RDD算子——转换操作(Transformations )【map、flatMap、reduceByKey】
2024-01-08 21:28:58
一、map
-
map 算子
# spark-shell sc.parallelize(Seq(1, 2, 3)) .map( num => num * 10) .collect() # IDEA @Test def mapTest(): Unit = { // 1. 创建RDD val rdd1 = sc.parallelize(Seq(1, 2, 3)) // 2. 执行 map 操作 val rdd2 = rdd1.map(item => item * 10) // 3. 得到结果 val result:Array[Int] = rdd2.collect() result.foreach(item => println(item)) // 关闭sc sc.stop() }


- 作用
- 把 RDD 中的数据 一对一的转换为另一种形式
- 调用
def map[U: ClassTag] (f: T ? U) : RDD[U]
- 参数
- f → map 算子是 原 RDD → 新 RDD 的过程, 这个函数的参数是原 RDD 的数据, 返回值是经过函数转换的新 RDD 的数据
- 注意点
-
map 是一对一, 如果函数是?
String → Array[String]则新的 RDD 中每条数据就是一个数组
-
- 作用
二、flatMap
-
flatMap算子
# spark-shell sc.parallelize(Seq("Hello lily", "Hello lucy", "Hello tim")) .flatMap( line => line.split(" ")) .collect() # IDEA @Test def flatMapTest(): Unit = { // 1. 创建RDD val rdd1 = sc.parallelize(Seq("Hello lily", "Hello lucy", "Hello tim")) // 2. 执行 flatMap 操作 val rdd2 = rdd1.flatMap( line => line.split(" ")) // 3. 得到结果 val result:Array[String] = rdd2.collect() result.foreach(line => (println(line))) // 关闭sc sc.stop() }

- 作用
- flatMap 算子和 map 算子类似, 但是 FlatMap 是一对多
- 调用
def flatMap[U: ClassTag](f: T ? List[U]): RDD[U]
- 参数
f?→ 参数是原 RDD 数据, 返回值是经过函数转换的新 RDD 的数据, 需要注意的是返回值是一个集合, 集合中的数据会被展平后再放入新的 RDD
- 注意点
- flatMap 其实是两个操作, 是?
map + flatten, 也就是先转换, 后把转换而来的 List 展开 - flatMap 也是转换,他可以把数组和集合展开,并且flatMap中的函数一般也是集合或者数组
- flatMap 其实是两个操作, 是?
- 作用
三、reduceByKey
-
ReduceByKey算子
# spark-shell sc.parallelize(Seq(("a",1), ("a", 1), ("b", 1))) .reduceByKey( ( cur, agg) => cur + agg) .collect() # IDEA @Test def reduceByKeyTest(): Unit = { // 1. 创建RDD val rdd1 = sc.parallelize(Seq("Hello lily", "Hello lucy", "Hello tim")) // 2. 处理数据 val rdd2 = rdd1.flatMap( item => item.split(" ")) .map(item => (item, 1)) .reduceByKey( (cur, agg) => cur + agg) // 3. 得到结果 val result:Array[(String, Int)] = rdd2.collect() result.foreach(item => (println(item))) // 4. 关闭sc sc.stop() }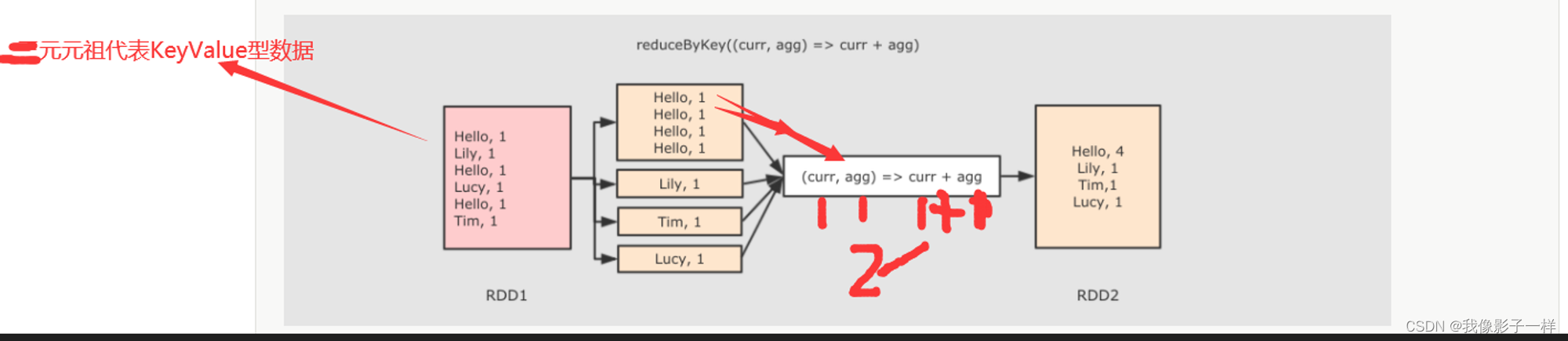

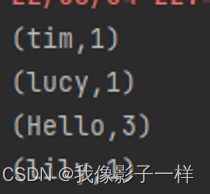
- 作用
- 首先按照 Key 分组, 接下来把整组的 Value 计算出一个聚合值, 这个操作非常类似于 MapReduce 中的 Reduce
- 调用
def reduceByKey(func: (V, V) ? V): RDD[(K, V)]
- 参数
- func → 执行数据处理的函数, 传入两个参数, 一个是当前值, 一个是局部汇总, 这个函数需要有一个输出, 输出就是这个 Key 的汇总结果
- 注意点
- ReduceByKey 只能作用于 Key-Value 型数据, Key-Value 型数据在当前语境中特指 Tuple
- ReduceByKey 是一个需要 Shuffled 的操作
- 和其它的 Shuffled 相比, ReduceByKey是高效的, 因为类似 MapReduce 的, 在 Map 端有一个 Cominer, 这样 I/O 的数据便会减少
- reduceByKey第一步是按照Key进行分组,然后对每一组进行聚合得到结果
- 作用
文章来源:https://blog.csdn.net/m0_56181660/article/details/135465909
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!