残差网络学习
2023-12-22 06:25:31
?参考B站同济子豪兄的Resnet讲解
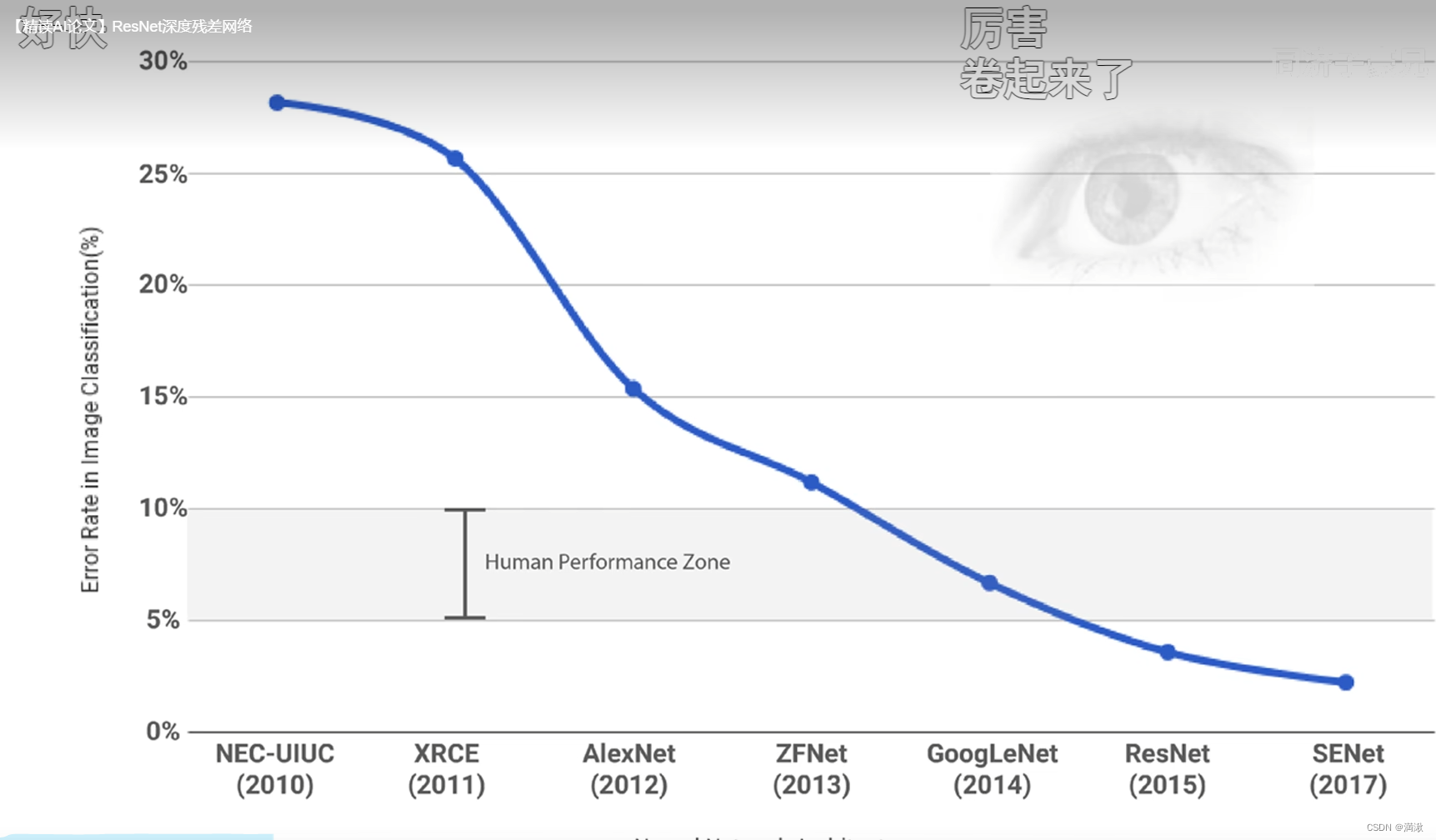
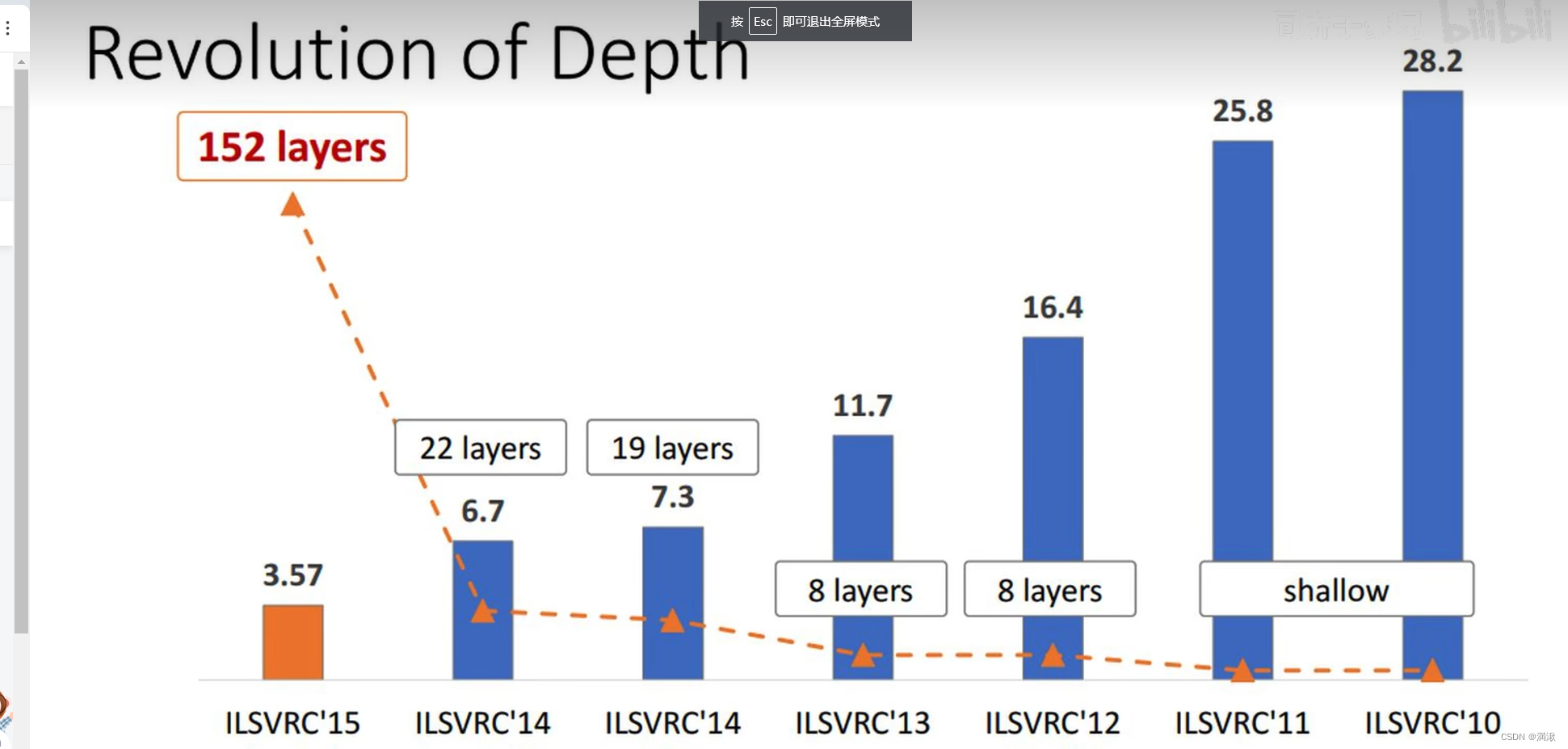
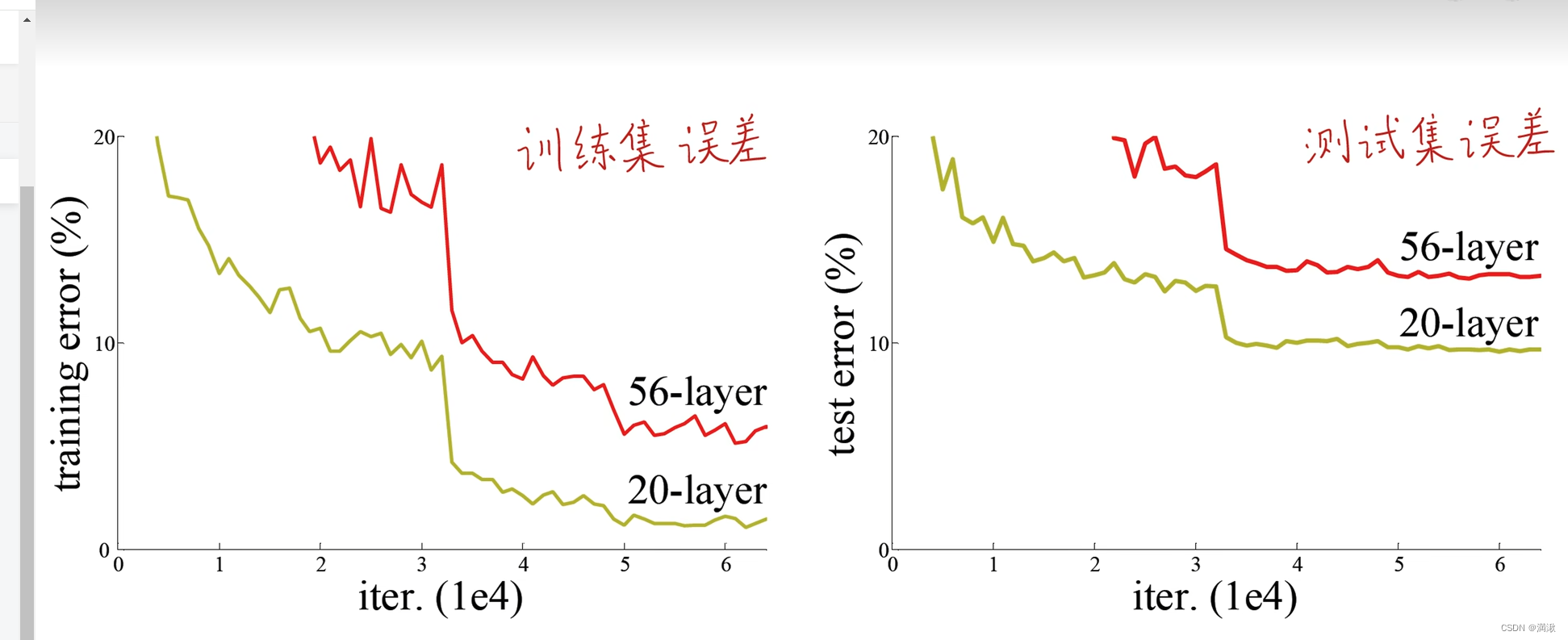
网络退化,不是梯度消失(根本没有开始学习),梯度爆炸,过拟合。

不需要再拟合复杂底层的那个映射了,原来输入的基础上你需要进行哪些偏移哪些修改
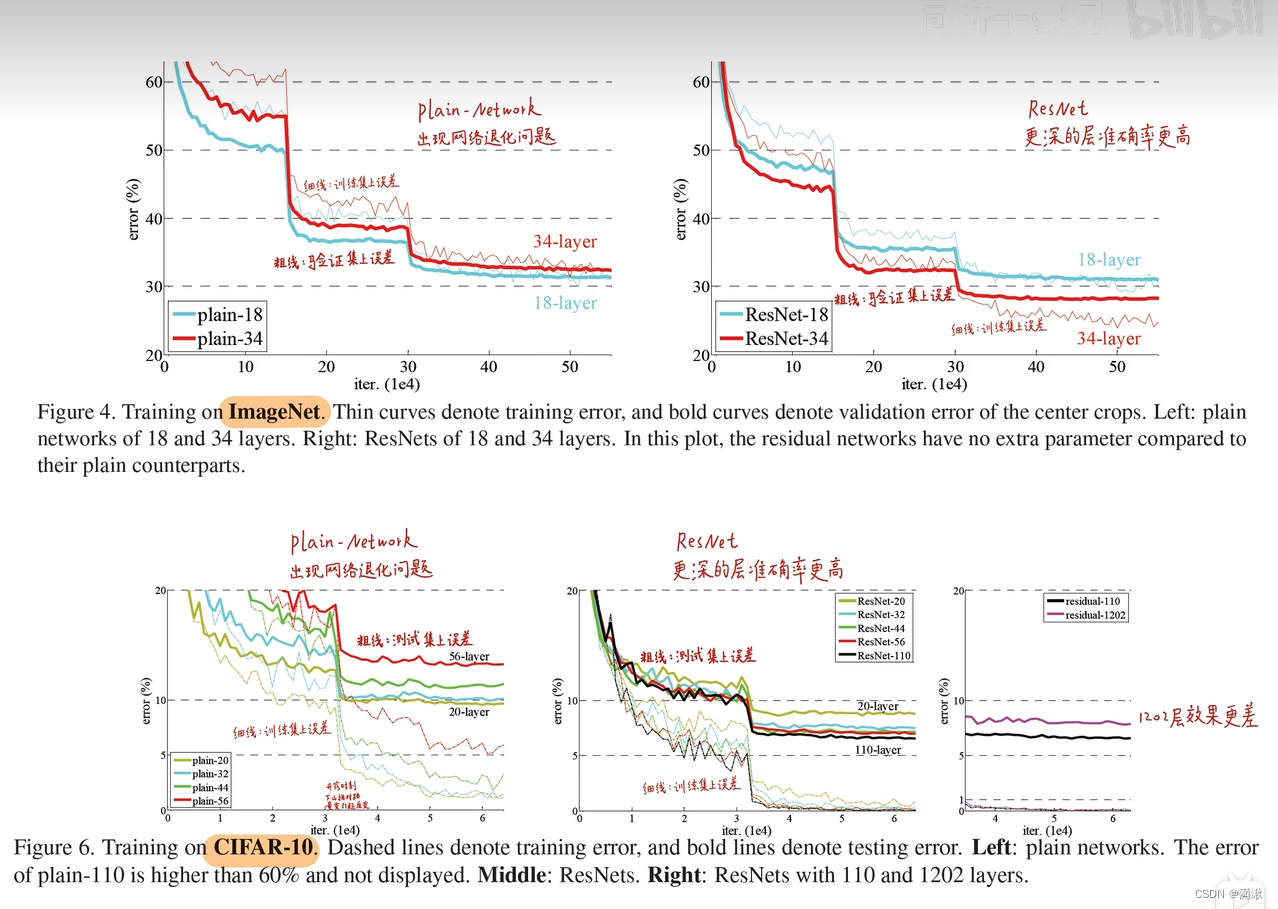
残差预测值和真实值的偏差
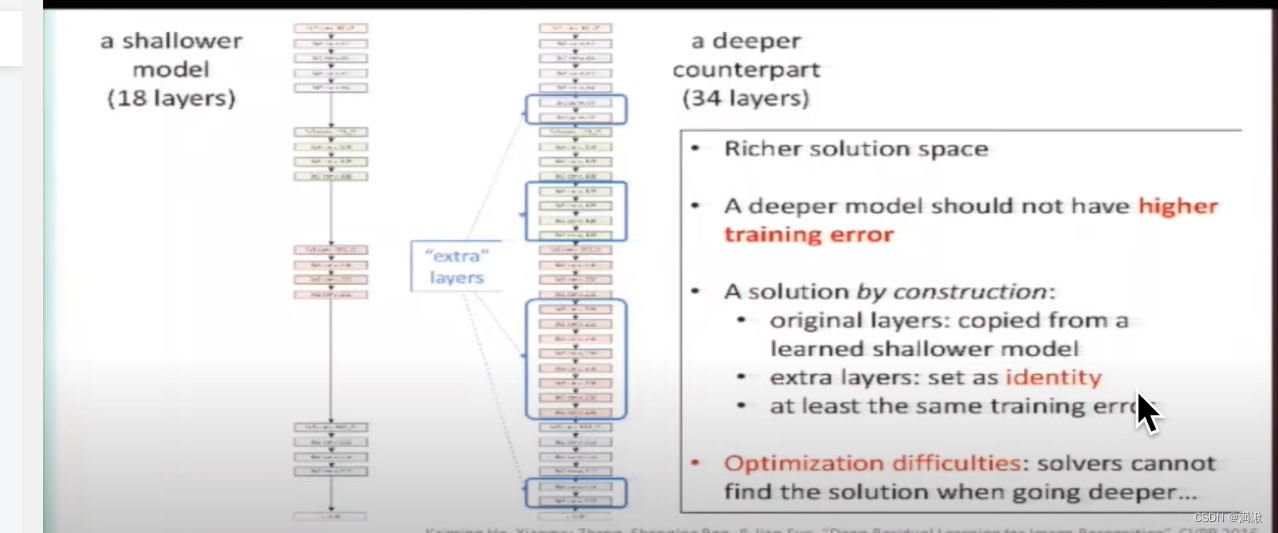
一路加深了模型,网络分为两支,一路是 同样的浅层网络处理,另一路保留原来的输入,恒等映射。

残差
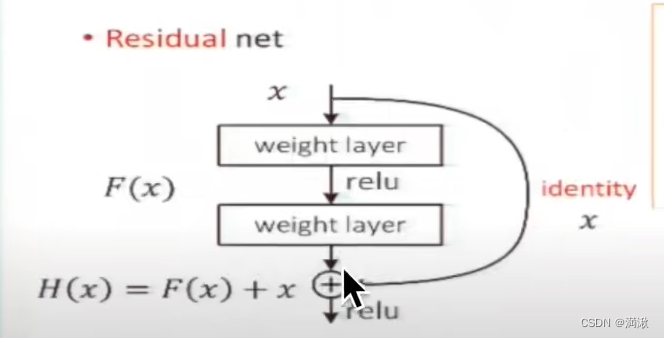
处理x和处理过(比如做了下采样)后网络不一样的方法:
1.在下采样过程中把多出来的通道用0做padding
2.做1*1的卷积,把维度调整到和残差块一样
3.不管是在下采样还是普通模块在shortcat都采用1*1卷积
下采样不用pulling直接用步长为2的卷积

深度估计,Depth estimation用视觉的方法评估画面的深度
 为什么有这些优势,就是因为训练的梯度可以从深层灌回底层
为什么有这些优势,就是因为训练的梯度可以从深层灌回底层

几个弱学习器划分在一起变成强学习器

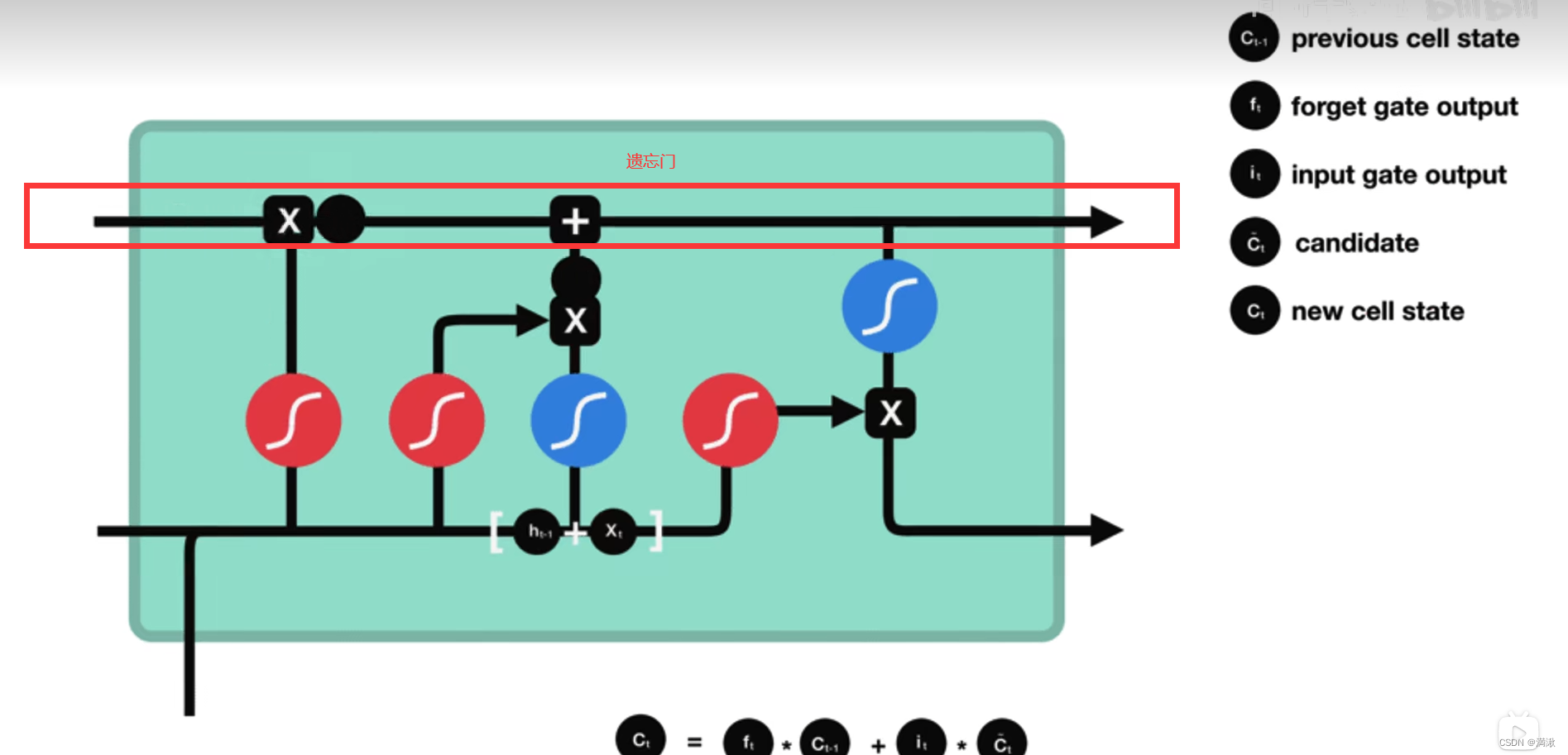
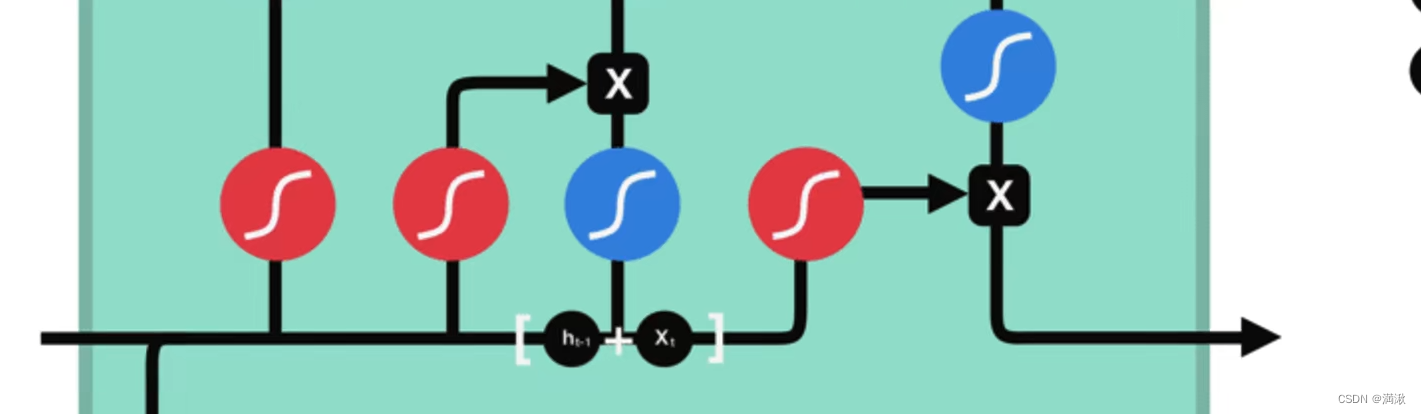
残差,Relu重要的给1,不重要的给0
加入了恒等映射之后,让残差为0实线恒等映射。

相邻像素和相邻梯度都有相关性。
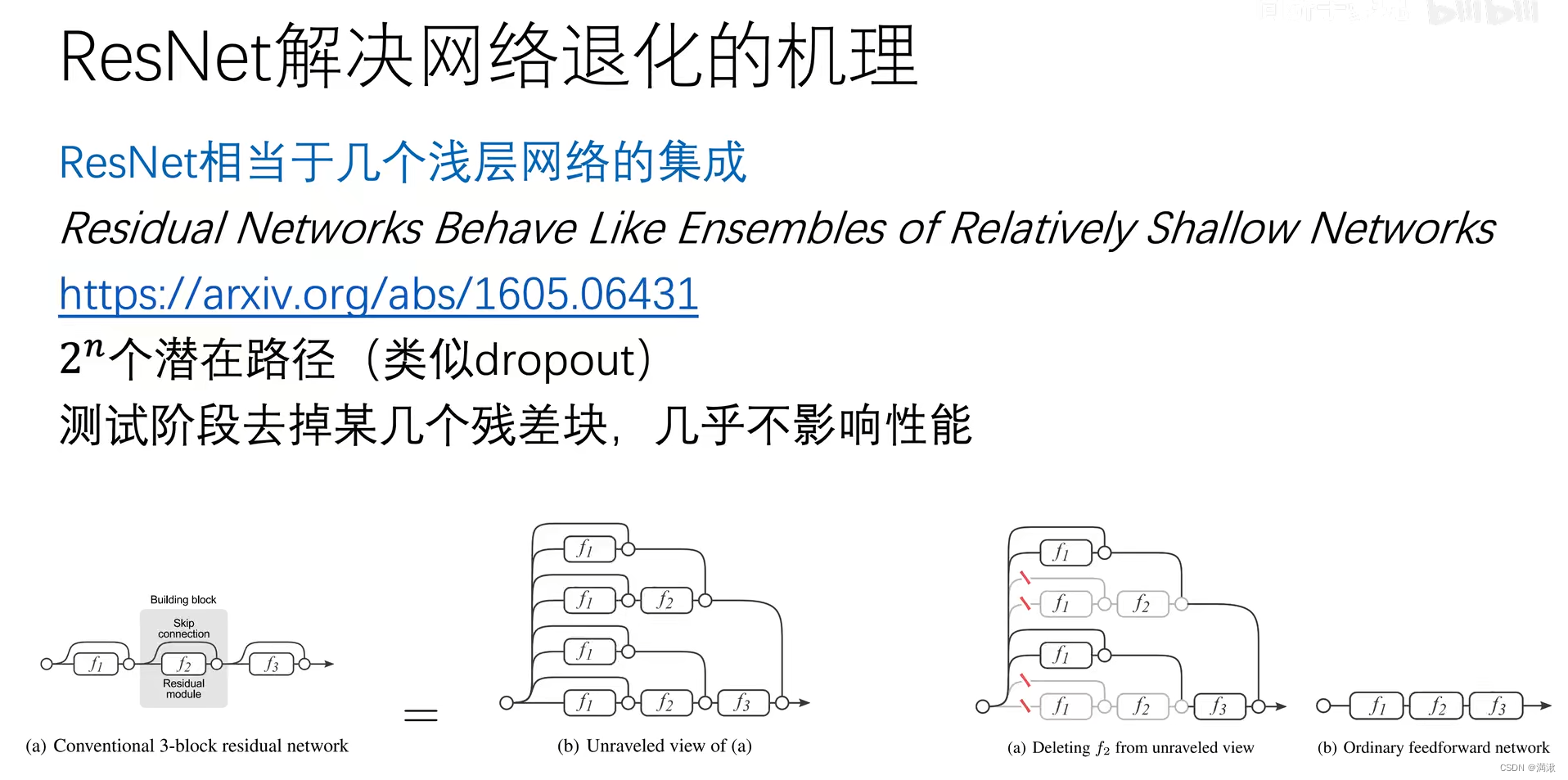
这个模型相当于有8条路,与dropout类似,让这些路彼此独立。可以实现并行的。分散风险。

Densenet

在Dense Block里面,每一层都与它之后的所有层相连,这样就能更加强大的释放以后每一个尺度的特征。

文章来源:https://blog.csdn.net/weixin_44680341/article/details/135132559
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!