论文解读:A New CNN Building Block for Low-ResolutionImages and Small Objects
引言
之前通过stride和pooling这些下采样操作,但是这些操作都会或多或少丢失图像的信息,所以这不适用于具有低分辨率图像和小物体的更困难的任务上。像池化选择maxpooling或者是averagepooling、卷积的步长(太大的话会丢失信息)都是很头疼的问题,为此设计SPD模型。
摘要
卷积神经网络(cnn)在图像分类和目标检测等计算机视觉任务中取得了巨大的成功。然而,在图像分辨率低或物体很小的复杂任务中,它们的性能会迅速下降。在本文中,我们指出,这源于现有CNN架构中有缺陷但常见的设计,即使用跨行卷积和/或池化层,这会导致细粒度信息的丢失和学习不太有效的特征表示。为此,我们提出了一个新的CNN构建块,称为SPD-Conv,以取代每个跨行卷积层和每个池化层(从而完全消除它们)。SPD-Conv由一个空间到深度(SPD)层和一个非跨行卷积(Conv)层组成,可以应用于大多数(如果不是所有的话)CNN架构。我们在两个最具代表性的计算机视觉任务中解释了这种新设计:目标检测和图像分类。然后,我们通过将SPD-Conv应用于YOLOv5和ResNet来创建新的CNN架构,并通过经验表明,我们的方法显着优于最先进的深度学习模型,特别是在具有低分辨率图像和小物体的更困难的任务上。我们已经在https://github.com/LabSAINT/SPD-Conv上开源了我们的代码。
介绍
自AlexNet[18]以来,卷积神经网络(cnn)在许多计算机视觉任务中表现出色。例如在图像分类方面,知名的CNN模型有AlexNet、VGGNet[30]、ResNet[13]等;而在目标检测方面,这些模型包括R-CNN系列[9,28]、YOLO系列[26,4]、SSD[24]、EfficientDet[34]等。然而,在训练和推理中,所有这些CNN模型都需要“高质量”的输入(精细图像,中型到大型对象)。例如,AlexNet最初在227×227的清晰图像上进行训练和评估,但在将图像分辨率降低到1/4和1/8后,其分类准确率分别下降了14%和30%[16]。在VGGNet和ResNet上也有类似的观察[16]。
在VGGNet和ResNet上也有类似的观察[16]。在对象检测的情况下,SSD在1/4分辨率的图像或相当于1/4分辨率的小物体上遭受了显著的34.1mAP损失。事实上,小物体检测是一项非常具有挑战性的任务,因为小物体本身就具有较低的分辨率,而且可供模型学习的上下文信息也有限。此外,它们经常(不幸地)与同一图像中的大物体共存,大物体往往会主导特征学习过程,从而使小物体无法被检测到。
在本文中,我们认为这种性能下降的根源在于现有cnn中存在缺陷但又常见的设计。也就是说,使用跨行卷积和/或池化,特别是在CNN架构的早期层中。这种设计的不利影响通常不会表现出来,因为大多数被研究的场景都是“友好的”,其中图像具有良好的分辨率,对象大小适中;因此,有大量的冗余像素信息,跨卷积和池化可以方便地跳过,模型仍然可以很好地学习特征。然而,在图像模糊或物体很小的复杂任务中,对冗余信息的大量假设不再成立,当前的卷积设计开始遭受细粒度信息丢失和特征学习不良的影响。
为了解决这个问题,我们为CNN提出了一个新的构建块,称为SPD-Conv,以取代(从而消除)跨行卷积和池化层。SPD- conv是一个空间到深度(SPD)层,后面跟着一个非跨行(即vanilla)卷积层。SPD层对特征映射X进行下采样,但保留通道维度中的所有信息,因此没有信息丢失。我们受到图像变换技术[29]的启发,该技术在将原始图像馈送到神经网络之前重新缩放原始图像,但我们基本上将其推广到内部和整个网络中的降采样特征映射;此外,我们在每个SPD之后添加了一个非跨行卷积操作,以使用添加的卷积层中的可学习参数减少(增加)通道数量。我们提出的方法既通用又统一,因为SPD-Conv (i)可以应用于大多数(如果不是所有的话)CNN架构,并且(ii)以相同的方式取代跨行卷积和池化。综上所述,本文做出了以下贡献:
1)我们在现有的CNN架构中发现了一个有缺陷但常见的设计,并提出了一个新的构建块,称为SPD-Conv来代替旧的设计。SPD-Conv在不丢失可学习信息的情况下对特征图进行下采样,完全抛弃了目前广泛使用的跨行卷积和池化操作。
2) SPD-Conv代表了一种通用和统一的方法,可以很容易地应用于大多数(如果不是全部的话)基于深度学习的计算机视觉任务。
3)利用两个最具代表性的计算机视觉任务,即目标检测和图像分类,评估了SPD-Conv的性能。具体来说,我们构建了YOLOv5-SPD、ResNet18-SPD和ResNet50-SPD,并在COCO-2017、Tiny ImageNet和CIFAR-10数据集上对它们进行了评估,并与几种最先进的深度学习模型进行了比较。结果表明,在AP和top-1精度方面有显著的性能提高,特别是在小物体和低分辨率图像上。预览见图1。

4) SPD-Conv可以很容易地集成到流行的深度学习库中,如PyTorch和TensorFlow,可能会产生更大的影响。我们的源代码可从https://github.com/LabSAINT/SPD-Conv获得。
本文的其余部分组织如下。第2节介绍背景并回顾相关工作。第3节描述了我们提出的方法,第4节介绍了使用目标检测和图像分类的两个案例研究。第5节提供了性能评估。本文在第6节结束。
前期工作及相关工作
我们首先概述了这一领域,更多地关注目标检测,因为它包含了图像分类。
目前最先进的目标检测模型是基于cnn的,可以分为一级和两级检测器,或基于锚点或无锚点检测器。两阶段检测器首先生成粗区域建议,然后使用头部(全连接网络)对每个建议进行分类和细化。相比之下,单阶段检测器跳过区域建议步骤,直接在密集的位置采样上运行检测。基于锚点的方法使用锚点盒,锚点盒是一个预定义的盒子集合,与训练数据中对象的宽度和高度相匹配,以改善训练过程中的损失收敛性。我们提供了表1,对一些众所周知的模型进行了分类。

一般来说,一级检测器比二级检测器更快,基于锚点的模型比无锚点的模型更准确。因此,在后面的案例研究和实验中,我们更多地关注单阶段和基于锚点的模型,即表1中的第一个单元格。
一个典型的单阶段目标检测模型如图2所示。它由一个基于cnn的主干网和一个检测头组成,前者用于提取视觉特征,后者用于预测每个被包含对象的类别和边界框。在这两者之间,增加额外层的颈部来组合多个尺度的特征,以产生用于检测不同大小物体的语义强特征。
2.1小目标检测
传统上,大小目标的检测被视为一个多尺度的目标检测问题。一种经典的方法是图像金字塔[3],它将输入图像的大小调整为多个尺度,并为每个尺度训练一个专用检测器。为了提高精度,提出了SNIP[31],它在每个检测器中根据不同的目标大小进行选择性反向传播。SNIPER[32]通过只处理每个对象实例周围的上下文区域而不是图像金字塔中的每个像素来提高SNIP的效率,从而减少了训练时间。采用不同的方法来提高效率,特征金字塔网络(FPN)[20]利用横向连接利用卷积层固有的多尺度特征,并使用自上而下的结构组合这些特征。
随后,引入PANet[22]和BiFPN[34],利用更短的路径改进FPN的特征信息流。此外,引入SAN[15]将多尺度特征映射到尺度不变子空间上,使检测器对尺度变化具有更强的鲁棒性。所有这些模型都一致使用跨行卷积和最大池化,我们完全去掉了它们。
2.2低分辨率图像分类
解决这一挑战的早期尝试之一是[6],它提出了一个端到端的CNN模型,在分类之前增加一个超分辨率步骤。
随后,[25]提出将从高分辨率训练图像中获取的细粒度知识转移到低分辨率测试图像中。然而,这种方法需要对应于特定应用程序(例如,类)的高分辨率训练图像,而这些图像并不总是可用的。
对高分辨率训练图像的同样要求也被其他一些研究所需要,如[37]。最近,[33]提出了一个包含属性级可分离性(其中属性意味着细粒度的分层类标签)的损失函数,以便模型可以学习特定于类的判别特征。然而,细粒度(分层)类标签很难获得,因此限制了该方法的采用。
3新的构建模块:SPD-Conv
SPD- conv由空间到深度(SPD)层和非跨行卷积层组成。本节将对此进行详细介绍。

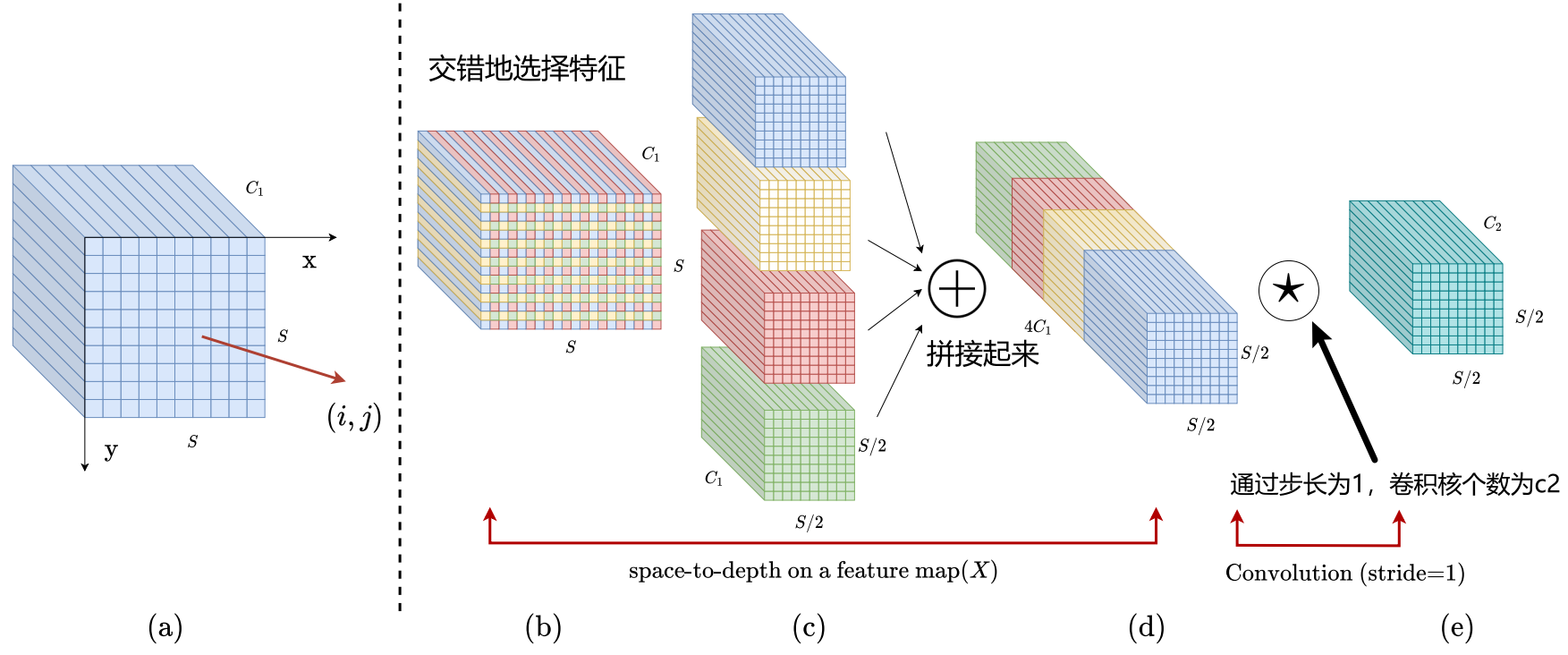
3.1 Space-to-depth (SPD)
我们的SPD组件推广了一种(原始)图像变换技术[29],对CNN内部和整个CNN的特征映射进行降采样,如下所示。
考虑任意大小为的中间特征映射X,将一系列子特征映射分割为
如图1:X的第一、二、三维度分别是,(c)中得到四个子图
,其中
,意思就是对图片第一维度从0开始,到S结束,步长为2来进行截取,第二维度也是如此,而第三维度通道
都选取上(即不进行截取)。
一般来说,给定任意(原始)特征映射X,子图由所有
组成,这些
都
和可以被
整除。因此,每个子地图将X的样本降低一个比例因子。图3(a)(b)(c)给出了
的例子,其中我们得到4个子图
每一个的形状为
对X进行2倍的采样。
接下来,我们沿着通道维度将这些子特征映射连接起来,从而获得一个特征映射,该特征映射的空间维度减少了一个比例因子,通道维度增加了一个比例因子2。也就是说,SPD对特征映射
转化为中间特征映射
。图3(d)给出了使用
的说明。
3.2非跨行卷积
在SPD特征变换层之后,我们在的条件下通过
个卷积核增加一个无跨距(即stride=1)的卷积层,并进一步变换
。我们使用非跨行卷积的原因是为了尽可能多地保留所有的判别特征信息。否则,例如,使用stride=3的3 × 3过滤器,特征地图将被“缩小”,但每个像素只采样一次;如果stride=2,将发生非对称采样,其中偶数和奇数行/列将在不同时间采样。一般情况下,步长大于1的跨步会导致信息的非判别性损失,尽管在表面上,它似乎也是转换了特征图
(但没有
)。
4如何使用SPD-Conv:案例研究
4.1目标检测(略)
4.2图像分类
分类CNN通常从一个由stride-2卷积和池化层组成的干单元开始,以将图像分辨率降低四倍。一个流行的模型是ResNet[13],它赢得了ILSVRC 2015的挑战。
ResNet引入了剩余连接,允许训练深度高达152层的网络。它还通过仅使用单个全连接层显著减少了参数的总数。最后使用一个softmax层来规范化类预测。
ResNet18-SPD和ResNet50-SPD。ResNet-18和ResNet-50都使用了总共4个stride-2卷积和一个stride-2的max-pooling层来对每个输入图像进行2.5倍的下采样。应用我们提出的构建块,我们用SPD-Conv代替了四个跨行卷积;但另一方面,我们简单地删除了最大池化层,因为我们的主要目标是低分辨率图像,我们实验中使用的数据集具有相当小的图像(Tiny ImageNet中的64 × 64和CIFAR-10中的32 × 32),因此池化是不必要的。对于较大的图像,这样的最大池化层仍然可以用同样的方式由SPD-Conv替换。表3显示了这两种新的体系结构。

5实验
本节使用两个代表性的计算机视觉任务,目标检测和图像分类来评估我们提出的方法SPD-Conv。
5.1目标检测(略)
5.2图像分类
数据集和设置
对于图像分类任务,我们使用了Tiny ImageNet[19]和CIFAR-10数据集[17]。Tiny ImageNet是ILSVRC-2012分类数据集的一个子集,包含200个类。每个类有500个训练图像、50个验证图像和50个测试图像。每个图像的分辨率64×64×3像素。CIFAR-10由6万张分辨率为32 × 32 × 3的图像组成,其中包括5万张训练图像和1万张测试图像。有10个类,每个类有6000张图片。我们使用top-1的准确率作为衡量分类性能的指标。
训练
我们在Tiny ImageNet上训练我们的ReseNet18-SPD模型。我们执行随机网格搜索来调整超参数,包括学习率、批大小、动量、优化器和权重衰减。图6显示了使用wandb mlop生成的样例超参数扫描图。结果是SGD优化器的学习率为0.01793,动量为0.9447,小批大小为256,权值衰减正则化为0.002113,训练epoch为200。接下来,我们在CIFAR-10上训练我们的ResNet50-SPD模型。超参数采用ResNet50论文,其中SGD优化器使用初始学习率0.1和动量0.9,批大小128,权衰减正则化0.0001,200个训练epoch。对于ReseNet18-SPD和ReseNet50-SPD,我们使用与ResNet相同的衰减函数,随着epoch数的增加而降低学习率。

测试
Tiny ImageNet上的精度是在验证数据集上评估的,因为测试数据集中的实际真实值不可用。CIFAR-10上的精度是计算在测试数据集上的。
结果
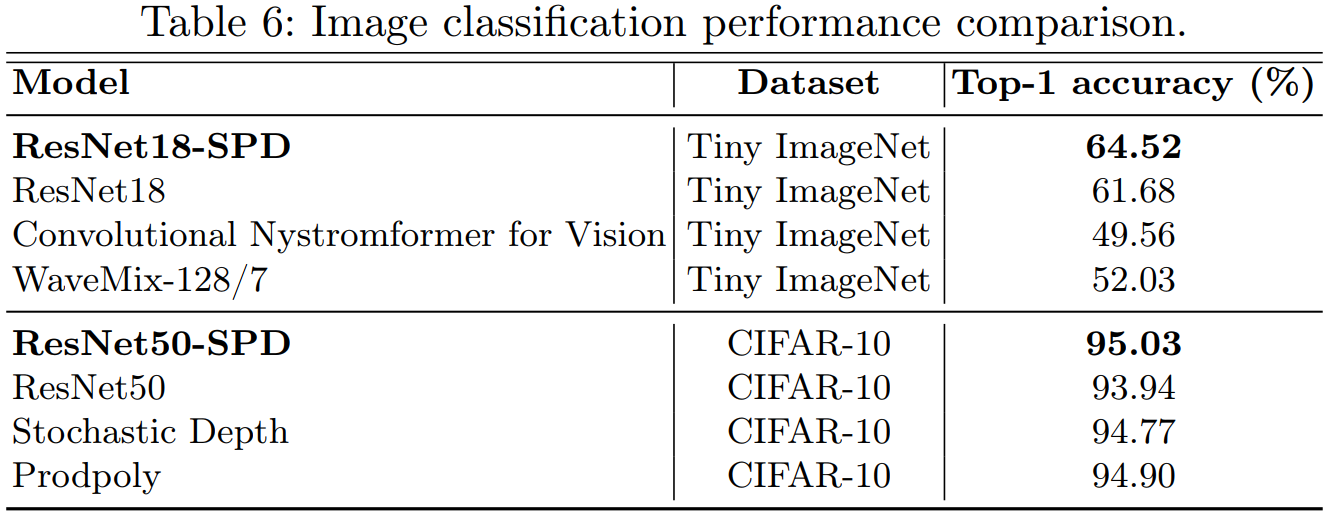
表6总结了top-1精度的结果。结果表明,我们的模型ResNet18-SPD和ResNet50-SPD明显优于所有其他基准模型。
最后,我们在图7中提供了一个使用Tiny ImageNet的视觉插图。给出了8个ResNet18错误分类和ResNet18SPD正确分类的例子。这些图像的共同特点是分辨率较低,因此我们的模型对标准ResNet提出了挑战,由于ResNet在其跨步卷积和池化操作中丢失了细粒度信息。

6 Conclusion
本文确定了现有CNN架构中常见但有缺陷的设计,即使用跨行卷积和/或池化层。这将导致细粒度特征信息的丢失,特别是在低分辨率图像和小物体上。然后,我们提出了一个新的CNN构建块,称为SPD-Conv,它通过用一个空间到深度的卷积替换它们,然后是一个非跨行卷积,从而完全消除了跨行和池化操作。这种新设计在保留判别特征信息的同时,对特征映射进行了降采样。它还代表了一种通用和统一的方法,可以很容易地应用于任何CNN架构,并以同样的方式应用于跨步转换和池化。我们提供了两个最具代表性的用例,目标检测和图像分类,并通过广泛的评估证明了SPD-Conv在检测和分类精度方面带来了显着的性能改进。我们期望它能广泛地造福研究社区,因为它可以很容易地集成到现有的深度学习框架中,如PyTorch和TensorFlow。
参考资料
论文下载

📎No More Strided Convolution or Pooling A New CNN Building Block for Low-Resolution.pdf
代码地址
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!