Java中的编码问题
1. 简介
编码问题一直困扰着开发人员,尤其在java中更加明显,因为Java是跨平台语言,不同平台的编码之间的切换较多。
2. 几种常见的编码格式
- 为什么要编码
计算中存储信息的最小单位是一个字节,即8个bit,所以能表示的范围是0~255,而人类要表示的符号太多,无法用一个字节表示,要解决这个矛盾必须要有一个新的数据结构char,从char到byte必须编码。
- ASCII码
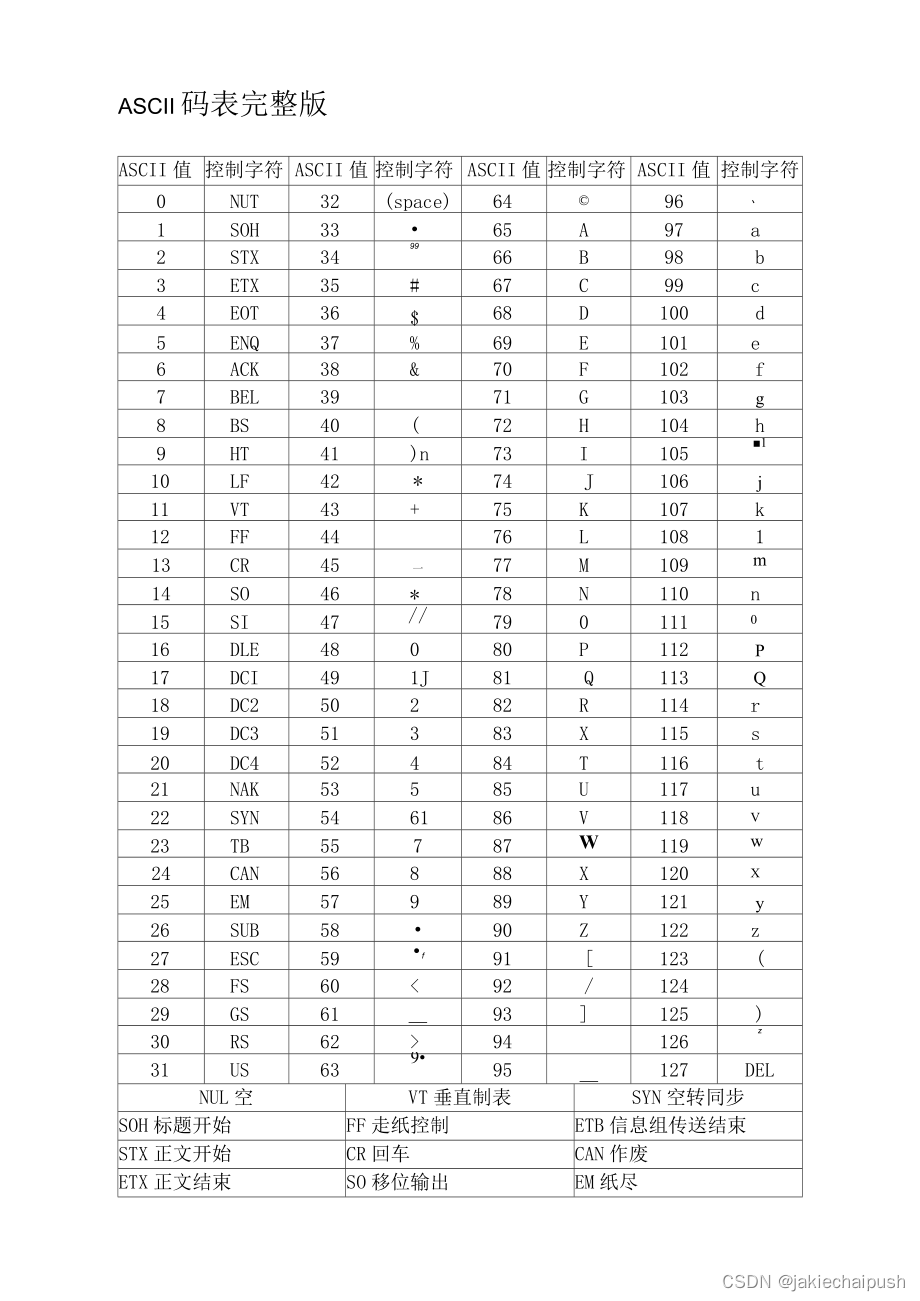
ASCII码总共有128个,即一个字节的低7位表示,0~31是控制字符如换行、回车和删除等。32~126是打印字符,可以通过键盘输入并且能显示出来。
- ISO-8859-1
128个字符显然是不够用的,于是ISO组织在ASCII码基础上制定了一系列标准来扩展ASCII编码,它们是ISO-8859-1~ISO-8859-15,其中ISO-8859-1涵盖了大多数西欧语言符号,所以应用得最广泛。ISO-8859-1仍然是单字节编码,它总共能表示256个字符。
- GB2312
它的全称是《信息交换汉字编码字符集基本集》,它是双字节编码,总的编码范围是A1~F7,其中A1~A9是符号区,总共包含682个符号,B0~F7是汉字区,包含6763个汉字。
- GBK
全称为《汉字内码扩展规范》,它的出现是为了扩展GB2312,加入了更多汉字,它的编码范围是8140~FEFE,总共23940个码位,它能表示21003个汉字,它的编码是和GB2312兼容的。
- GB18030
全称是《信息交换用汉字编码字符集》,是我国的强制标准,它可能是单字节,双字节或者四字节编码,它和GB2312编码兼容,实际应用不广。
- UTF-16
说到UTF必须提到Unicode,ISO试图创建一个全新的超语言字典,世界上所有语言都可以用该字典表示。Unicode是Java和XML的基础。UTF-16具体定义了Unicode字符在计算机中的存取方法。UTF-16用两个字节来表示Unicode转化格式,它是定长的表示方法,不论什么字符都可以用两个字节表示。
- UTF-8
UTF-16统一采用两个字节表示一个字符,虽然在表示上很方便,但是也有其缺点,有很大一部分字符用一个字节就可以表示的现在要用两个字节表示,存储空间放大了一倍,这会增大网络传输的流量,而且也没有必要。UTF-8采用了一种变长技术,每个编码区域有不同的字码长度,不同类型的字符可以由1~6个字节表示,其编码规则如下:
- 如果一个字节,最高位(第8位)位为0,表示这是一个ASCI字符,可见所有的ASCII编码已经是UTF-8了。
- 如果一个字节,以11开头,连续的1个数暗示这个字符的字节数,例如110XXXXX代表它是双字节UTF-8字符的首字节
- 如果一个字节,以10开头,表示它不是首字节,需要向前查找才能找到首字节
3. Java中需要编码的场景
- I/O操作中存在编码
Reader类是java中I/O字符读的父类,InputStream类是读字节的父类,InputStreamReader类是关联字节到字符的桥梁,而具体的字符的解码委托StreamDecoder去做,在StreamDecoder解码的过程中必须指定Charset。在我们的应用程序中涉及I/O操作,只要注意指定统一的编解码,就一般不会出现乱码问题。
- 内存操作中编码
内存中进行字符到字节的数据类型转换,Java中使用String表示字符串,所以String类提供了转换到字节的方法,也支持将字节转换为字符串的构造函数。
String s="你好";
byte[] b=s.getBytes("UTF-8");
String n=new String(b,"UTF-8");
Charset提供了encode与decode分别对应char[] 到byte[] 的编码和byte[] 到char[] 的解码
Charset charser=Charset.forName("UTF-8");
ByteBuffer byteBuffer=charset.encode(string);
CharBuffer charBuffer=charset.decode(byteBuffer);
Java中还有一个ByteBuffer类,它提供了char和byte之间的软转换,它们之间转换不需要编码和解码,只是把一个16bit的char拆分成了2个8bit的byte表示,它们实际值并没有修改,仅仅是数据进行了转换,如下代码所示:
ByteBuffer heapByteBuffer=ByteBuffer.allocate(1024);
ByteBuffer bytebuffer=heapByteBuffer.putChar(c);
4. Java中如何编码解码
这部分使用实际例子介绍Java如何实现编码及解码。以字符串“i am 周杰伦的粉丝“为例子。
public class Main {
public static void main(String[] args) throws InterruptedException{
String a="i am 周杰伦粉丝";
byte[] iso8859=a.getBytes(Charset.forName("ISO-8859-1"));
System.out.println(Arrays.toString(iso8859));
byte[] gb2312=a.getBytes(Charset.forName("GB2312"));
System.out.println(Arrays.toString(gb2312));
byte[] gbk=a.getBytes(Charset.forName("GBK"));
System.out.println(Arrays.toString(gbk));
byte[] utf16=a.getBytes(Charset.forName("UTF-16"));
System.out.println(Arrays.toString(utf16));
byte[] utf8=a.getBytes(Charset.forName("UTF-8"));
System.out.println(Arrays.toString(utf8));
}
}
下图是Java中编码需要用到的类图。
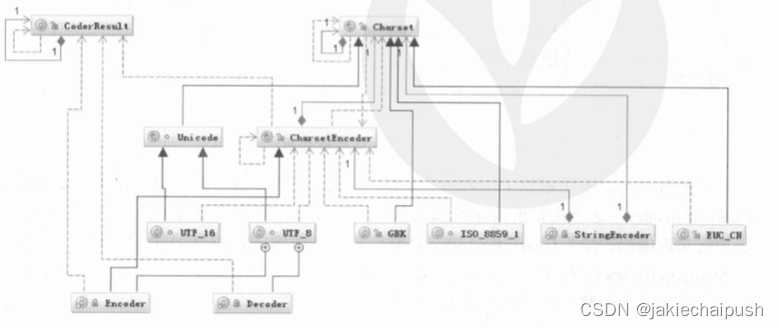
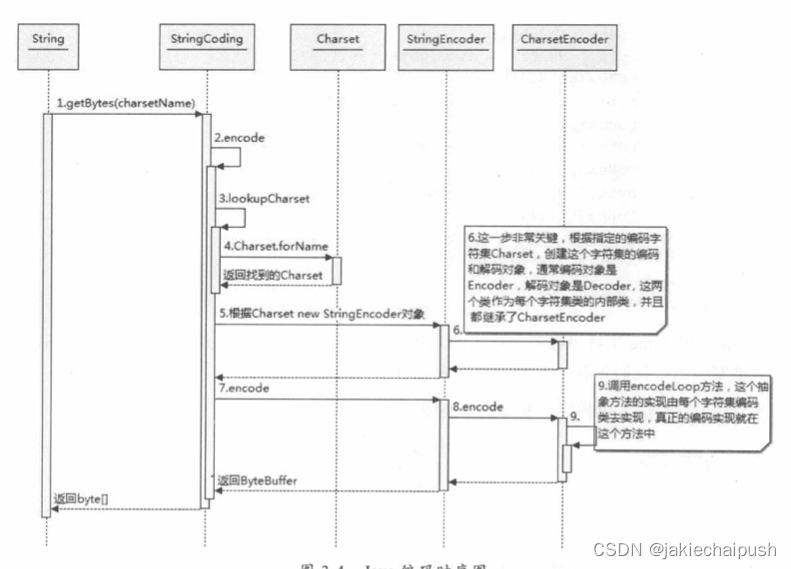
首先根据charsetName通过Charset.forName(charsetName)反射找到Charset类,然后根据Charset创建CharsetEncoder对象,再调用CharsetEncoder.encode对字符串进行编码,不同编码类型都会对应到一个类中,实际的编码狮子啊这些类中完成的。
4.Java 中涉及的编码和解码
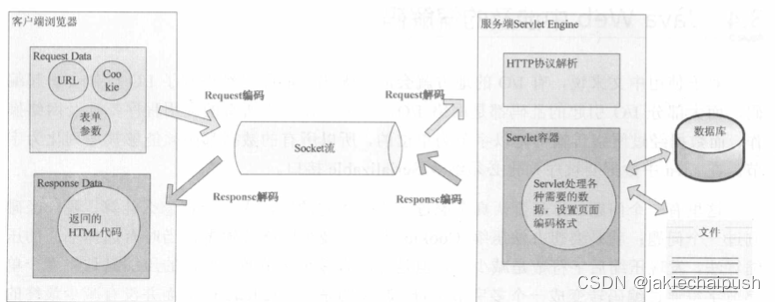
对于中文来说,有I/O的地方就会有编码,前面已经提到了I/O操作会引起编码,而大部分I/O引起的乱码都是网络I/O,因为几乎所有的应用程序都涉及网络操作,而数据经过网络传输都是以字节为单位的,所有的数据都必须能够序列化为字节。
用户从浏览器端发起一个HTTP请求,需要存在编码的地方是URL、Cookie、Paramiter。服务器端接收到HTTP请求后解析HTTP协议,其中URI、Cookie和POST表单参数需要解码,服务端可能还需要读取数据库中的数据,这些数据都可能存在编码问题,当Servlet处理完所有请求的数据后,需要将这些数据再编码通过Socket发送到用户请求的浏览器中,再经过浏览器解码成文本。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!