毕业设计-基于卷积神经网络的手势识别检测系统 人工智能 算法 机器视觉 YOLO
目录
前言
? ? 📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
大家好,这里是海浪学长人工智能专业毕设专题,本次分享的课题是
🎯基于卷积神经网络的手势识别检测系统
项目背景与简介
?????? 手势识别检测系统是一种利用深度学习中的CNN模型来实现手势识别和检测的系统。手势识别是指通过分析人体动作和手势的姿态、形状等信息,将其转化为计算机可理解的形式,并进行分类或识别的任务。
主要设计思路
一、算法理论技术
1.1 深度学习
?????? 反向传播(BP)是一种常用于训练神经网络的模型,通常与优化算法(如随机梯度减少模型)结合使用。该模式使用网络中自有失重数学函数的定向梯度响应优化算法,以重复更新神经网络的有效权重值,以最大限度地减少数学函数的损失。BP算法由两个阶段组成:激励阶段和权重比率重复更新阶段。
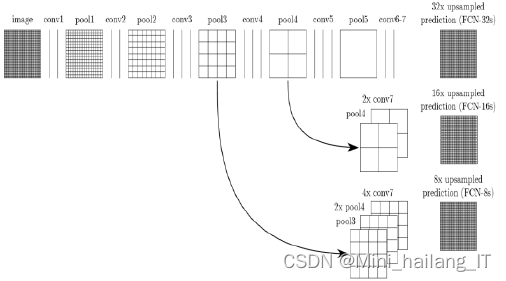
?????? 全分布卷积神经网络结构,包含全分布卷积结构、反分布卷积操控管理和跳跃结构。跳跃结构是表示应用反分布卷积模式将图像大小还原成初始图像的大小的时候,能够叠加处理融合浅层级的特征图和深层级的特征图的有关数据信息一同预计像元的种类。能够从浅层级的图像中获取图像纹理、边沿等局部数据信息,所以,将两者展开融合的跳跃结构就能够让自动输出的最终处理结果更为精确。
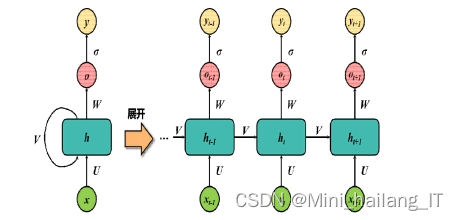
?????? RNN是一种用于处理序列数据的专用神经网络。它在机器翻译,语音识别,自然语言处理等领域得到了广泛的应用。传统RNN由三个层构成,即输入层、隐藏层和输出层,各层间以完全连通的方式进行互联。
1.2 卷积神经网络
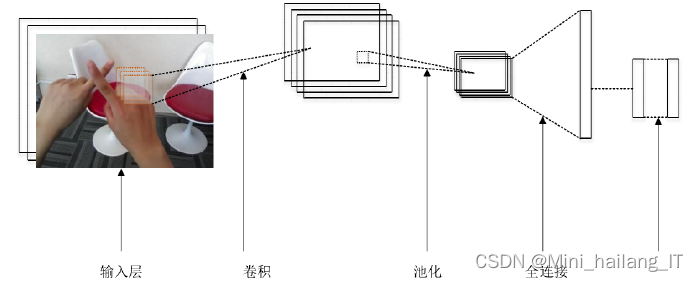
?????? 相对于全连接网络,CNN的参数量相对较少,可以像全连接网络一样直接将数据输入并进行端到端的训练。在图像识别,语义分割,目标检测等方面有着重要的应用。其结构包含输入层,卷积层,池化层,活化层,和完全连接层等。
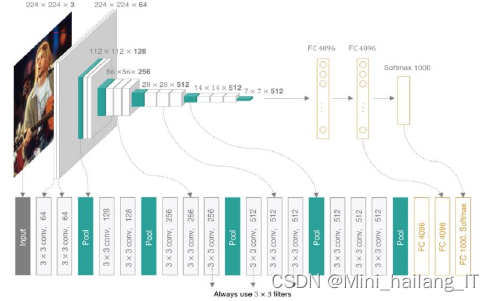
?????? VGG分布卷积网络的输入是224*224的RGB图像,整个网络的组成是非常格式化的,基本上都用的是3*3的卷积核以及2*2的max pooling,少部分网络加入了1*1的卷积核。VGG16包括了16个隐藏层(13个卷积作用分布层和3个全连接层),VGG19包括了19个隐藏层(16个卷积作用分布层和3个全连接层)。
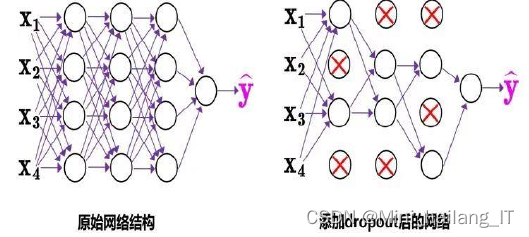
?????? CNN网络模型由于具有大量参数和深层次结构,易出现过拟合现象。采用Dropout方法,该算法在神经网络的学习期间,对某些神经元的某些权值进行了随机调整,使其不做与隐藏层权值的相关运算。这样可以缩减参数量,有效避免过拟合。
for epoch in range(num_epochs):
# 前向传播
outputs = model(inputs)
loss = criterion(outputs, labels)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 在训练过程中,使用dropout层
model.train()
# 测试过程
model.eval() # 在测试过程中,关闭dropout层
with torch.no_grad():
outputs = model(inputs)
_, predicted = torch.max(outputs, 1)
accuracy = (predicted == labels).sum().item() / labels.size(0)
print("Accuracy: {:.2f}%".format(accuracy * 100))二、数据处理
2.1 数据集
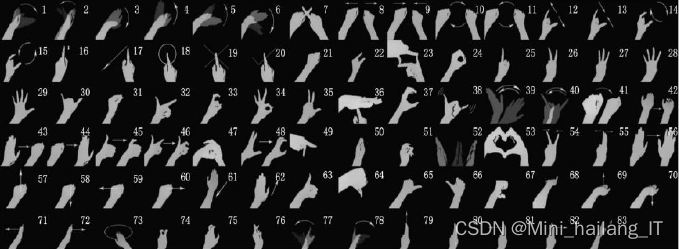
?????? 数据集每帧图像大小为320×240,包括83个手势和24161个不同场景的手势样本。该数据集由RGB图像和深度图像组成,每种模式超过300万帧,提供了广泛的手势动作信息,包括各种场景。这些手势在六种不同的室内和室外场景以及背景和灯光中以不同的方式收集,以尽可能丰富地涵盖现实生活中的手势。包括25种手势类型,共2000个手势动作,用于不同的人机界面,图像分辨率为640×480,提供了RGB图像、深度信息、分割信息等多种信息。
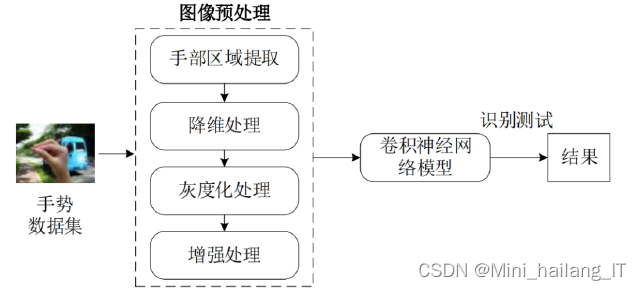
2.2 数据处理
?????? 数据增强是一种在训练过程中对原始数据进行变换和扩充的技术。它通过对输入数据进行一系列随机或确定性的变换操作,生成新的训练样本,从而增加了训练数据的多样性。
transform = transforms.Compose([
transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.RandomVerticalFlip(), # 随机垂直翻转
transforms.RandomRotation(30), # 随机旋转(最大角度为30度)
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1), # 随机调整亮度、对比度、饱和度和色调
transforms.RandomCrop(224), # 随机裁剪为224x224大小
transforms.ToTensor(), # 转换为张量
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 归一化
])三、实现的效果
?????? 训练硬件平台配置为第11代i7-11800H处理器,搭载RTX3070显卡,16GB DDR4内存和512GB固态硬盘输入图像分辨率调整为16,并将批处理大小设置为16。动量为0.949,初始学习率为0.001,功率衰减率为0.0005,总重复次数为8000
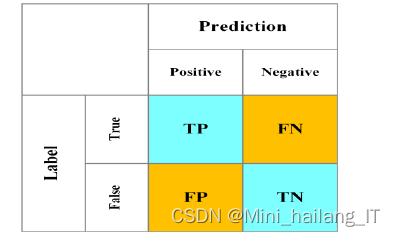
?????? 当前比较常见的评价指标有:准确率P、召回率R、交并比IoU、F1分数、平均准确度均值mAP、模型体积V和检测速度FPS。
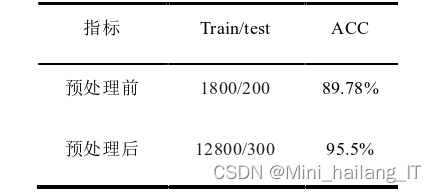
?????? 对手势进行了预处理后,结果比对图像进行预处理前的识别准确率提高了5.72%。
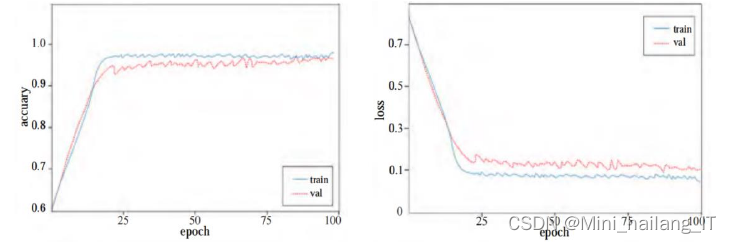
?????? 随着迭代次数的增多,训练集和样本集的准确率随着时间的推移而逐渐升高,最终趋于一个稳定值,而且损耗值也不断下降,最后达到一个稳定水平。实验表明该模型可以很好地对数据集进行拟合,同时,我们使用的预处理方法也能够有效地避免训练过程中的过度拟合。
for epoch in range(num_epochs):
model.train()
train_loss = 0.0
train_correct = 0
for images, labels in train_loader:
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
_, predicted = torch.max(outputs.data, 1)
train_correct += (predicted == labels).sum().item()
train_loss += loss.item() * images.size(0)
train_loss /= len(train_dataset)
train_accuracy = 100.0 * train_correct / len(train_dataset)?更多帮助
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!