经典论文之(一)——Alexnet
Alexnet
简介
《ImageNet Classification with Deep Convolutional Neural Networks》(基于深度卷积神经网络的图像网络分类),是我今天想要学习的文章,也是非常厉害的一篇文章,是第一个引起大家注意的CNN网络。这篇文章的网络是在2012年的ImageNet竞赛中取得冠军的一个模型整理后发表的文章。
文章训练了一个大型深度卷积神经网路,将ImageNet LSVRC-2010比赛中的120万幅高分辨率图像分为1000个不同的类别。在测试数据上,分别获得了37.5%和17.0%的前1和前5的错误率。
该神经网络具有6000万个参数和65万个神经元,由五个卷积层组成,其中一些卷积层后面是最大池化层,以及三个全连接层,最后是1000路的softmax。
在本文中,也使用了dropout的正则化方法,并且被认为是十分有效的。
背景
在之前,对象识别方法主要是利用机器学习的方法,为了提高它们的性能,我们可以收集更大的数据集,学习更强大的模型,并使用更好的技术来防止过度拟合。直到最近,标记图像的数据集还相对较小,只有数万张图片。
为了从数百万张图像中了解数千个物体,我们需要一个具有强大学习能力的模型。然而,对象识别任务的巨大复杂性也就意味着即使是像ImageNet这样大的数据集也无法指定这个问题,因此我们的模型也应该由大量的先验知识来补偿我们没有的所有数据。而卷积神经网络CNNs构成了一类这样的模型。它们的容量可以通过改变深度和广度来空置,并对图像的性质做出了强有力且大多正确的假设。因此,与具有类似大小层的标准前馈神经网络相比,细胞神经网络的连接和参数要少得多,因此更容易训练,而其理论上的最佳性能可能只会稍差。
最终,网络的大小主要受到当前GPU上可用内存量和我们愿意容忍的训练时间量的限制。我们的网络需要5到6天的时间在两个GTX 580 3GB GPU上进行训练。我们所有的实验都表明,只需等待更快的GPU和更大的数据集就可以改进我们的结果。
数据集
本文采用了ImageNet数据集,它是由一个超过1500万张标记的高分辨率图像组成的数据集,属于大约22000个类别。从2010年开始,作为Pascal视觉对象挑战赛的一部分,一年一度的比赛被称为ImageNet大规模视觉识别挑战赛(ILSVRC)。ILSVRC使用ImageNet的一个子集,在1000个类别中的每一个类别中大约有1000个图像。总共大约有120万张训练图像、5万张验证图像和15万张测试图像。
ImageNet由可变分辨率的图像组成,而我们的系统需要恒定的输入维度。因此,我们将图像下采样到256*256的固定分辨率。
体系结构
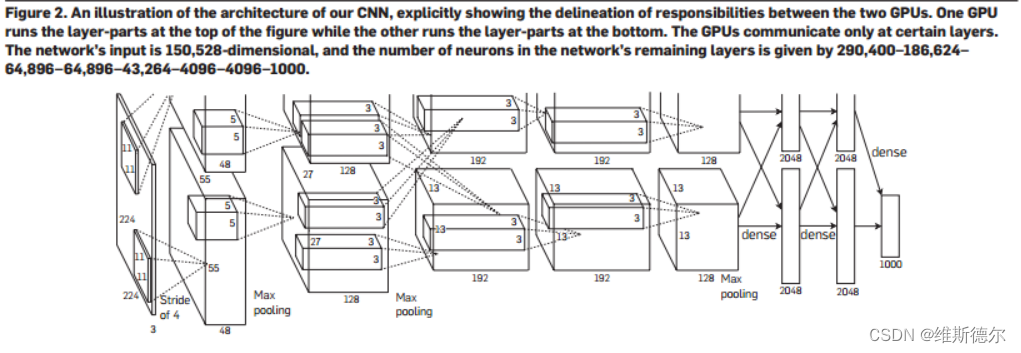
总体体系结构如下图,总共包含了八层-----五个卷积层和三个全连接层
Rectified Linear Unit nonlinearity(ReLU)
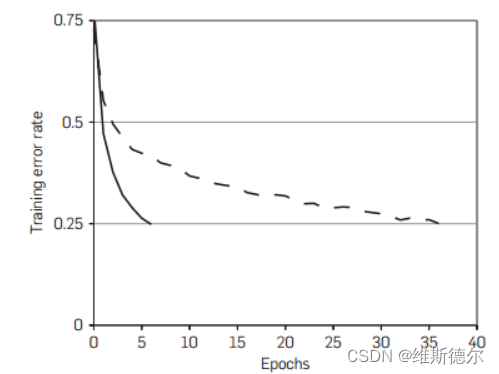
在本篇文章中,采用了ReLU这样一个非饱和非线性的神经元来代替之前的tanh等激活函数。具有ReLU的深层细胞神经网络的训练速度是具有tanh单元的同类细胞的数倍。这在图1中得到了证明,图1显示了在特定四层卷积网络的CIFAR-10数据集上达到25%训练误差所需的迭代次数。
ReLU:f(x)=max(0,x)
在多个GPU上训练
单个GTC 580 的GPU只有3GB的内存,这限制了可以在其上训练的网络的最大大小。所以将网络分布在两个GPU上。使用的并行化方案基本上将一半的内核(或神经元)放在每个GPU上。
总体架构
现在,我们准备描述我们的CNN的总体架构。如图2所示,该网包含八层有重量的网;前五个是卷积的,其余三个是完全连接的。最后一个完全连接层的输出被馈送到1000路softmax,其产生在1000类标签上的分布。我们的网络使多项式逻辑回归目标最大化,这相当于在预测分布下使正确标签的对数概率在训练情况下的平均值最大化。
第一卷积层用96个大小为11×11×3的核对224×224×3的输入图像进行滤波,步长为4个像素(这是核图中相邻神经元的感受野中心之间的距离)。第二卷积层将第一卷积层的(响应归一化和合并的)输出作为输入,并用大小为5×5×48的256个核对其进行滤波。第三、第四和第五卷积层在没有任何介入池化或归一化层的情况下彼此连接。第三卷积层具有384个大小为3×3×256的核,连接到(归一化、池化)输出第二卷积层的。第四卷积层具有384个大小为3×3×192的核,第五卷积层具有256个大小为2×3×192。完全连接的层各有4096个神经元。
减少过拟合
我们的神经网络架构有6000万个参数。尽管1000类ILSVRC使每个训练示例对从图像到标签的映射施加10位约束,但事实证明,这不足以在没有相当大的过拟合的情况下学习这么多参数。下面,我们将介绍我们对抗过度拟合的两种主要方法。
data augmentation数据扩充
减少图像数据过拟合的最简单和最常见的方法是使用标签保留变换人工放大数据集。我们采用了两种不同形式的数据增强,这两种形式都允许从原始图像中生成变换图像,只需很少的计算,因此变换图像不需要存储在磁盘上。在我们的实现中,当GPU在前一批图像上进行训练时,转换后的图像在CPU上以Python代码生成。因此,这些数据增强方案实际上是无计算的。
数据增强的第一种形式包括生成图像平移和水平反射。我们通过从256×256图像中随机提取224×224个补丁(及其水平反射),并在这些提取的补丁上训练我们的网络来实现这一点。这将我们的训练集的大小增加了2048倍,当然,所产生的训练示例是高度相互依赖的。
第二种形式的数据增强包括改变训练图像中RGB通道的强度。具体来说,我们在整个ImageNet训练集中对RGB像素值集执行PCA。对于每个训练图像,我们将所找到的主分量的倍数相加,其幅度与相应的本征值乘以从平均值为0、标准偏差为0.1的高斯图中提取的随机变量成比例。
dropout丢弃法
丢弃法就是设置一个dropout值,随机丢弃一些值,这些神经元不参与正向传递,也不参与反向传播。因此,每次出现输入时,神经网络都会对不同的架构进行采样,但所有这些架构都共享权重。这项技术减少了神经元的复杂协同适应。
参考
参考文章
ImageNet Classification with Deep Convolutional Neural Networks
参考视频
从0开始撸代码–手把手教你搭建AlexNet网络模型训练自己的数据集(猫狗分类)
参考代码
网络代码
import torch
from torch import nn
import torch.nn.functional as F
class MyAlexNET(nn.Module):
def __init__(self):
super(MyAlexNET, self).__init__()
self.c1 = nn.Conv2d(in_channels=3, out_channels=48, kernel_size=11, stride=4, padding=2)
self.ReLU = nn.ReLU()
self.c2 = nn.Conv2d(in_channels=48, out_channels=128, kernel_size=5, stride=1, padding=2)
self.s2 = nn.MaxPool2d(2)
self.c3 = nn.Conv2d(in_channels=128, out_channels=192, kernel_size=3, stride=1, padding=1)
self.s3 = nn.MaxPool2d(2)
self.c4 = nn.Conv2d(in_channels=192, out_channels=192, kernel_size=3, stride=1, padding=1)
self.c5 = nn.Conv2d(in_channels=192, out_channels=128, kernel_size=3, stride=1, padding=1)
self.s5 = nn.MaxPool2d(kernel_size=3, stride=2)
self.flatten = nn.Flatten()
self.f6 = nn.Linear(4608, 2048)
self.f7 = nn.Linear(2048, 2048)
self.f8 = nn.Linear(2048, 1000)
self.f9 = nn.Linear(1000, 2)
def forward(self, x):
x = self.ReLU(self.c1(x))
x = self.ReLU(self.c2(x))
x = self.s2(x)
x = self.ReLU(self.c3(x))
x = self.s3(x)
x = self.ReLU(self.c4(x))
x = self.ReLU(self.c5(x))
x = self.s5(x)
x = self.flatten(x)
x = self.f6(x)
x = F.dropout(x, p=0.5)
x = self.f7(x)
x = F.dropout(x, p=0.5)
x = self.f8(x)
x = F.dropout(x, p=0.5)
x = self.f9(x)
return x
if __name__ == '__main__':
x = torch.rand([1, 3, 224, 224])
model = MyAlexNET()
y = model(x)
训练代码
import torch
from torch import nn
from net import MyAlexNET
import numpy as np
from torch.optim import lr_scheduler
import os
from torchvision import transforms
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 训练测试集
ROOT_TRAIN = r'F:/desktop/myAlexnet/data/train'
ROOT_TEST = r'F:/desktop/myAlexnet/data/val'
# 将图像的像素值归一化到-1——1之间
normalize = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
train_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.RandomVerticalFlip(),
transforms.ToTensor(),
normalize
])
val_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
normalize
])
# 图片加载
train_dataset = ImageFolder(ROOT_TRAIN, transform=train_transform)
val_dataset = ImageFolder(ROOT_TEST, transform=val_transform)
# 数据批次加载
train_dataloader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_dataloader = DataLoader(val_dataset, batch_size=32, shuffle=True)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = MyAlexNET().to(device)
# 定义一个损失函数
loss_fn = nn.CrossEntropyLoss()
# 定义一个优化器
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
# 学习率每隔10轮变为原来的0.5
lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.5)
# 定义训练函数
def train(dataloader, model, loss_fn, optimizer):
loss, current, n = 0.0, 0.0, 0
for batch, (x, y) in enumerate(dataloader):
image, y = x.to(device), y.to(device)
# model(image)实质上是调用了model对象的__call__方法,而__call__方法内部会调用forward方法
output = model(image)
cur_loss = loss_fn(output, y)
_, pred = torch.max(output, axis=1)
cur_acc = torch.sum(y==pred) / output.shape[0]
# 反向传播
optimizer.zero_grad()
cur_loss.backward()
optimizer.step()
loss += cur_loss.item()
current += cur_acc.item()
n = n+1
train_loss = loss / n
train_acc = current / n
print('train_loss' + str(train_loss))
print('train_acc' + str(train_acc))
return train_loss, train_acc
# 定义验证函数
def val(dataloader, model, loss_fn):
# 将模型转化为验证模式
model.eval()
loss, current, n = 0.0, 0.0, 0
with torch.no_grad():
for batch, (x, y) in enumerate(dataloader):
image, y = x.to(device), y.to(device)
output = model(image)
cur_loss = loss_fn(output, y)
_, pred = torch.max(output, axis=1)
cur_acc = torch.sum(y == pred) / output.shape[0]
loss += cur_loss.item()
current += cur_acc.item()
n = n + 1
val_loss = loss / n
val_acc = current / n
print('train_loss' + str(val_loss))
print('train_acc' + str(val_acc))
return val_loss, val_acc
# 定义画图函数
def matplot_loss(train_loss, val_loss):
plt.plot(train_loss, laber = 'train_loss')
plt.plot(val_loss, laber = 'train_val')
plt.legend(loc='best')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.title('训练集和验证集loss值对比图')
plt.show()
def matplot_acc(train_acc, val_acc):
plt.plot(train_acc, laber = 'train_acc')
plt.plot(val_acc, laber = 'val_acc')
plt.legend(loc='best')
plt.ylabel('acc')
plt.xlabel('epoch')
plt.title('训练集和验证集acc值对比图')
plt.show()
# 开始训练
loss_train = []
acc_train = []
loss_val = []
acc_val = []
epoch = 20
min_acc = 0
for t in range(epoch):
lr_scheduler.step()
print(f"epoch{t+1}\n-----------")
train_loss, train_acc = train(train_dataloader, model, loss_fn, optimizer)
val_loss, val_acc = val(val_dataloader, model, loss_fn)
loss_train.append(train_loss)
acc_train.append(train_acc)
loss_val.append(loss_val)
acc_val.append(acc_val)
# 保存最好的模型权重
if val_acc > min_acc:
folder = 'save_model'
if not os.path.exists(folder):
os.mkdir('save_model')
min_acc = val_acc
print(f"save best model, 第{t+1}轮")
torch.save(model.state_dict(), 'save_model/best.pth')
# 保持最后一轮的权重文件
if t == epoch - 1:
torch.save(model.state_dict(), 'save_model/last.pth')
print('Done!')
测试代码
import torch
from net import MyAlexNET
from torch.autograd import Variable
from torchvision import datasets, transforms
from torchvision.transforms import ToTensor
from torchvision.transforms import ToPILImage
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
# 训练测试集
ROOT_TRAIN = r'F:/desktop/myAlexnet/data/train'
ROOT_TEST = r'F:/desktop/myAlexnet/data/val'
# 将图像的像素值归一化到-1——1之间
normalize = transforms.Normalize([0.5, 0.5, 0.5],[0.5, 0.5, 0.5])
train_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.RandomVerticalFlip(),
transforms.ToTensor(),
normalize
])
val_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
])
# 图片加载
train_dataset = ImageFolder(ROOT_TRAIN, transform=train_transform)
val_dataset = ImageFolder(ROOT_TEST, transform=val_transform)
# 数据批次加载
train_dataloader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_dataloader = DataLoader(val_dataset, batch_size=32, shuffle=True)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = MyAlexNET().to(device)
# 加载模型
model.load_state_dict(torch.load("F:/desktop/myAlexnet/save_model/best.pth"))
# 获取预测结果
classes = [
"cat",
"dog",
]
# 将张量转化为照片格式
show = ToPILImage()
# 进入到验证阶段
model.eval()
for i in range(50):
x, y = val_dataset[i][0], val_dataset[i][1]
show(x).show()
x = Variable(torch.unsqueeze(x, dim=0).float(), requires_grad=True).to(device)
x = torch.tensor(x).to(device)
with torch.no_grad():
pred = model(x)
predicted, actual = classes[torch.argmax(pred[0])], classes[y]
print(f'predicted:"{predicted}", Actual:"{actual}"')
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!