例。一般来说,对比样例的数量(每个训练批次)等于y =1的样本数量。对于这些对比样本,我们优化了以下目标,Lcon(ΨΘ(x|y =1)) = Σn -log(1 - ΨΘ(xn | yn = 1))。请注意,Lcon(ΨΘ(x|y =1))鼓励对比示例对于标记为 y=1 的图像 x 能够正确预测为 y=0 类别。
**why?**这是因为作者想要提高模型区分正样本的能力,从而提升其性能。如果只关注正样本而不考虑负样本,则可能会导致过拟合问题,因为模型过于专注于记住正确的答案而忽视了错误的答案。通过把正样本预测成负样本,可以让模型更加全面地理解图像内容,避免过度适应某些特定模式而导致泛化能力下降的问题。这样可以使模型学会更好的判别边界,增强其鲁棒性和准确性。
在多类情况下,可以通过让其中一个类别成为参考点,或是采用完整的交叉熵为基础的对比损失方式扩展这一方法,此时对比示例会被分别生成两个类别(如 y={0,1}),而不是仅有一个类别(如半交叉熵损失)。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!