MySQL基本操作 DDL DML DQL三大操作介绍
DDL 数据(结构)定义 创建表
创建 删除数据
-
注释
--空格+内容 -
创建数据库
CREATE DATABASE [if not exists] 数据库名 [ CHARSET utf8]- eg:
CREATE DATABASE IF NOT EXISTS school CHARSET utf8 - 如果对应school不存在,则创建新的数据库 且编码使用utf8
-
删除数据库
DROP DATABASE 数据库名 / [IF EXISTS数据库名]DROP DATABASE IF EXISTS school
-
修改字符集
ALTER DATABASE 数据库名 CHARSET 字符集名
-
创建表
-
表:是数据存储的最常见和最简单的形式,是构成关系型数据库的基本元素
-
每一个表都有 表头 和 表尾 表头定义表明和列名 表中的被看作是文件中的记录,表中的列被看作是这些记录的字段。
- 设计
表- 表名
- 表中的字段
- 字段的数据类型和长度
- 哪些约束
- 确定表名
- 设计
-
数据类型
-
char(n)长度为n的定长字符串,最大长度为255个字符 -
varchar(n)最大长度为n的可变字符串 -
date日期 包含年月日 -
datetime年月日 十分秒 -
整数
-
类型 字节 最小值 最大值 TINYINT1 -128 -127 SMALLINT2 -32768 -32767 MEDIUMINT3 -888608 -888607 INT4 -2147483648 -2147483647 BIGINT8 -9883372036854775808 -9883372036854775807 -
signed 有符号 unsigned 无符号 默认是有符号
-
-
浮点
-
-
语法
-
创建表
CREATE TABLE 表名(列名 数据类型 [约束] [默认值] [ 注释],......)-
CREATE TABLE 表名( number INT, NAME VARCHAR(5), gender CHAR(1), birthday DATE, phone VARCHAR(11), height DECIMAL(3,2), reg_time DATETIME ) -- CHAR(n) 定长的字符串 固定存储n个字符,长度不够n空格补齐 -- VAECHAR(n) 可变长度的字符串 n为最大长度 如果只占了小于n的m个字符 实际占有m个空间位置
-
-
删除表**
DROP TABLE [if exists ]表名** -
修改表**
RENAME TABLE 旧表名 TO 新表名** -
复制表结构**
CREATE TABLE 新表名 LIKE 被复制表名;**-
CREATE TABLE student LIKE stu;//把student的结构复制给stu;
-
-
主键:在一张表中代表唯一的一条记录,不能为空,不能重复
-
约束
-
PRIMARY KEY设置主键约束,添加主键约束后,值不能重复,一个表中只能有一个列是主键 -
主键列可以唯一的表示某一行数据
-
mysql中主键可以设置为自动增长AUTO_INCREMENT -
NOT NULL不能为空约束 -
UNIQUE唯一性约束 不能重复 -
检查约束 设置条件
-
注释
COMMENT + 注释 -
用法
CREATE TABLE student( number INT PRIMARY KEY AUTO_INCREMENT COMMENT '学号主键', NAME VARCHAR(6) NOT NULL, birthday DATE, phone VARCHAR(11) NOT NULL UNIQUE, heigth DECIMAL(3,2) CHECK(heigth<3), reg_time DATETIME )
-
-
执行某一个询问 必须选中
DML 数据操作 增删改
插入数据
- 方式1:
INSERT INTO 表名(列1,列2……,列n) VALUES(值1,值2…..,值n); - 方式2:
INSERT INTO 表名 set 列名1=值1,..列名; - 方式3:
INSERT INTO 表名(列1,列2……,列n) VALUES(值1,值2…..,值n),(值1,值2…..,值n); - 方式4:
INSERT INTO 表名(列1,列2……,列n) 查询语句(查询的列数与插入列数匹配);
修改数据
UPDATE 表名 SET列名 = '新值' WHERE 条件
删除数据
DELETE FROM 表名 WHERE 条件TRUNCATE TABLE 表名;//清空整张表
DQL 查询语句
-
查询指定的列
- **语法 : **
SELECT [查询列表] FROM 表名 - 结果可以是:表格中的字段,常量,表达式,函数
- 查询的结果是虚拟表格,不可以操作 是只读的
- 可以对查询结果进行 算术运算(+ - * /);
- **特点: **
- 查询的列表可以是:表中的字段,常量,表达式,函数
- 查询的结果是一个虚拟的表格
- **语法 : **
-
查询结果处理
-
特定列查询
select column 1, column2 form table(表名) -
全部列的查询
select * from TABLE (表名)-
-- 使用该表来进行举例子 CREATE DATABASE IF NOT EXISTS student CHARSET utf8 CREATE TABLE stu( id INT PRIMARY KEY NOT NULL AUTO_INCREMENT, number INT(5) NOT NULL, stuname VARCHAR(10) NOT NULL, age INT(3) CHECK(age>18), birthday DATE, weight DOUBLE, opertime DATETIME ) INSERT INTO stu (number ,stuname,birthday)VALUES(456,'cwy','2023-01-01'); -
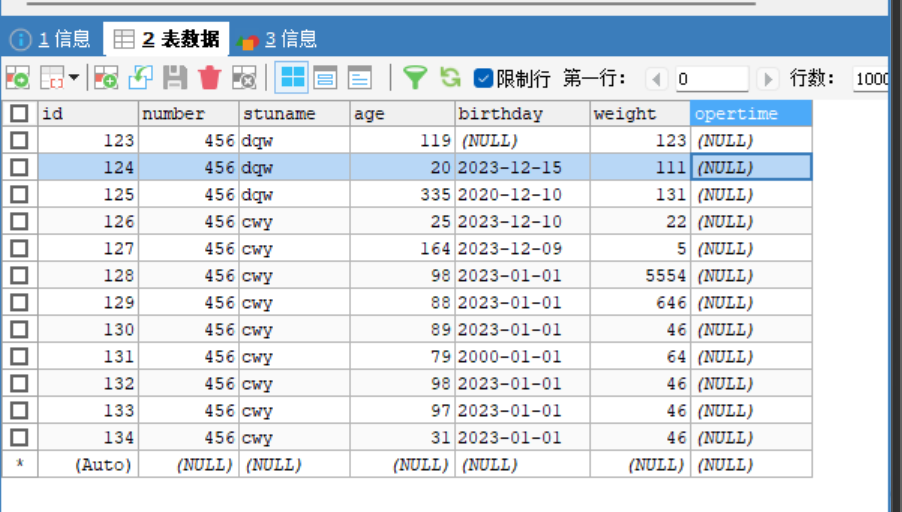
-
-
算术运算符: + - * /
-
排除重复行:
select distinct column1,column2 from table -
-- 查询指定的列 * 表示查询所有列 SELECT id,number FROM stu SELECT * FROM stu -- 查询结果进行算术运算 SELECT id+1, number/2 FROM stu -- 查询去重 对查询结果进行去重 SELECT DISTINCT stuname FROM stu -
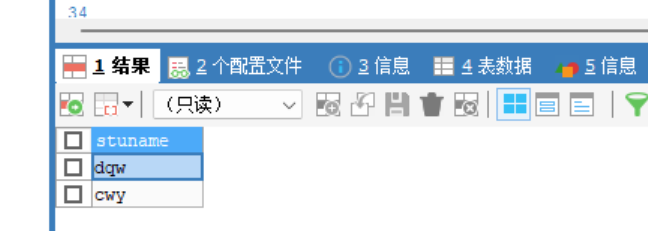
-
查询的时候可以使用函数 select也是一个函数
- 函数:类似于java中方法,将一组逻辑语句事先在数据库可以中定义好,可以直接调用
- 分类:
- 单行函数:如
concat,length,ifull等; - 分组函数:做统计使用,又称为统计函数,聚合函数,组合函数
- 单行函数:如
-
单行函数
-
字符函数
-
length()函数:获取参数值的字节个数 -
SELECT stuname,LENGTH(stuname) FROM stu -
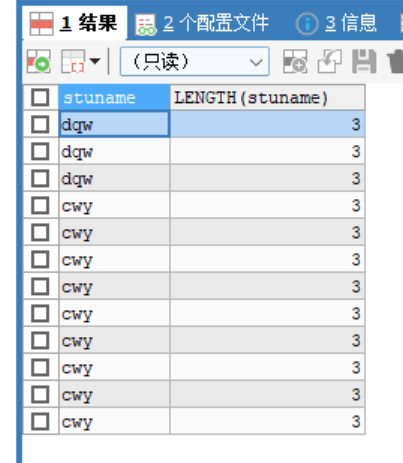
-
char_length(列名)获取变量字符串的长度 -
SELECT stuname,LENGTH(stuname) FROM stu -- 与length()用法一样 -
concat(str1,str2,.....)拼接字符串 str 指的是为字符串的列 如果其中str含NULL结果都为NULL -

-
instr(str ,指定字符)查找指定字符在str中首次出现的位置 -
ELECT INSTR(stuname,'w') FROM stu -
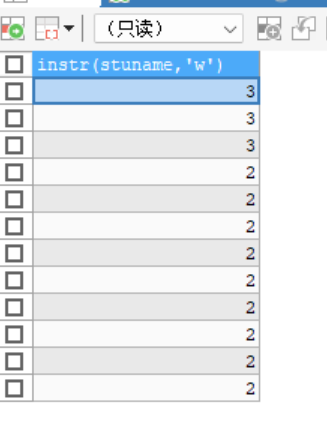
-
trim(str)默认去除str前后的空格,str为指定的子串且来自父类字符串 -
lpad(str,length,字符),与 rpad(str,length,字符)在字符左右填充length长的字符 注意length指的是字节的长度 -
-- lpad(str,length,字符) 在str左边填充length长度的 字符 SELECT LPAD(stuname,6,'w') FROM stu -- rpad 同上 在右边填充 -
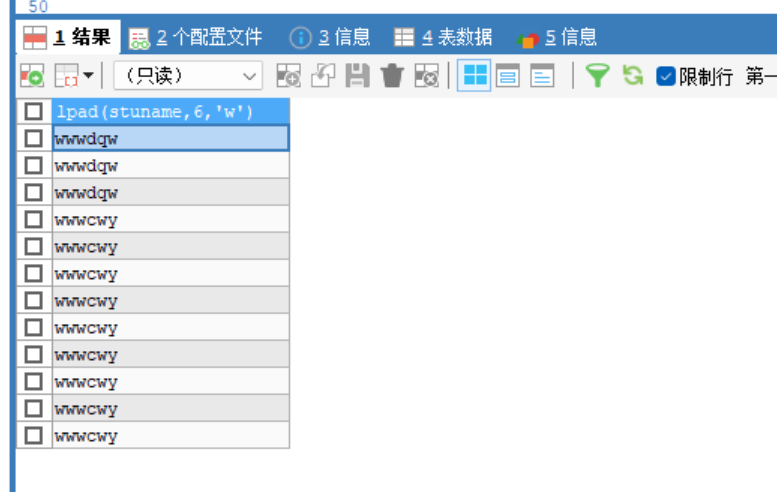
-
replace(sre, 目标字符,替换字符) -
-- replace(str,目标字符,替换字符) 把str中的目标字符 替换为 替换字符 SELECT REPLACE(stuname,'d','w') FROM stu
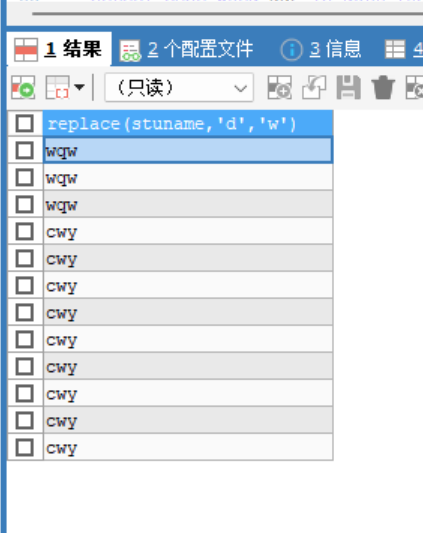
-
upper(str)转大写 lower(str)转小写str可以是字符串的列也可也是 字符串 但如果是字符串他会单独显示一列为str大写 -
-- upper()转大写 lower() 转小写 SELECT UPPER(stuname) FROM stu -- 为字符串的列 -
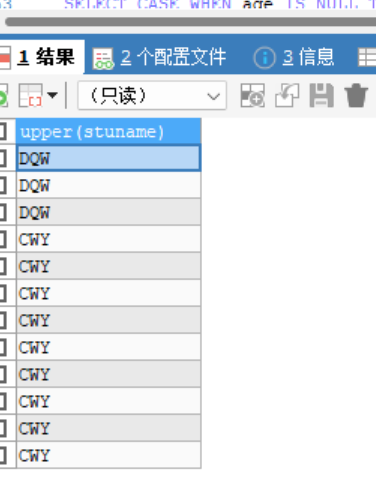
-- upper()转大写 lower() 转小写 SELECT UPPER('dqw') FROM stu -
-
逻辑处理
-
case when 条件 then 结果1 else 结果2 end;(可以有多个when) -
-- 表示id为123时 为1 否则都为2 SELECT CASE WHEN id=123 THEN 1 ELSE 2 END FROM stu; -
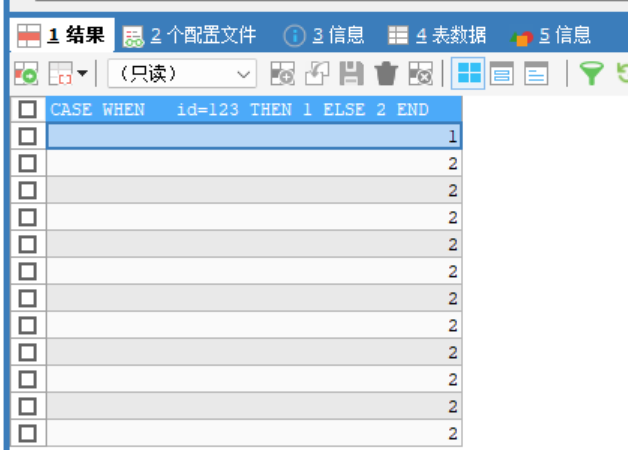
is nullSELECT CASE WHEN age IS NULL THEN 1 ELSE 2 END FROM stu;判断age是否为null
-
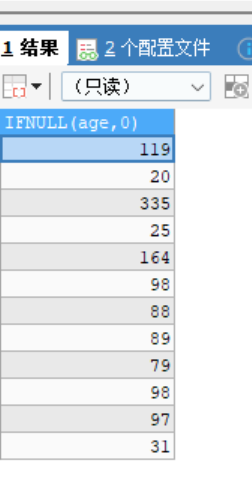
ifnull(被检测值,默认值)函数检测是否为null如果为null返回指定值,否则返回原本值 -
SELECT IFNULL(age,0) FROM stu;-- 判断age是否为空 不是返回原本值 否则返回 0 -
-
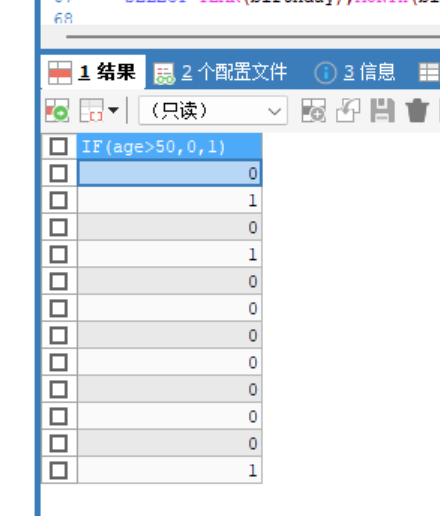
if(条件,结果1,结果2)if- else 的效果 -
SELECT IF(age>50,0,1) FROM stu; -
-
-
日期函数
-
now();返回当前日期 -
-- 获取当前日期 年月日 时分秒 SELECT NOW() FROM stu;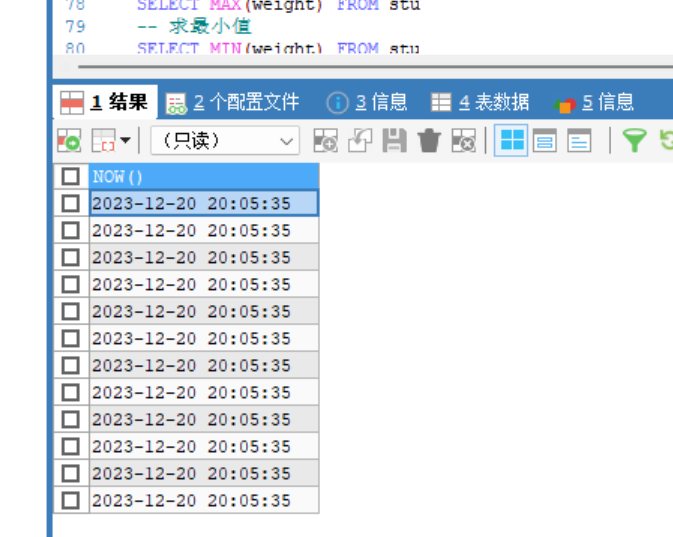
-
curdate()获取当前日期 不包含时分秒 curtime() 获取当前时分秒 不包含日期 -
可以获取指定部分 年 ,月, 日, 小时 , 分钟,秒
-
TEAR(日期列) MONTH(日期列) DAY(日期列) HOUR(日期列) MINUTE(日期列) SECOND(日期列) -
str_to_date(字符串格式的日期,格式)将日期格式的字符转化为指定格式的日期 -
date_format(日期列,格式)将日期转化为字符串 -
datediff(big ,small)返回两个日期相差的天数 -
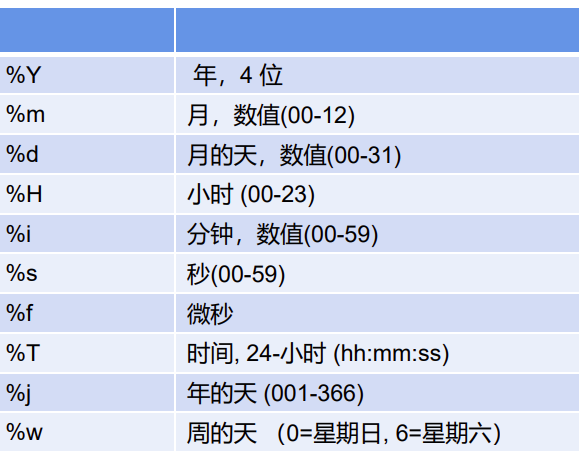
日期格式
-
-
分组函数
-
功能: 用作统计使用,又称为聚合函数或统计函数或组函数
-
分类:
sum求和avg平均值max最大值min最小值count计数(非空)sum,avg一般用于处理数值型maxmincount可以处理任何类型- 以上分组函数都可以忽略null值
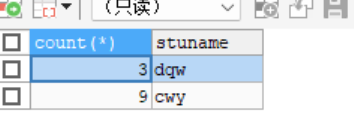
count函数的一般使用count(*)用作统计行数.- 和分组函数一同查询的字段要求是
group by后的字段 group by必须在语句最后
-
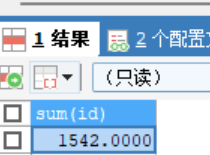
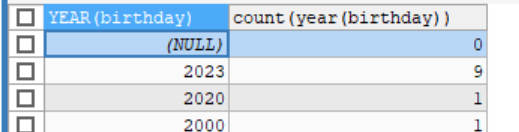
- 求和函数 SELECT SUM(id) FROM stu; -- 求平均 SELECT AVG(id) FROM stu; -- sum avg 只可以统计 数值类型 -- 求最大值 SELECT MAX(weight) FROM stu -- 求最小值 SELECT MIN(weight) FROM stu -- 统计函数 SELECT COUNT(weight>3) FROM stu; -- 分组函数 -- group by 分组函数 后面对应的变量 要与前面出现的变量一样() SELECT YEAR(birthday), COUNT(YEAR(birthday)) FROM stu GROUP BY YEAR(birthday); -
-
分组函数
-
-
-
-
条件查询
-
where(条件)where子句紧跟from子句-
语法
select <结果> from<表名>where<条件> -
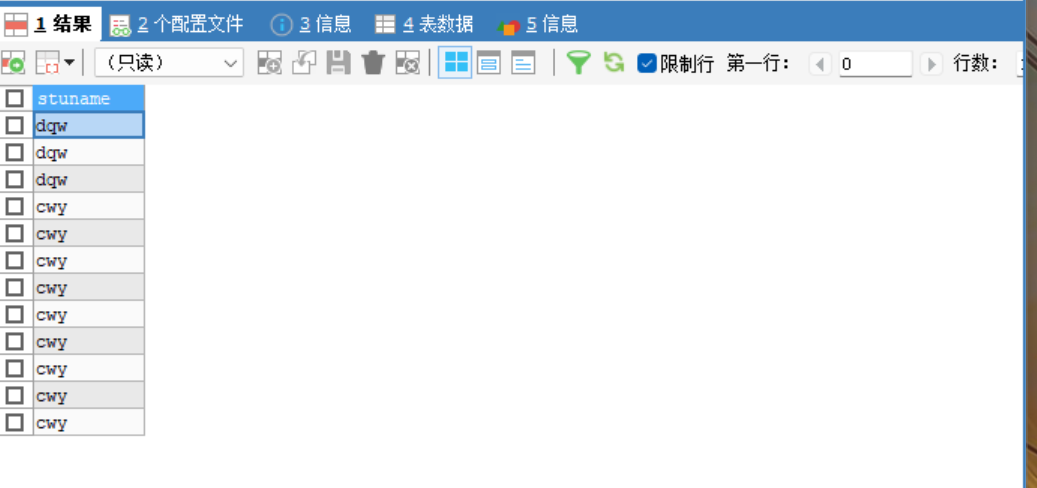
SELECT stuname FROM stu WHERE stuname LIKE '%w%'; -- 模糊匹配 stuname 含w数据
-
-
-
条件中的比较
= ,!= 或<>,>,<,>=,<=- 逻辑运算
and与or或not非
-
条件查询中模糊查询
-
LIKE: 是否匹配于一个模式,一般和通配符搭配使用,可以判断字符型数值或数值型 -
通配符: % 任意多个字符- 条件查询 'w%'表示以w开头的模糊匹配 '%w’表示以w结尾的模糊匹配 '%w%'表示包含w的模糊匹配
-
SELECT stuname FROM stu WHERE stuname LIKE '%w%'; -- 模糊匹配 stuname 含w数据 -- 结果如上 -
between and两者之间,包含临界值 -
In判断某字段的值是否输入in列表中的某一项 -
IS NULL(为空的) 或 IS NOT NULL(不为空的)
-
-
-
联合语句
UNIONUNION ALL-
UNION[SQL 语句 1]
UNION
[SQL 语句 2]
-
UNION ALL[SQL 语句 1]
UNION ALL
[SQL 语句 2]
-
注:当使用union时 MySQL会把结果集中重复的记录删除掉,而是用UNION ALL ,MySQL会把所有记录返回,其效率高于union
-
-
排序
-
如果想对查询的结果进行排序 使用
ORDER BY 子句排序-
ORDER BY [ASC/DESC] -
asc代表的是升序 ,desc代表的是降序,如果不写,默认为升序 -
ORDER BY可以支持单个字段与多个字段 -
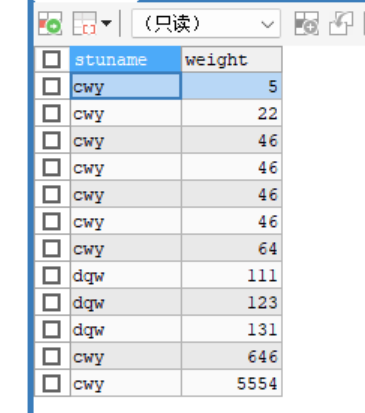
-- 排序 order by asc 是升序 desc是降序 SELECT stuname ,weight FROM stu ORDER BY weight ASC -
-
-
数量限制
- limit子句:对查询显示结果限制数目(sql语句最末尾位置)
SELECT * FROM table LIMIT offset rows- SELECT * FROM table LIMIT 0,5
-
分组查询
-
语法:
-
SELECT [分组函数] ,[列](要求出现在group by的后面)from [表]
[where 筛选条件]
group by 分组的列表 //分组
[having 分组后筛选] //
[order by 子句] //排序
-
注意:查询列表比较特特殊,要求是分组函数和group by后出现的字段
-
数据源 源位置 关键字 分组前的筛选 原始表 group by子句前面 where 分组后筛选 分组后的激活集 group by 的后面 having
-
-
-
-
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!