一文带你了解大模型的RAG(检索增强生成) | 概念理论介绍+ 代码实操(含源码)
针对大型语言模型效果不好的问题,之前人们主要关注大模型再训练、大模型微调、大模型的Prompt增强,但对于专有、快速更新的数据却并没有较好的解决方法,为此检索增强生成(RAG)的出现,弥合了LLM常识和专有数据之间的差距。
今天给大家分享的这篇文章,将介绍RAG的概念理论,并带大家利用LangChain进行编排,OpenAI语言模型、Weaviate 矢量数据库(也可以自己搭建Milvus向量数据库)来实现简单的 RAG 管道。
什么是RAG?
RAG的全称是Retrieval-Augmented Generation,中文翻译为检索增强生成。它是一个为大模型提供外部知识源的概念,这使它们能够生成准确且符合上下文的答案,同时能够减少模型幻觉。
知识更新问题
最先进的LLM会接受大量的训练数据,将广泛的常识知识存储在神经网络的权重中。然而,当我们在提示大模型生成训练数据之外的知识时,例如最新知识、特定领域知识等,LLM的输出可能会导致事实不准确,这就是我们常说的模型幻觉。如下图所示: 因此,弥合大模型的常识与其它背景知识之间的差距非常重要,以帮助LLM生成更准确和更符合背景的结果,同时减少幻觉。
因此,弥合大模型的常识与其它背景知识之间的差距非常重要,以帮助LLM生成更准确和更符合背景的结果,同时减少幻觉。
技术交流群&本文源码
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
建了技术交流群&星球!想要本文源码、进交流群的同学,可以直接加微信号:mlc2060。加的时候备注一下:研究方向 +学校/公司,即可。然后就可以拉你进群了。
方式①、添加微信号:mlc2060,备注:技术交流
方式②、微信搜索公众号:机器学习社区,后台回复:技术交流


解决方法
传统的解决方法是通过微调神经网络模型来适应特定领域的专有信息。尽管这种技术很有效,但它属于计算密集型的,并且需要技术专业知识,使其难以灵活地适应不断变化的信息。
2020 年Lewis等人,在知识密集型 NLP 任务中,提出了一种更灵活的技术,称为检索增强生成(RAG)[参考论文:https://arxiv.org/abs/2005.11401]。在本文中,研究人员将生成模型与检索器模块相结合,以提供来自外部知识源的附加信息,并且这些信息可以很方便的进行更新维护。
简单来说,RAG 对于LLM来说就像学生的开卷考试一样。在开卷考试中,学生可以携带参考材料,例如课本或笔记,可以用来查找相关信息来回答问题。开卷考试背后的想法是,测试的重点是学生的推理能力,而不是他们记忆特定信息的能力。
同样,事实知识与LLM的推理能力分离,并存储在外部知识源中,可以轻松访问和更新:
-
「参数知识」:在训练期间学习到的知识,隐式存储在神经网络的权重中。
-
「非参数知识」:存储在外部知识源中,例如向量数据库。
一般的 RAG 工作流程如下图所示: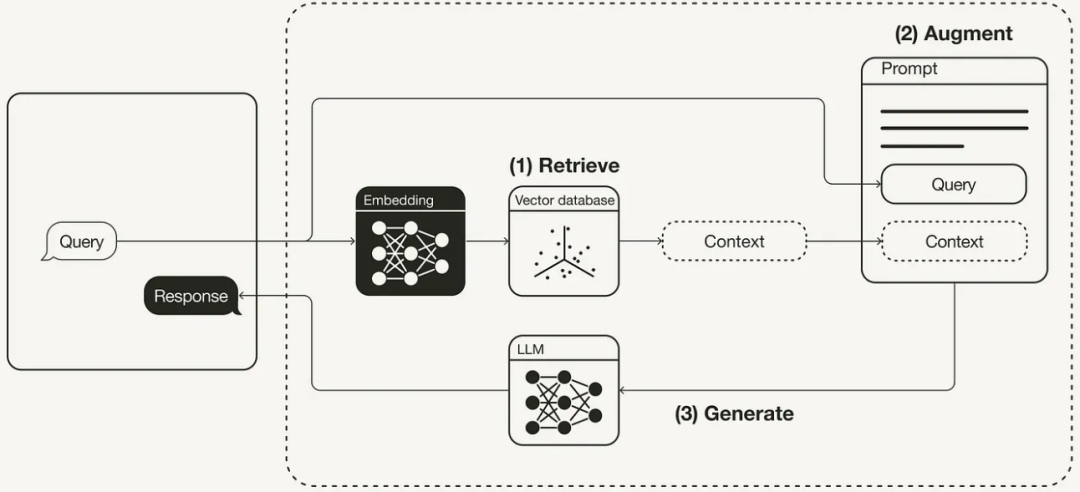
「检索(Retrive)」 根据用户请求从外部知识源检索相关上下文。为此,使用嵌入模型将用户查询嵌入到与向量数据库中的附加上下文相同的向量空间中。这允许执行相似性搜索,并返回矢量数据库中最接近的前 k 个数据对象。
「增强(Augment)」 用户查询和检索到的附加上下文被填充到提示模板中。
「生成(Generate)」 最后,检索增强提示被馈送到 LLM。
LangChain实现RAG
上面介绍了RAG产生和工作原理,接下来将展示如何使用LangChain,结合 OpenAI LLM 、Weaviate 矢量数据库在 Python 中实现 RAG Pipeline。
基础环境准备
1、安装所有需要依赖的相关python包,其中包括用于编排的langchain、大模型接口openai、矢量数据库的客户端 weaviate-client。
pip install langchain openai weaviate-client
2、申请OpenAI的账户,要获取 OpenAI API 密钥,如下图所示: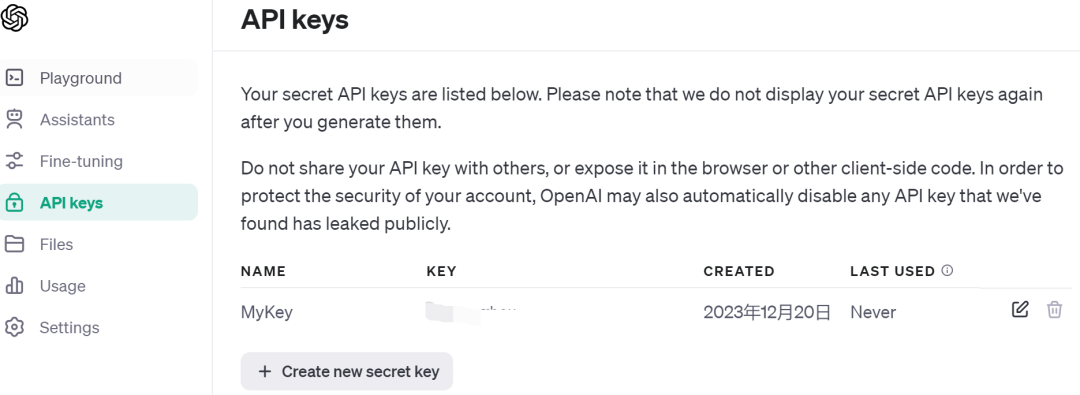
3、在项目根目录创建.env文件,用来存放相关配置文件,如下图所示。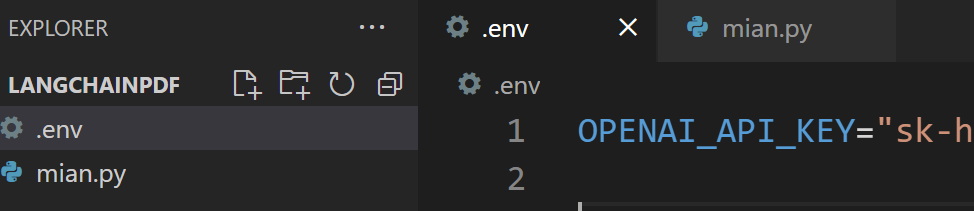 4、在main目录中,加载配置文件信息,这里用到了python-dotenv包。
4、在main目录中,加载配置文件信息,这里用到了python-dotenv包。
向量数据库
接下来,你需要准备一个矢量数据库作为保存所有附加信息的外部知识源。该矢量数据库是通过以下步骤填充的:1)加载数据;2)数据分块;3)数据块存储。
「加载数据」:这里选择了一篇斗破苍穹的小说,作为文档输入 。文档是txt文本,要加载文本这里使用 LangChain 的 TextLoader。
from langchain.document_loaders import TextLoader
loader = TextLoader('./斗破苍穹.txt')
documents = loader.load()
「数据分块」:因为文档在其原始状态下太长(将近5万行),无法放入大模型的上下文窗口,所以需要将其分成更小的部分。LangChain 内置了许多用于文本的分割器。这里使用 chunk_size 约为 1024 且 chunk_overlap 为128 的 CharacterTextSplitter 来保持块之间的文本连续性。
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size=1024, chunk_overlap=128)
chunks = text_splitter.split_documents(documents)
「数据块存储」:要启用跨文本块的语义搜索,需要为每个块生成向量嵌入,然后将它们与其嵌入存储在一起。要生成向量嵌入,可以使用 OpenAI 嵌入模型,并使用 Weaviate 向量数据库来进行存储。通过调用 .from_documents(),矢量数据库会自动填充块。
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Weaviate
import weaviate
from weaviate.embedded import EmbeddedOptions
client = weaviate.Client(
embedded_options = EmbeddedOptions()
)
vectorstore = Weaviate.from_documents(
client = client,
documents = chunks,
embedding = OpenAIEmbeddings(),
by_text = False
)
RAG实现
「第一步:数据检索」 将数据存入矢量数据库后,就可以将其定义为检索器组件,该组件根据用户查询和嵌入块之间的语义相似性获取相关上下文。
retriever = vectorstore.as_retriever()
「第二步:提示增强」 完成数据检索之后,就可以使用相关上下文来增强提示。在这个过程中需要准备一个提示模板。可以通过提示模板轻松自定义提示,如下所示。
from langchain.prompts import ChatPromptTemplate
template = """你是一个问答机器人助手,请使用以下检索到的上下文来回答问题,如果你不知道答案,就说你不知道。问题是:{question},上下文: {context},答案是:
"""
prompt = ChatPromptTemplate.from_template(template)
「第三步:答案生成」 利用 RAG 管道构建一条链,将检索器、提示模板和 LLM 链接在一起。定义了 RAG 链,就可以调用它了。
from langchain.chat_models import ChatOpenAI
from langchain.schema.runnable import RunnablePassthrough
from langchain.schema.output_parser import StrOutputParser
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
query = "萧炎的表妹是谁?"
res=rag_chain.invoke(query)
print(f'答案:{res}')
总的来说,RAG的生成过程如下图所示: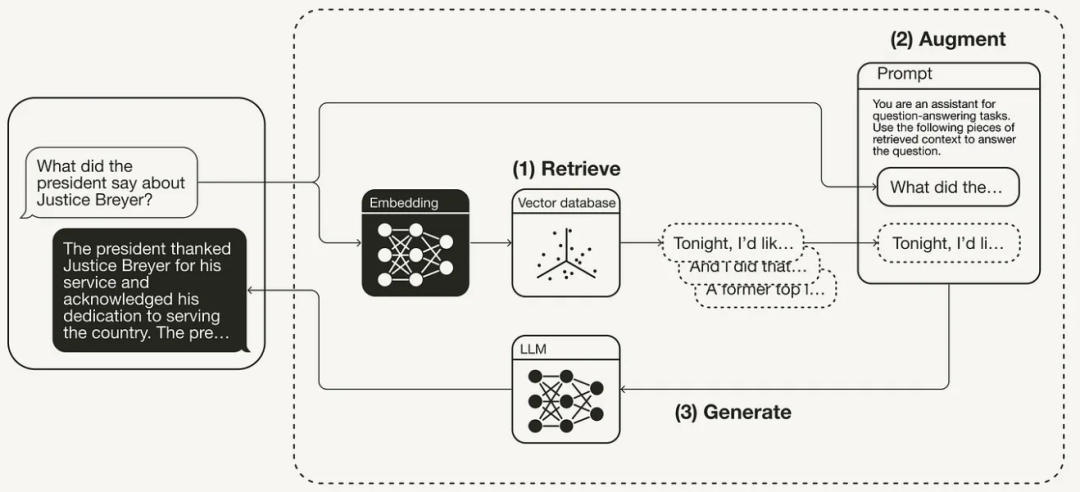
总结
本文介绍了 RAG 的概念及其背后的一些理论,本文通过Python、LangChain将其实现,在此过程中使用了 OpenAI的ChatGPT接口(可以自己搭建chatGLM3)、Weaviate矢量数据库(可以自己搭建Milvus )、OpenAI 嵌入模型实现了 RAG 管道。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!